This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
To get a better idea of OpenTelemetry trends in 2025 and how to get the most out of it in your observability strategy, some of our Dynatrace open-source engineers and advocates picked out the innovations they find most interesting. Second, it enables efficient and effective correlation and comparison of data between various sources.
In dynamic and distributed cloud environments, the process of identifying incidents and understanding the material impact is beyond human ability to manage efficiently. For example, for companies with over 1,000 DevOps engineers, the potential savings are between $3.4 For example, user behavior helps identify attacks or fraud.
As an executive, I am always seeking simplicity and efficiency to make sure the architecture of the business is as streamlined as possible. Here are five strategies executives can pursue to reduce tool sprawl, lower costs, and increase operational efficiency. No delays and overhead of reindexing and rehydration.
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Further, automation has become a core strategy as organizations migrate to and operate in the cloud. What is a data lakehouse?
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. It needs to be engineered properly as a product or service, and it needs automation, observability, and security in itself.”
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. The enriched data is seamlessly accessible for both real-time applications via Kafka and historical analysis through storage in an Apache Iceberg table.
Monitor and optimize business processes with real-time visibility into process KPIs and detailed analytics for each step to improve customer satisfaction, increase operational efficiency, and reduce cost. Reduced storage and query overhead for business use cases. Simplified and enhanced analytics efficiency.
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. And how do DevOps monitoring tools help teams achieve DevOps efficiency? Lost efficiency. 54% reported deploying updates every two hours or less.
This standardization enhances adoption within the personalization stack, simplifies the system, and improves understanding and debuggability for engineers. They must also provide enough information for partner engineers to identify the problem with the underlying service in cases of system-level issues.
MongoDB offers several storageengines that cater to various use cases. The default storageengine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. Choosing the appropriate storageengine can have a significant impact on application performance.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. MezzFS has a number of features, including: Stream objects ?— ?
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
Say hello to advanced trace an alytics and new data storage and capture options. These game-changing features elevate your data interactions, opening up vast possibilities for advanced queries and efficient data management tailored to your needs. This precision reduces storage costs while ensuring you retain the data that matters most.
Additionally, the tight coupling with multiple native database APIs — APIs that continually evolve and sometimes introduce backward-incompatible changes — resulted in org-wide engineering efforts to maintain and optimize our microservice’s data access. Each namespace may use different backends: Cassandra, EVCache, or combinations of multiple.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Greenplum’s high performance eliminates the challenge most RDBMS have scaling to petabtye levels of data, as they are able to scale linearly to efficiently process data. Polymorphic Data Storage. Major Use Cases.
Maintaining Uber’s large-scale data warehouse comes with an operational cost in terms of ETL functions and storage. In our experience, optimizing for operational efficiency requires answering one key question: for which tables does the maintenance cost supersede utility?
The Challenge of Title Launch Observability As engineers, were wired to track system metrics like error rates, latencies, and CPU utilizationbut what about metrics that matter to a titlessuccess? Additionally, the time-sensitive nature of these investigations precludes the use of cold storage, which cannot meet the stringent SLAs required.
For busy site reliability engineers, ensuring system reliability, scalability, and overall health is an imperative that’s getting harder to achieve in ever-expanding, cloud-native, container-based environments. Because of its adaptability, Prometheus has become an essential tool for observability engineering.
Data Engineers of Netflix?—?Interview Interview with Pallavi Phadnis This post is part of our “ Data Engineers of Netflix ” series, where our very own data engineers talk about their journeys to Data Engineering @ Netflix. Pallavi Phadnis is a Senior Software Engineer at Netflix.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. Snowflake is a data warehouse designed to overcome these limitations, and the fundamental mechanism by which it achieves this is the decoupling (disaggregation) of compute and storage. joins) during query processing. Disaggregation (or not).
Progressive rollouts, rollbacks, storage orchestration, bin packing, self-healing, cost efficiency, and access to the Cloud Native Computing Foundation (CNCF) ecosystem carry heavy observability challenges. Such context is easy to understand using the Dynatrace Davis AI engine. Incidents are harder to solve.
Enhanced data security, better data integrity, and efficient access to information. Despite initial investment costs, DBMS presents long-term savings and improved efficiency through automated processes, efficient query optimizations, and scalability, contributing to enhanced decision-making and end-user productivity.
