This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. See the following example with BurnRate formula for Failure rate event.
The Dynatrace platform has been recognized for seamlessly integrating with the Microsoft Sentinel cloud-native security information and event management ( SIEM ) solution. These reports are crucial for tracking changes, compliance, and security-relevant events. Click here to read our full press release.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. million to $5 million annually in increased developer efficiency with our vulnerability and exposure offering alone.
Part of the problem is technologies like cloud computing, microservices, and containerization have added layers of complexity into the mix, making it significantly more challenging to monitor and secure applications efficiently. Learn more about how you can consolidate your IT tools and visibility to drive efficiency and enable your teams.
As an executive, I am always seeking simplicity and efficiency to make sure the architecture of the business is as streamlined as possible. Here are five strategies executives can pursue to reduce tool sprawl, lower costs, and increase operational efficiency. No delays and overhead of reindexing and rehydration.
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines. This awareness allows teams to allocate and scale resources more effectively, reducing costs while ensuring CI/CD pipelines operate smoothly and efficiently.
Chances are, youre a seasoned expert who visualizes meticulously identified key metrics across several sophisticated charts. Seasonal Baseline: Ideal for metrics with predictable seasonal patterns, this option leverages Davis AI to create a confidence band based on historical data, accounting for expected variations.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. What’s behind it all?
With this update, Davis AI can track and alert on KPI threshold violations to assure end-to-end process efficiency and reliability. Each business unit relies on a collection of processes, and each process has metrics and KPIs that can be affected by delays, exceptions, or failures. Average duration. Custom business KPI.
In part 2, we’ll show you how to retrieve business data from a database, analyze that data using dashboards and ad hoc queries, and then use a Davis analyzer to predict metric behavior and detect behavioral anomalies. Dynatrace users typically use extensions to pull technical monitoring data, such as device metrics, into Dynatrace.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams. What is observability?
The data lakehouse unifies the massive volume and variety of observability, security, and business data from cloud-native, hybrid, and multicloud environments while retaining data context to deliver instant, cost-efficient, and precise analytics. Dynatrace AutomationEngine.
Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. User experiences go into many dimensions: business events, dashboards, session replay, synthetic checks which help with performance, reliability, and experience of digital interactions.
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Check out the guide from last year’s event. These are just some of the topics being showcased at Perform 2023 in Las Vegas.
While you’re waiting for the information to come back from the teams, Davis on-demand exploratory analysis can proactively find, gather, and automatically analyze any related metrics, helping get you closer to an answer. The problem report below shows Dynatrace correctly detecting a CPU saturation event on an Ubuntu node.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is RabbitMQ? What is Apache Kafka?
The Dynatrace platform now enables comprehensive data exploration and interactive analytics across data sets (trace, logs, events, and metrics)empowering you to solve complex use cases, handle any observability scenario, and gain unprecedented visibility into your systems.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions.
Unlike a traditional virtual machine-model where customers must build and manage an entire VM, serverless computing provides the ability to purchase only the CPU cycles and memory needed to support an application using an event-based pay-per-use model. To answer the question ‘what is serverless?’
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. This leadership ensures that messages are managed efficiently, providing the fastest fail-over among replicated queue types.
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? Using the source of truth: Logs serve as a reliable source of truth by providing a comprehensive record of system events.
Context-aware and topology-rich logs : Logs must be enriched with metadata and contextual information, allowing powerful log analytics of all distributed traces, metrics, and events within the Kubernetes topology. Easily derive metrics and events from logs for dashboarding and prediction.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
Continuous instrumentation is critical to catching such matters as they emerge, and eBPF, with its hooks into the Linux scheduler with minimal overhead, enabled us to monitor run queue latency efficiently. To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch.
But sometimes you might have a scenario where simple access to log file content is not enough—you need to create a metric for log entries that contain “Error,” for instance, or something more complex like “Error and not Warning.” In such cases, you need the ability to turn log data into custom metrics. That’s it, you’re done!
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. Customers have had a positive response to our native syslog implementation, noting its easy setup and efficiency.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events. Metrics, logs , and traces make up three vital prongs of modern observability. With comprehensive logging support, security, operational efficiency, and application uptime all improve.
Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance. Business events can come from: OneAgent a unique capability offering configurable no-code access to in-flight application payload.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
Logs can include a wide variety of data, including system events, transaction data, user activities, web browser logs, errors, and performance metrics.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
This way, disruptions are minimized, MTTR is significantly decreased, and DevSecOps and SREs collaborate efficiently to boost productivity. Example implementation scenario #1 The diagram below illustrates configuration-event-based remediation with Dynatrace and Red Hat Ansible Automation Controller for a failing canary release.
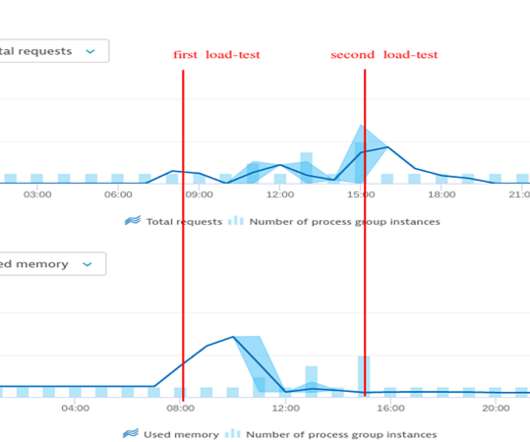
We want to share how Dynatrace helped us identify and fix memory leaks in one of the most central and critical components within Keptn: our event broker. For that reason, we started a simple load-test scenario where we flooded our event-based system with 100 cloud-events per minute. It happened in June 2020. Can we fix it?
Achieving the ideal state with aggregated, centralized log data, metrics, traces , and other metadata is challenging—particularly for multicloud environments. Lining up traces, logs, and metrics based on user events and timestamps provides the most complete picture of full-stack dependencies. Eliminates team silos.
This year, Google’s event will take place from April 9 to 11 in Las Vegas. Visit Dynatrace booth #1141 during the event to explore how its real-time insights and optimization capabilities ensure seamless scalability and performance. Learn more.
The Visual Resolution Path offers a chronological overview of events detected by Dynatrace across all components linked to the underlying issue. Additionally, align the action’s validation window with the timeframe derived from the recently completed test events. Configure an action for the Site Reliability Guardian in the workflow.
The primary goals of these campaigns are to encourage more people to install and play the games, making incremental installs and engagement crucial metrics for evaluating their effectiveness. This causal inference design involves a systematic framework we designed to measure game events that relies on synthetic control ( blogpost ).
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. Load event start. Load event end.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content