This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. See the following example with BurnRate formula for Failure rate event.
Cost optimization: Immediate responses to tag changes lead to informed decisions about scaling, shutting down unused instances, or fine-tuning resource efficiency. Verify event logging Check the EventBridge console to ensure your tag change triggered the appropriate event. Now, let’s get started with the setup!
Event-driven automation enables systems to react instantly to specific triggers or events, enhancing infrastructure resilience and efficiency. A simple and effective method for implementing event-driven automation is through webhooks, which can initiate specific actions in response to events.
These innovations promise to streamline operations, boost efficiency, and offer deeper insights for enterprises using AWS services. Gaining precise insights with Dynatrace integration for AWS EventBridge Now supporting a deeper integration with AWS EventBridge, Dynatrace is able to act as a consumer of AWS events.
Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Business event ingestion and analysis with log files. OpenPipeline: Simplify access and unify business events from anywhere.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Part of the problem is technologies like cloud computing, microservices, and containerization have added layers of complexity into the mix, making it significantly more challenging to monitor and secure applications efficiently. Learn more about how you can consolidate your IT tools and visibility to drive efficiency and enable your teams.
The Dynatrace platform has been recognized for seamlessly integrating with the Microsoft Sentinel cloud-native security information and event management ( SIEM ) solution. These reports are crucial for tracking changes, compliance, and security-relevant events. Click here to read our full press release.
In the world of cloud computing and event-driven applications, efficiency and flexibility are absolute necessities. A smooth flow of messages in an event-driven application is the key to its performance and efficiency. A critical component of such an application is message distribution.
There are three high-level steps to set up the database business-event stream. Step-by-step: Set up a custom MySQL database extension Now we’ll show you step-by-step how to create a custom MySQL database extension for querying and pushing business data to the Dynatrace business events endpoint. Don’t rename the file.
As a company that aims to provide accurate and efficient AI solutions, OpenAI has shared a detailed post-mortem report to transparently discuss what went wrong and how they plan to prevent similar occurrences in the future. This incident impacted API, ChatGPT, and Sora services, resulting in service disruptions that lasted for several hours.
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Check out the guide from last year’s event. These are just some of the topics being showcased at Perform 2023 in Las Vegas.
The problem report below shows Dynatrace correctly detecting a CPU saturation event on an Ubuntu node. You can dramatically and easily improve this problem report using the Dynatrace events API. Dynatrace detected a deployment event that caused a CPU saturation, a problem with an actionable root cause. Click Generate Token.
Adding Dynatrace runtime context to security findings allows smarter prioritization, helps reduce the noise from alerts, and focuses your DevSecOps teams on efficiently remedying the critical issues affecting your production environments and applications.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. What’s behind it all?
Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. They need event-driven automation that not only responds to events and triggers but also analyzes and interprets the context to deliver precise and proactive actions.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Kafka is optimized for high-throughput event streaming , excelling in real-time analytics and large-scale data ingestion. What is RabbitMQ? What is Apache Kafka?
Costs and their origin are transparent, and teams are fully accountable for the efficient usage of cloud resources. Our comprehensive suite of tools ensures that you can extract maximum value from your billing data, efficiently turning insights into action. Figure 4: Set up an anomaly detector for peak cost events.
That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines. This awareness allows teams to allocate and scale resources more effectively, reducing costs while ensuring CI/CD pipelines operate smoothly and efficiently.
Unlike a traditional virtual machine-model where customers must build and manage an entire VM, serverless computing provides the ability to purchase only the CPU cycles and memory needed to support an application using an event-based pay-per-use model. Driving efficiency without sacrificing observability appeared first on Dynatrace blog.
These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system. To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized.
The following example will monitor an end-to-end order flow utilizing business events displayed on a Dynatrace dashboard. Maintaining reliability and scalability requires a good grasp of resource management; predicting future demands helps prevent resource shortages, avoid over-provisioning, and maintain cost efficiency.
This leads to a more efficient and streamlined experience for users. Lastly, monitoring and maintaining system health within a virtual environment, which includes efficient troubleshooting and issue resolution, can pose a significant challenge for IT teams.
