This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The growing challenge in modern IT environments is the exponential increase in log telemetry data, driven by the expansion of cloud-native, geographically distributed, container- and microservice-based architectures. Organizations need a more proactive approach to log management to tame this proliferation of cloud data. By following key log analytics and log management best practices, teams can get more business value from their data.
The Initial Need Leading to CQRS The traditional CRUD (Create, Read, Update, Delete) pattern has been a mainstay in system architectures for many years. In CRUD, reading and writing operations are usually handled by the same data model and often by the same database schema. While this approach is straightforward and intuitive, it becomes less effective as systems scale and as requirements become more complex.
Democratizing Stream Processing @ Netflix By Guil Pires , Mark Cho , Mingliang Liu , Sujay Jain Data powers much of what we do at Netflix. On the Data Platform team, we build the infrastructure used across the company to process data at scale. In our last blog post, we introduced “Data Mesh” — A Data Movement and Processing Platform. When a user wants to leverage Data Mesh to move and transform data, they start by creating a new Data Mesh pipeline.
Hello friends, In Managed Services , we have the opportunity to see different technologies and various topologies, which makes the work fascinating and challenging at the same time. This time, I’m going to tell you about a particular case: a client with a dual-primary topology plus a replica, as detailed below: PS-primary-1=192.168.0.14 [RW] | PS-primary-2=192.168.0.59 [RW] (Slave_delay: 0) | PS-replica-1=192.168.0.99 [R] (Slave_delay: 0) [RW] means Read/Write access.
What’s happening In our pursuit of continuous improvement, we’re bidding farewell to the Extension Framework 1.0 and focusing on a much-improved version 2.0 that offers security, scalability, and simplicity of use. Extensions 2.0 already address SNMP, WMI, SQL databases, and Prometheus technologies, serving the monitoring needs of hundreds of Dynatrace customers.
When a user logs on to this desktop/laptop or mobile, opens a browser, and types the name of a website, the browser displays the required information, and the user performs an action on the site. Have you ever wondered how computers retrieve this information and what happens in the background? It’s an underlying web application architecture that makes this process possible.
Answering Common Questions About Interpreting Page Speed Reports Answering Common Questions About Interpreting Page Speed Reports Geoff Graham 2023-10-31T16:00:00+00:00 2023-10-31T17:06:18+00:00 This article is sponsored by DebugBear Running a performance check on your site isn’t too terribly difficult. It may even be something you do regularly with Lighthouse in Chrome DevTools, where testing is freely available and produces a very attractive-looking report.
Sometimes, there is a need to update the table and index statistics manually using the ANALYZE TABLE command. Without going further into the reasons for such a need, I wanted to refresh this subject in terms of overhead related to running the command on production systems. However, the overhead discussed here is unrelated to the usual cost of diving into table rows to gather statistics, which we can control by setting the number of sample pages.
Sign up to get articles personalized to your interests!
Technology Performance Pulse brings together the best content for technology performance professionals from the widest variety of industry thought leaders.
Sometimes, there is a need to update the table and index statistics manually using the ANALYZE TABLE command. Without going further into the reasons for such a need, I wanted to refresh this subject in terms of overhead related to running the command on production systems. However, the overhead discussed here is unrelated to the usual cost of diving into table rows to gather statistics, which we can control by setting the number of sample pages.
With growing multicloud complexity and the need for organization-wide scalability, self-service and automation capabilities have become increasingly essential for developer productivity. In response to this shift, platform engineering is growing in popularity. Many consider it an effective solution for improving efficiency and overall satisfaction for developers across a variety of organizations and industries.
In the world of distributed systems, the likelihood of components failing or becoming unresponsive is higher compared to monolithic systems. Given the interdependence of microservices or modules in a distributed setup, the failure of one component can lead to cascading failures throughout the system, potentially causing the entire system to malfunction or shut down.
DoorDash rearchitected the heterogeneous caching system they were using across all of their microservices and created a common, multi-layered cache providing a generic mechanism and solving a number of issues coming from the adoption of a fragmented cache.
