This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. For example, reporting jobs can process monthly data without running exactly at the end of the month. The post Sustainability: Thoughts from a software engineer appeared first on Dynatrace news.
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Each format has a different production process and different patterns of cash spend, called our Content Forecast. Need to catch up?
Why manual audits and custom scripts fall short for Kubernetes security posture management In the dynamic and complex world of Kubernetes, relying on manual audits, custom scripts, and general-purpose security tools is no longer enough to achieve efficient security posture management. Processes are time-intensive. Reactivity.
A production bug is the worst; besides impacting customer experience, you need special access privileges, making the process far more time-consuming. It also makes the process risky as production servers might be more exposed, leading to the need for real-time production data. This cumbersome process should not be the norm.
Platform engineering is the creation and management of foundational infrastructure and automated processes, incorporating principles like abstraction, automation, and self-service, to empower development teams, optimize resource utilization, ensure security, and foster collaboration for efficient and scalable software development.
To get a better idea of OpenTelemetry trends in 2025 and how to get the most out of it in your observability strategy, some of our Dynatrace open-source engineers and advocates picked out the innovations they find most interesting. Second, it enables efficient and effective correlation and comparison of data between various sources.
A good Kubernetes SLO strategy helps teams manage and make containerized workloads more efficient. However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals.
In response to this shift, platform engineering is growing in popularity. Many consider it an effective solution for improving efficiency and overall satisfaction for developers across a variety of organizations and industries. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments.
In this blog post, we will see how Dynatrace harnesses the power of observability and analytics to tailor a new experience to easily extend to the left, allowing developers to solve issues faster, build more efficient software, and ultimately improve developer experience!
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Further, automation has become a core strategy as organizations migrate to and operate in the cloud. What is a data lakehouse?
Engineers from across the company came together to share best practices on everything from Data Processing Patterns to Building Reliable Data Pipelines. The result was a series of talks which we are now sharing with the rest of the Data Engineering community!
From developers leveraging platform engineering tools to optimize application performance, to Site Reliability Engineers (SREs) ensuring resilience, and executives gaining critical business insights, observability increases the velocity of innovation across every level of an organization.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026. Automation, automation, automation.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” What are DevOps engineer tools and platforms.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Rather, they must be bolstered by additional technological investments to ensure reliability, security, and efficiency. However, these practices cannot stand alone.
I spoke with Martin Spier, PicPay’s VP of Engineering, about the challenges PicPay experienced and the Kubernetes platform engineering strategy his team adopted in response. In addition, their logs-heavy approach to analysis made scaling processes complex and costly. “And these layers tend to be similar. .
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE focuses on automation.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data.
Planned effort Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains: Operations Management (50%) Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. Streamlining the CI/CD process to ensure optimal efficiency.
Dynatrace OpenPipeline is a new stream processing technology that ingests and contextualizes data from any source. Business process monitoring and optimization. All of these steps are critical components of the process, likely to be implemented using different systems. Simplified and enhanced analytics efficiency.
On Episode 52 of the Tech Transforms podcast, Dimitris Perdikou, head of engineering at the UK Home Office , Migration and Borders, joins Carolyn Ford and Mark Senell to discuss the innovative undertakings of one of the largest and most successful cloud platforms in the UK. Make sure to stay connected with our social media pages.
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency? Lost efficiency.
But because of the complexity involved in executing and analyzing test results of dynamic systems, performance engineering is difficult to scale — especially with lean staff or resources. How can organizations address this process bottleneck and run more tests in less time? Current challenges with performance testing.
Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. It needs to be engineered properly as a product or service, and it needs automation, observability, and security in itself.”
Adding Dynatrace runtime context to security findings allows smarter prioritization, helps reduce the noise from alerts, and focuses your DevSecOps teams on efficiently remedying the critical issues affecting your production environments and applications. This increases the number of findings to prioritize.
