This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As software pipelines evolve, so do the demands on binary and artifact storage systems. While solutions like Nexus, JFrog Artifactory, and other package managers have served well, they are increasingly showing limitations in scalability, security, flexibility, and vendor lock-in. Enterprises must future-proof their infrastructure with a vendor-neutral solution that includes an abstraction layer , preventing dependency on any one provider and enabling agile innovation.
Dynatrace integrates with AWS Elastic Container Registry (ECR) to enable visibility, orchestration, and prioritization of cross-container-registry vulnerability findings. This integration provides a single pane of glass for container image scans of your containerized applications and is part of a larger effort to enrich vulnerability findings with runtime context.
When it comes to MySQL databases, performance is everything. As more activities move online and data volumes grow exponentially, ensuring efficient data retrieval and query execution becomes crucial. Database indexing plays a significant role in this by providing powerful tools to optimize operations in MySQL.
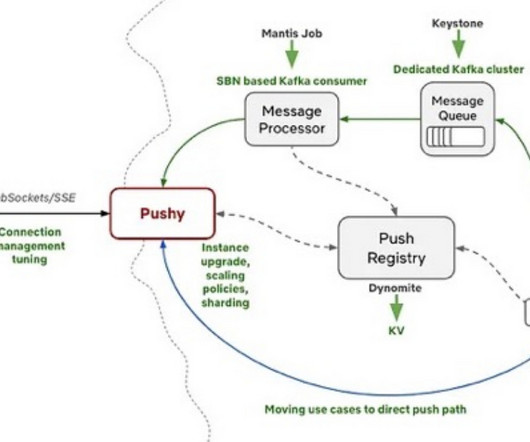
Netflix shared details on the evolution of Pushy, a WebSocket messaging platform that supports push notifications and inter-device communication across many different devices for the company’s products. Netflix’s engineers implemented many improvements across the Pushy ecosystem to ensure the platform's scalability and reliability and support new capabilities.
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Why Use Spring WebFlux? Traditional blocking architectures often struggle to keep up performance, especially under high load.
CRN® , a brand of The Channel Company , has named Isabel Carvalho, Senior Director of the Dynatrace Worldwide Partner Program and Operations, as an honoree on its 100 People You Don’t Know But Should list for 2024. This annual list honors the dedicated, talented people who work behind the scenes in the IT channel to set their company’s partners up for success.
In this blog post, we will explore how network partitions impact group replication and the way it detects and responds to failures. In case you haven’t checked out my previous blog post about group replication recovery strategies, please have a look at them for some insight.
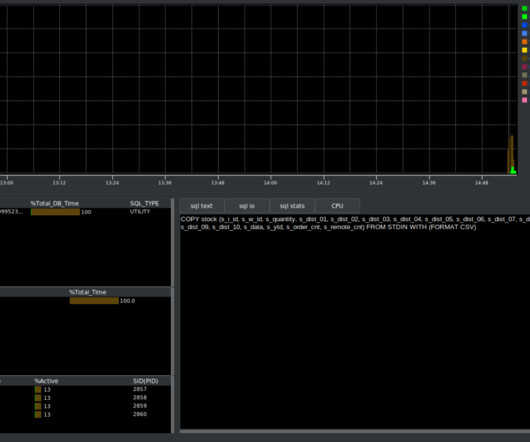
In this post, we will look at the findings of a blog post by EnterpriseDB analyzing a HammerDB workload against PostgreSQL using Postgres Workload reports. We will provide a brief summary of the article and its conclusions, and demonstrate a better way to analyze PostgreSQL performance with HammerDB itself. We will then highlight the errors that have been made in the EnterpriseDB article and the reasons why.
Sign up to get articles personalized to your interests!
Technology Performance Pulse brings together the best content for technology performance professionals from the widest variety of industry thought leaders.
In this post, we will look at the findings of a blog post by EnterpriseDB analyzing a HammerDB workload against PostgreSQL using Postgres Workload reports. We will provide a brief summary of the article and its conclusions, and demonstrate a better way to analyze PostgreSQL performance with HammerDB itself. We will then highlight the errors that have been made in the EnterpriseDB article and the reasons why.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented. On top of that, the data sources are inconsistent. While some data comes from modern systems with APIs, other data stems from older systems that generate log files, and some data originates from external vendor
Recently, one of our customers reported a problem after upgrading a sharded cluster from MongoDB 5.0 to 6.0. The upgrade of data-bearing nodes was fine, but in the final part of the process, where mongos routers needed to be restarted, the new version did not go well.