When it comes to Citus, successfully building out and scaling a PostgreSQL cluster across multiple nodes and even across data centers can feel, at times, to be an art form because there are so many ways of building it out. There’s an axiom that I think aptly applies to this situation describing the differences between science and art: – Science: 1 problem -> 1 solution – Art: 1 problem -> 1,000 solutions While the two previous Citus blogs that I wrote covered the fairly
A key objective of the Australian Prudential Regulation Authority ( APRA ) is to ensure that APRA-regulated organisations remain resilient to operational risk. APRA outlines the measures that banks, mortgage lenders, and insurance organisations should take to keep critical promises to depositors, policyholders, and superannuation fund members. Those promises include ensuring continuous service and safeguarding personal information.
The service mesh has become popular lately, and many organizations seem to jump on the bandwagon. Promising enhanced observability, seamless microservice management, and impeccable communication, service mesh has become the talk of the town. But before you join the frenzy, it’s crucial to pause and reflect on whether your specific use case truly demands the adoption of a service mesh.
Digging deeper into the architecture of an open source product Recently, Percona team announced the public alpha version of a new open source product – Percona Everest. It allows you to create database clusters on Kubernetes cluster. I have installed Percona Everest several times and tried its features. Standard installation is very simple and takes a few minutes.
Ready to supercharge your MongoDB experience? MongoDB is a dynamic database system continually evolving to deliver optimized performance, robust security, and limitless scalability. Upgrading to the newest release of MongoDB is the key to unlocking its full potential, but it’s not as simple as clicking a button; it requires meticulous planning, precise execution, and a deep understanding of the upgrade process.
Digital transformation continues surging forward. Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. With higher demand for innovation, IT teams are working diligently to release high-quality software faster. But this task has become challenging.
Prometheus and Grafana are two big names in the open-source world of observability. Both are widely liked and used, with vibrant, opinionated communities, and they routinely build on top of each other. So, how do Prometheus and Grafan stack up against each other?
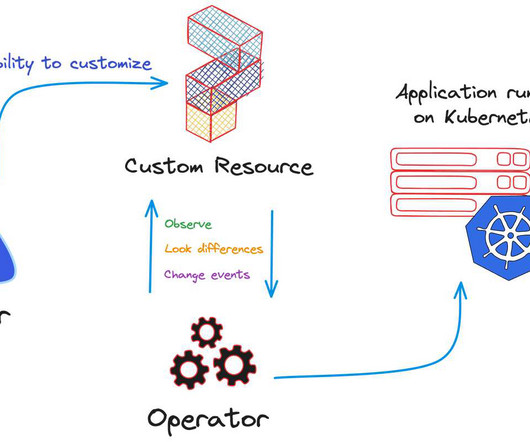
The concept of Kubernetes Operators was introduced around 2016 by the CoreOS Linuxdevelopment team. They were in search of a solution to improve automated container management within Kubernetes, primarily with the goal of incorporating operational expertise directly into the software. According to the Cloud Native Computing Foundation, “Operators are software extensions that use custom resources to manage applications and their components”.
Percona has a mission to provide the best open source database software, support, and services so our users can innovate freely. We are proud of how far we have come over the last 16+ years. Continuing this trajectory into the future improvements in the development of our software products will require many decisions. Our hope is to make these decisions with as much useful data as possible.
The White House recently released the “Delivering a Digital-First Public Experience” memorandum, which seeks to transform the way the government interacts online with citizens. Accomplishing this goal involves ensuring digital services are “easy to use, trustworthy, and accessible.” Much of the memo focuses on the customer experience (CX). The memo directs agencies to conduct qualitative and quantitative research to better understand online interactions.
Turbocharge Your Content Delivery With CDN Multiple Origins Load Balancer! With the ever-growing demands of the internet, websites and web applications face the challenge of delivering content swiftly and efficiently to users worldwide. Enter the concept of Content Delivery Networks (CDN) with Multiple Origins Load Balancing. â€Just as a well-coordinated airport directs flights to multiple runways based on traffic and weather conditions, a CDN with Multiple Origins Load Balancing ensures that
This time of year, everyone publishes predictions. They’re fun, but I don’t find them a good source of insight into what’s happening in technology. Instead of predictions, I’d prefer to look at questions: what are the questions to which I’d like answers as 2023 draws to a close? What are the unknowns that will shape 2024? That’s what I’d really like to know.
Sure, database migration is complex, particularly when you’re looking to migrate from a proprietary database to an open source one. But you’re probably confident you and your team can handle it — and you’re probably right! But just because you can do something doesn’t mean that it’s in your best interest to do so.