As a result, requests are uniformly handled, and responses are processed cohesively. This standardization enhances adoption within the personalization stack, simplifies the system, and improves understanding and debuggability for engineers. The request schema for the observability endpoint.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. Platform engineering: Build for self-service Self-service deployment is a key attribute of platform engineering. “It makes them more productive.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. Static Threshold: This approach defines a fixed threshold suitable for well-known processes or when specific threshold values are critical.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Shift-left using an SRE approach means that reliability is baked into each process, app and code change.
Every image you hover over isnt just a visual placeholder; its a critical data point that fuels our sophisticated personalization engine. It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure.
Here’s how Dynatrace can help automate up to 80% of technical tasks required to manage compliance and resilience: Understand the complexity of IT systems in real time Proactively prevent, prioritize, and efficiently manage performance and security incidents Automate manual and routine tasks to increase your productivity 1.
By Abhinaya Shetty , Bharath Mummadisetty At Netflix, our Membership and Finance Data Engineering team harnesses diverse data related to plans, pricing, membership life cycle, and revenue to fuel analytics, power various dashboards, and make data-informed decisions. Let’s dive in! What is late-arriving data? Some techniques we used were: 1.
by Jun He , Yingyi Zhang , and Pawan Dixit Incremental processing is an approach to process new or changed data in workflows. The key advantage is that it only incrementally processes data that are newly added or updated to a dataset, instead of re-processing the complete dataset.
Future blogs will provide deeper dives into each service, sharing insights and lessons learned from this process. The Netflix video processing pipeline went live with the launch of our streaming service in 2007. The Netflix video processing pipeline went live with the launch of our streaming service in 2007.
Organizations are increasingly moving to multicloud environments and adopting microservices to increase the efficiency, reliability, and scalability of their applications and services. First, manual processes are naturally error prone because they rely on humans to input, review, and confirm data.
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Effective site reliability engineering requires enterprise-wide transformation Without a unified understanding of SRE practices, organizational silos can quickly form between departments.
With the evolution of modern applications serving increasing needs for real-time data processing and retrieval, scalability does, too. One such open-source, distributed search and analytics engine is Elasticsearch, which is very efficient at handling data in large sets and high-velocity queries.
Five of the most common include cluster instability, resource and cost management, security, observability, and stress on engineering teams. Engineering teams are overwhelmed with stuff to do.” The post Enhancing Kubernetes cluster management key to platform engineering success appeared first on Dynatrace news.
By Karen Casella, Director of Engineering, Access & Identity Management Have you ever experienced one of the following scenarios while looking for your next role? Interviewing can be a daunting endeavor and how companies, and teams, approach the process varies greatly. If so, we invite you to begin the interview process.
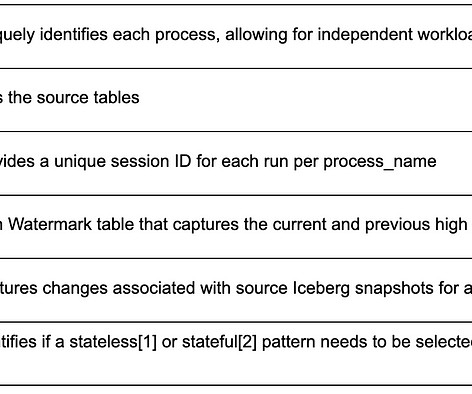
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.
A summary of sessions at the first Data Engineering Open Forum at Netflix on April 18th, 2024 The Data Engineering Open Forum at Netflix on April 18th, 2024. At Netflix, we aspire to entertain the world, and our data engineering teams play a crucial role in this mission by enabling data-driven decision-making at scale.
The impetus for constructing a foundational recommendation model is based on the paradigm shift in natural language processing (NLP) to large language models (LLMs). Key insights from this shiftinclude: A Data-Centric Approach : Shifting focus from model-centric strategies, which heavily rely on feature engineering, to a data-centric one.
In the data-driven landscape of today, automation has become indispensable across industries, not just to maximize efficiency but, more importantly, to ensure quality. This holds true for the critical field of data engineering as well. This comprehensive guide takes an in-depth look at automated testing in the data engineering domain.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content