This efficient method allows you to easily browse and identify the appropriate metrics; adding them to your notebooks and dashboards requires just a single click. Rather than manually exploring the Kubernetes app you can simply open the Dynatrace global search and enter “Kubernetes network.”
However, not many realize the efficiencies they can gain when data from all customer experience processes – observability, customer behavior, and business data – is in a single place, as it is with the Dynatrace Grail data lakehouse. Additionally, existing customers tend to spend 67% more on average than new customers.
The Dynatrace solution Dynatrace addresses these issues by providing unified security event ingest and analysis for security findings across tools and products. Harbor vulnerability findings and audit logs are fetched periodically and pushed to Dynatrace via a dedicated security event ingest endpoint.
Here’s how Dynatrace can help automate up to 80% of technical tasks required to manage compliance and resilience: Understand the complexity of IT systems in real time Proactively prevent, prioritize, and efficiently manage performance and security incidents Automate manual and routine tasks to increase your productivity 1.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. This leadership ensures that messages are managed efficiently, providing the fastest fail-over among replicated queue types.
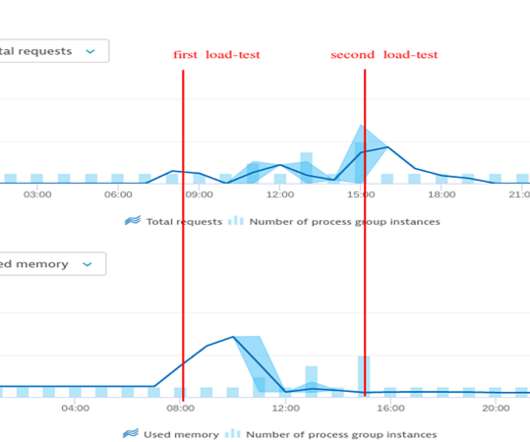
We want to share how Dynatrace helped us identify and fix memory leaks in one of the most central and critical components within Keptn: our event broker. For that reason, we started a simple load-test scenario where we flooded our event-based system with 100 cloud-events per minute. It happened in June 2020. Can we fix it?
This led to a suite of fragmented scripts, runbooks, and ad hoc solutions scattered across teamsan approach that was neither sustainable nor efficient. Using the source of truth: Logs serve as a reliable source of truth by providing a comprehensive record of system events.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
This approach improves operational efficiency and resilience, though its not without flaws. Additionally, predictions based on historical data are reactive, solely relying on past information to anticipate future events, and can’t prevent all new or emerging issues. These algorithms are not limited to monitoring IT environments.
In order to allow for this mimicking, many systems implement an event handling, where they convert our request into a call to the real service with properties enabled to log when titles are filtered out of their response and why. The request schema for the observability endpoint.
This way, disruptions are minimized, MTTR is significantly decreased, and DevSecOps and SREs collaborate efficiently to boost productivity. Example implementation scenario #1 The diagram below illustrates configuration-event-based remediation with Dynatrace and Red Hat Ansible Automation Controller for a failing canary release.
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. Customers have had a positive response to our native syslog implementation, noting its easy setup and efficiency.
Continuous instrumentation is critical to catching such matters as they emerge, and eBPF, with its hooks into the Linux scheduler with minimal overhead, enabled us to monitor run queue latency efficiently. During this event, we generate a timestamp and store it in an eBPF hash map using the process ID as the key.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. For example: {“device_type”: “ios”}.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
Logs can include a wide variety of data, including system events, transaction data, user activities, web browser logs, errors, and performance metrics.
Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance. Business events can come from: OneAgent a unique capability offering configurable no-code access to in-flight application payload.
Scale with confidence: Leverage AI for instant insights and preventive operations Using Dynatrace, Operations, SRE, and DevOps teams can scale efficiently while maintaining software quality and ensuring security and reliability.
In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events. Event logging and software tracing help application developers and operations teams understand what’s happening throughout their application flow and system.
AIOps combines big data and machine learning to automate key IT operations processes, including anomaly detection and identification, event correlation, and root-cause analysis. Improved time management and event prioritization. For example: Greater IT staff efficiency. What is AIOps, and how does it work? Enhanced automation.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content