Digital transformation has significantly increased the organizational demand to innovate faster. But with many organizations relying on traditional, manual processes to ensure service reliability and code quality, software delivery speed suffers. As a result, organizations are investing in DevOps automation to meet the need for faster, more reliable innovation.
Remember when we could stream without thinking about optimizations? Those days are long gone. Now, with viewers all over the world expecting flawless and high-definition streaming, video providers have their work cut out for them. They need to deliver impeccable performance without breaking the bank.According to recent industry statistics, global streaming has seen an uptick of 30% in the past year, underscoring the importance of efficient CDN architecture strategies.
Disclaimer: Based on the announcement of the EO , without having seen the full text. While I am heartened to hear that the Executive Order on AI uses the Defense Production Act to compel disclosure of various data from the development of large AI models, these disclosures do not go far enough. The EO seems to be requiring only data on the procedures and results of “Red Teaming” (i.e. adversarial testing to determine a model’s flaws and weak points), and not a wider range of inf
On October 24th, the Percona Kubernetes Squad held the first Ask-me-Anything (AMA) session to address inquiries regarding the utilization of Kubernetes for database deployment. This blog post will outline the top three questions raised during the session and provide thorough responses from our team of experts. Q1: When is it appropriate to use Kubernetes for databases, and when is it not recommended?
Spiraling cloud architecture and application costs have driven the need for new approaches to cloud spend. Nearly half (49%) of organizations believe their cloud bill is too high , according to a CloudZero survey. Further, a Flexera report found that small to medium-sized businesses spend approximately $1.2 million on cloud computing , while large enterprises shell out upward of $12 million annually.
What To Expect With CDN Security CDNs hold a lot of data and can be a target for hackers. These hackers can exploit weak security in CDNs. This is solely the responsibility of CDNs and doesn't involve CDN clients or security add-ons CDN provides.To address these threats, CDN providers can implement several practices aimed at safeguarding their customers' data, which we will delve into shortly.When choosing your CDN vendor(s), it’s important to ask them the right questions to ensure they are i
Imagine spending nearly 100 hours on every vulnerability remediation issue. For many teams, this isn’t something they have to imagine—it’s something they experience regularly. For one major European financial services company, this was their reality prior to adopting Dynatrace Application Security. The impact on their staff and bottom line was the wake-up call they needed to adapt their security approach.
We have released Dynatrace Managed version 1.278. To learn what’s new, have a look at the release notes. The post Dynatrace Managed release notes version 1.278 appeared first on Dynatrace news.
The cybersecurity talent shortfall is real and not going away anytime soon. There are now 3.5 million global vacancies for the profession, up from 1 million vacancies ten years ago. In attempting to address this difficult workforce challenge, chief information security officers (CISOs) are considering automation and artificial intelligence (AI) defense tools as a cost-effective, highly efficient option.
Runtime security vulnerabilities, if discovered in a customer-facing product environment, are far more costly to an organization than if they’re caught in earlier stages of development. Impacts of runtime vulnerabilities range from lost revenue to lost customers, among other things. Additionally, the measures organizations need to take to remediate a vulnerability or attack in a production environment often takes a toll on the teams left searching for where the vulnerabilities are and how to blo
Namespaces in Kubernetes provide a way to isolate groups of resources within a single cluster. They are useful in multi-tenant environments with a few to tens of users and teams. They also allow dividing cluster resources between these users through quotas. Percona Operators come with cluster-wide and namespace-scope deployments. When you have a multi-namespace Kubernetes cluster, it poses a question of which way to use it.
Percona is a leading provider of unbiased, performance-first, open source database solutions that allow organizations to easily, securely, and affordably maintain business agility, minimize risks, and stay competitive, free from vendor lock-in. Percona software is designed for peak performance, uncompromised security, limitless scalability, and disaster-proofed availability.
This blog was originally published in Sept 2021 and was updated in November 2023. Following the series of blogs started by Peter Zaitsev in Installing MySQL with Docker , on deploying Docker containers running open source databases, in this article, I’ll demonstrate how to install and run PostgreSQL using Docker. Before proceeding, it is important to remind you of Peter’s warning from his article, which applies here as well: “The following instructions are designed to get a tes
This blog was originally published in January 2021 and updated in November of 2023. As businesses and applications increasingly rely on MySQL databases to manage their critical data, ensuring data reliability and availability becomes paramount. In this age of digital information, robust backup and recovery strategies are the pillars on which the stability of applications stands.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content