This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the ever-evolving landscape of technology, the tandem growth of Artificial Intelligence (AI) and Data Science has emerged as a beacon of hope, promising unparalleled advancements that will significantly impact and enhance various aspects of our lives. As we stand on the cusp of a new era, it is crucial to explore how the integration of AI and Data Science is poised to shape the future and offer solutions to some of humanity's most pressing challenges.
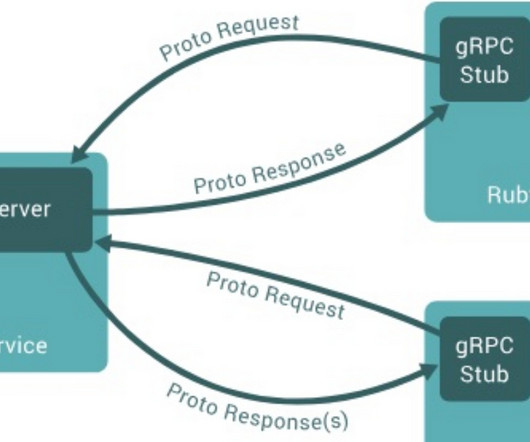
LinkedIn announced that it would be moving to gRPC with Protocol Buffers for the inter-service communication in its microservices platform, where previously an open-source Rest.li framework was used with JSON as a primary serialization format. InfoQ contacted Karthik Ramgopal and Min Chen to learn more about the decision and company motivations behind it.
This PoC demonstrates how to install and configure pg_stat_monitor in order to extract useful and actionable metrics from a PostgreSQL database and display them on a Grafana dashboard. About the environment Grafana: version 10.0.0 Grafana database backend: Prometheus version 2.15.2+d PostgreSQL version 13 pgbench version 13 In order to investigate the potential opportunities for implementing constructive and useful metrics derived from PostgreSQL into Grafana , it is necessary to generate loadin
Managing vast datasets effectively is an essential requirement for modern applications, and MongoDB , a leading NoSQL database, offers robust solutions for this requirement. One such solution is pagination, which divides large datasets into manageable “pages” of data to be displayed or processed. But how does MongoDB handle pagination, and how can you optimize it for better performance?
Resilience refers to the ability to withstand, recover from, or adapt to challenges, changes, or disruptions. As organizations increasingly embrace the microservices approach, the need for a resilient testing framework becomes important for the reliability, scalability , and security of these distributed systems. MRTF is a collaborative, anticipatory, and holistic approach that brings together developers, quality assurance professionals, operations teams, and user experience designers.
Zendesk reduced its data storage costs by over 80% by migrating from DynamoDB to a tiered storage solution using MySQL and S3. The company considered different storage technologies and decided to combine the relational database and the object store to strike a balance between querybility and scalability while keeping the costs down.
We’re happy to introduce Audit Log Filter — our newly upgraded audit plugin. Its functionality has been significantly improved in comparison to Audit Log and currently mirrors the functionality of the MySQL Enterprise Audit plugin. Starting with Percona Server for MySQL 8.0.34-26 , the Audit Log Filter is available in a technical preview mode.
The excellent Megapari app that the betting operator offers for Indian gamers has been created specifically for quality online entertainment betting. It can be used anytime and anywhere in India and is perfectly adapted to different devices. It can only be downloaded from the official Megapari website and was last updated in December 2023. Such Megapari app does not take more than usual, the main thing is that you have a stable internet.
Sign up to get articles personalized to your interests!
Technology Performance Pulse brings together the best content for technology performance professionals from the widest variety of industry thought leaders.
The excellent Megapari app that the betting operator offers for Indian gamers has been created specifically for quality online entertainment betting. It can be used anytime and anywhere in India and is perfectly adapted to different devices. It can only be downloaded from the official Megapari website and was last updated in December 2023. Such Megapari app does not take more than usual, the main thing is that you have a stable internet.
Murphy's Law ( "Anything that can go wrong will go wrong and at the worst possible time." ) is a well-known adage, especially in engineering circles. However, its implications are often misunderstood, especially by the general public. It's not just about the universe conspiring against our systems; it's about recognizing and preparing for potential failures.
Cloud migration is primarily motivated by scalability, flexibility, and cost savings. It allows businesses to create, deliver, and manage software applications while significantly transforming infrastructure, security, and enterprise services. Gartner predicts that companies will invest a remarkable $679 billion in cloud services by 2024. Additionally, the cloud is expected to become an indispensable aspect of business operations by 2028.
Optimizing I/O workloads in Python typically involves understanding where the bottlenecks are and then applying strategies to reduce or manage these bottlenecks. Profiling is a crucial step in this process as it helps identify the parts of the code that are most resource-intensive. Here's a step-by-step guide to optimizing I/O workloads by profiling in Python: Identify the I/O Workloads Comprehending the type of your I/O workloads is essential as a first step.
Here I am going to show the power of SQL Loader + Unix Script utility where multiple data files can be loaded by the SQL loader with automated shell scripts. This would be useful while dealing with large chunks of data and when data needs to be moved from one system to another system. It would be suitable for a migration project where large historical data is involved.
The telecommunications industry has become an indispensable part of our interconnected society, fueling various functions ranging from traditional calls to lightning-fast Internet and the ever-expanding Internet of Things ( IoT ). With the constant evolution of this sector, the dynamic duo of AI and ML is revolutionizing the telecommunications industry, propelling it towards greater network efficiency, unparalleled customer service, and fortified security measures.
Welcome to the first post in our exciting series on mastering offline data pipeline's best practices, focusing on the potent combination of Apache Airflow and data processing engines like Hive and Spark. This post focuses on elevating our data engineering game, streamlining your data workflows, and significantly cutting computing costs. The need to optimize offline data pipeline optimization has become a necessity with the growing complexity and scale of modern data pipelines.
The evolution of cloud-native technology has been nothing short of revolutionary. As we step into 2024, the cornerstone of cloud-native technology, Kubernetes, will turn ten years old. It continues to solidify its position and is anticipated to reach USD 5575.67 million by 2028, with a forecasted Compound Annual Growth Rate (CAGR) of 18.51% in the coming years, as reported by Industry Research Biz.
PostgreSQL 14 introduced the parameter idle_session_timeout , and, unfortunately, many DBAs jumped to start using it without understanding or by ignoring the consequences. In a short span of time, it has become one of the most misused parameters in many PostgreSQL installations. There is nothing wrong with idle_session_timeout from a technical perspective; even without this parameter, I know frustrated DBAs run scheduled shell scripts to keep terminating old idle sessions.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content