The cost of downtime is only increasing, not just for manufacturers but for everyone. Big manufacturers lose a staggering $1 trillion a year to machine failure. With global manufacturers still struggling to regain their post-COVID momentum , there’s a real need on the part of manufacturers to find ways to reduce spending. Preventive maintenance, also known as preventative and predictive maintenance – including preventive maintenance software and preventive maintenance tools – is one readily evol
Gartner predicts by 2028, 50% of enterprises will utilize the cloud. The growth has also seen an increase in different strategies for organizations to use the cloud. Initially, organizations were completely on-prem, then they were hybrid where some workloads were still on-prem but some were migrated to the cloud. Eventually, companies started moving to multi-cloud where they use more than one cloud provider to host their workloads.
We have released Dynatrace version 1.301. To learn what’s new, have a look at the release notes. The post Dynatrace SaaS release notes version 1.301 appeared first on Dynatrace news.
Deep dive into NVIDIA Blackwell Benchmarkswhere does the 4x training and 30x inference performance gain, and 25x reduction in energy usage comefrom? The prototype NVL-72 water cooled rack on the show floor at GTC24picture byAdrian Ive been trying to write this blog post since the announcements at GTC, and was planning to publish it as a story for The New Stack, but I keep getting stuck on things that dont make sense to me, so Im going to put it out there as it is on Medium, and if I get any feed
Why Predictive Maintenance Requires Real-Time Decisioning The cost of downtime is only increasing, not just for manufacturers but for everyone. Big manufacturers lose a staggering $1 trillion a year to machine failure. With global manufacturers still struggling to regain their post-COVID momentum , there’s a real need on the part of manufacturers to find ways to reduce spending.
Anton Alputov , the DevOps architect of Valletta Software Development, shared his DevOps expertise both with me and with the readers. Deploying software updates can often feel like walking a tightrope — one wrong step, and you risk downtime, bugs, or a frustrating user experience. Traditional deployment methods tend to amplify these risks, leaving teams scrambling to mitigate issues post-release.
As batch jobs run without user interactions, failure or delays in processing them can result in disruptions to critical operations, missed deadlines, and an accumulation of unprocessed tasks, significantly impacting overall system efficiency and business outcomes. The urgency of monitoring these batch jobs can’t be overstated. Monitor batch jobs Monitoring is critical for batch jobs because it ensures that essential tasks, such as data processing and system maintenance, are completed on ti
The promise of differential privacy is compelling. It offers a rigorous, provable guarantee of individual privacy, even in the face of arbitrary background knowledge. Rather than relying on anonymization techniques that can often be defeated, differential privacy works by injecting carefully calibrated noise into computations. This allows aggregate statistics and insights to be extracted from data while masking the contributions of any single individual.
This blog post explores how customers and partners benefit from the Dynatrace platform’s openness and extensibility. We’ll further learn how Omnilogy developed a custom Pipeline Observability Solution on top of Dynatrace and gain insights into their thought process throughout the journey. The impact of limited visibility in CI/CD pipelines The journey for Omnilogy started when a customer explained that they needed a way to monitor and improve the performance of their CI/CD pipelines with Dynatra
The 2024 Magic Quadrant™ for Observability Platforms Report has been recently published by Gartner® recognizing Dynatrace as a Leader for the 14th consecutive time. This year, Dynatrace was positioned furthest for Completeness of Vision and highest for Ability to Execute. Additionally, Dynatrace ranked first in three of five Use Cases in the 2024 Gartner Critical Capabilities for Observability Platforms.
Are you ready to start your journey on the road to collecting telemetry data from your applications? Great observability begins with great instrumentation! In this series, you'll explore how to adopt OpenTelemetry (OTel) and how to instrument an application to collect tracing telemetry. You'll learn how to leverage out-of-the-box automatic instrumentation tools and understand when it's necessary to explore more advanced manual instrumentation for your applications.
In today's data-driven world, organizations increasingly rely on sophisticated data pipelines to manage vast volumes of data generated daily. A data pipeline is more than just a conduit for data — it is a complex system that involves the extraction, transformation, and loading ( ETL ) of data from various sources to ensure that it is clean, consistent, and ready for analysis.
Differential Privacy (DP) is a mathematical framework that protects individual privacy in data analysis while allowing useful insights to be extracted. It works by adding carefully calibrated noise to data or query results, ensuring that including or excluding any single individual's data doesn't significantly change the analysis outcomes.
Carbon Impact leverages business events , a special data type designed to support the real-time accuracy and long-term granularity demands common to business use cases. For Carbon Impact, these business events come from an automation workflow that translates host utilization metrics into energy consumption in watt hours (Wh) and into greenhouse gas emissions in carbon dioxide equivalent (CO2e).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content