For IT infrastructure managers and site reliability engineers, or SREs , logs provide a treasure trove of data. In most data storage models, indexing engines enable faster access to query logs. But indexing requires schema management and additional storage to be effective, which adds cost and overhead.
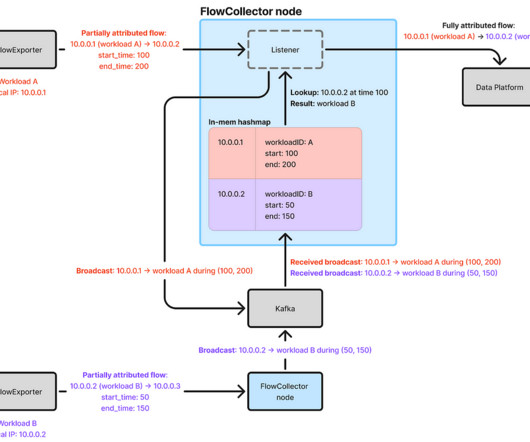
Although more efficient broadcasting implementations exist, the Kafka-based approach is simple and has worked well forus. Because the in-memory state can be quickly rebuilt when a FlowCollector node starts up, no persistent storage is required. With 30 c7i.2xlarge
This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes). This decoupling ensures the openness of data and storage formats, while also preserving data in context. Ingest and process with Grail.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. Customers have had a positive response to our native syslog implementation, noting its easy setup and efficiency.
Thanks to its structured and binary format, Journald is quick and efficient. Dynatrace Grail lets you focus on extracting insights rather than managing complex schemas or index and storage concepts. It offers structured logging, fast indexing for search, access controls, and signed messages.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. ” A data warehouse, on the other hand, is an efficient and fast option for querying data.
Taking a proactive and efficient approach to Kubernetes cluster monitoring can help engineering teams identify and predict many critical problems like CPU outage, memory outage, storage issues well in advance of these issues taking a toll on a business. Introduction.
Anna is not only incredibly fast, it’s incredibly efficient and elastic too: an autoscaling, multi-tier, selectively-replicating cloud service. The issue is that Anna is now orders of magnitude more efficient than competing systems, in addition to being orders of magnitude faster. What's changed ?
a Netflix member via Twitter This is an example of a question our on-call engineers need to answer to help resolve a member issue?—?which We needed to increase engineering productivity via distributed request tracing. That is the first question our engineering teams asked us when integrating the tracer library.
With the right log management and observability platform, IT teams can efficiently identify the root cause of problems during these peak times and maintain three-nines of availability — or 99.98%. Cold storage and rehydration. Cold storage and rehydration. Better-quality code. Inadequate context.
Several pain points have made it difficult for organizations to manage their data efficiently and create actual value. This approach is cumbersome and challenging to operate efficiently at scale. Teams have introduced workarounds to reduce storage costs. Limited data availability constrains value creation.
With the right log management and observability platform, IT teams can efficiently identify the root cause of problems during these peak times and maintain three-nines of availability — or 99.98%. Cold storage and rehydration. Cold storage and rehydration. Better-quality code. Inadequate context.
Predictive AI empowers site reliability engineers (SREs) and DevOps engineers to detect anomalies and irregular patterns in their systems long before they escalate into critical incidents. Through predictive analytics, SREs and DevOps engineers can accurately forecast resource needs based on historical data. Capacity planning.
Data scientists and engineers collect this data from our subscribers and videos, and implement data analytics models to discover customer behaviour with the goal of maximizing user joy. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. This leadership ensures that messages are managed efficiently, providing the fastest fail-over among replicated queue types.
As an engineer, I can work anywhere with a standard laptop as long as I have an IDE and access to Stack Overflow. They could need a GPU when doing graphics-intensive work or extra large storage to handle file management. Where we can gather and analyze the usage data to create efficiencies and automation.
Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances. From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step.
which offers a range of updates: HTTP/2 support: Fluentbit now supports HTTP/2, enabling efficient data transmission with Gzip compression for OpenTelemetry data, enhancing pipeline performance. By default, you have a storage type memory, but you may exceed this buffer limit if you have a lot of data. What’s new in Fluent Bit 3.0
This complexity has surfaced seven top Kubernetes challenges that strain engineering teams and ultimately slow the pace of innovation. Kubernetes enables efficient resource utilization by easily scaling applications and services based on demand. At the same time, it also introduces a large amount of complexity. What is Kubernetes?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content