This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Efficient data processing is crucial for businesses and organizations that rely on big data analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data. This article explores the impact of different storage formats, specifically Parquet, Avro, and ORC on query performance and costs in big data environments on Google Cloud Platform (GCP).
We have released Dynatrace OneAgent and ActiveGate version 1.299. To learn what’s new, have a look at: OneAgent release notes ActiveGate release notes The post OneAgent release notes version 1.299 appeared first on Dynatrace news.
By Jose Fernandez , Sebastien Dabdoub , Jason Koch , Artem Tkachuk The Compute and Performance Engineering teams at Netflix regularly investigate performance issues in our multi-tenant environment. The first step is determining whether the problem originates from the application or the underlying infrastructure. One issue that often complicates this process is the "noisy neighbor" problem.
At ScaleGrid, we’re always pushing the boundaries to offer more flexibility and scalability to our customers. Over the past few months, our releases have introduced several exciting updates, with a strong focus on geography and cloud expansion. Here’s what you need to know: AWS Outposts & Philadelphia Local Zone Support Our customers asked, and we listened.
Regarding contemporary software architecture, distributed systems have been widely recognized for quite some time as the foundation for applications with high availability, scalability, and reliability goals. When systems shifted from a centralized structure, it became increasingly important to focus on the components and architectures that support a distributed structure.
We have released Dynatrace version 1.300. To learn what’s new, have a look at the release notes. The post Dynatrace SaaS release notes version 1.300 appeared first on Dynatrace news.
By Karthik Yagna , Baskar Odayarkoil , and Alex Ellis Pushy is Netflix’s WebSocket server that maintains persistent WebSocket connections with devices running the Netflix application. This allows data to be sent to the device from backend services on demand, without the need for continually polling requests from the device. Over the last few years, Pushy has seen tremendous growth, evolving from its role as a best-effort message delivery service to be an integral part of the Netflix ecosystem.
This long article aims to provide you with the instructions and tools to migrate your production database from your current environment to a solution based on Percona Everest (MySQL). Nice. You decided to test Percona Everest and found that it is the tool you were looking for to manage your private DBaaS.
Sign up to get articles personalized to your interests!
Technology Performance Pulse brings together the best content for technology performance professionals from the widest variety of industry thought leaders.
This long article aims to provide you with the instructions and tools to migrate your production database from your current environment to a solution based on Percona Everest (MySQL). Nice. You decided to test Percona Everest and found that it is the tool you were looking for to manage your private DBaaS.
Logging is one of the most important parts of the distributed systems. Many things can break, but when the logging breaks, then we are completely lost. In this blog post, we will understand log levels and how to log efficiently in distributed systems. Logging Levels Whenever we log a message, we need to specify the log level or log severity. It’s an indicator of how important the message is and who should be concerned.
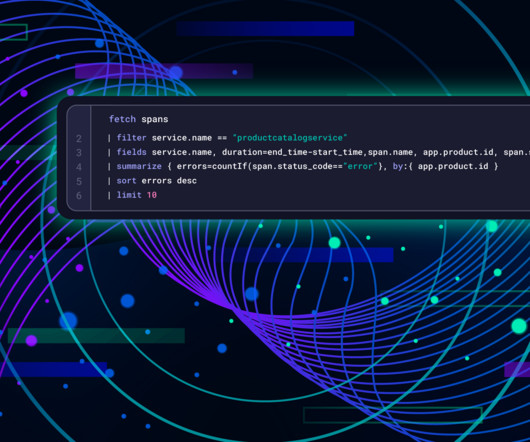
Dynatrace Dashboards provide a clear view of the health of the OpenTelemetry Demo application by utilizing data from the OpenTelemetry collector. With these dashboards, you can monitor your application’s usage and performance and identify potential issues like increasing failure rates. Learn how to use the Dynatrace Query Language (DQL) to investigate and pinpoint bottlenecks within your application’s distributed traces.
PSA: Today’s the day that Google’s performance tools officially stops supporting the First Input Delay (FID) metric that was replaced by Interaction to Next Paint (INP). Quick Hit #18 originally published on CSS-Tricks , which is part of the DigitalOcean family. You should get the newsletter.
The release of Percona Server for MySQL 8.4.0 includes the new UUID_VX component, which implements UUID versions 1, 3, 4, 5, 6, and 7 according to recently published RFC 9562. UUIDs (Universally Unique Identifiers) are unique identifiers that can be generated independently without a central authority or coordination with other parties.
Efficient data synchronization is crucial in high-performance computing and multi-threaded applications. This article explores an optimization technique for scenarios where frequent writes to a container occur in a multi-threaded environment. We’ll examine the challenges of traditional synchronization methods and present an advanced approach that significantly improves performance for write-heavy environments.
A recent article in Computerworld argued that the output from generative AI systems, like GPT and Gemini, isn’t as good as it used to be. It isn’t the first time I’ve heard this complaint, though I don’t know how widely held that opinion is. But I wonder: is it correct? And why? I think a few things are happening in the AI world. First, developers of AI systems are trying to improve the output of their systems.
Percona Monitoring and Management 2.43.0 Tech Preview Release Hello everyone! Percona Monitoring and Management (PMM) 2.43.0 is now available as a Tech Preview Release. We encourage you to try this PMM preview release in testing environments only, as these packages and images are not fully production-ready. The final version is expected to be released through the standard channels in the coming week.
Managing database users within complex CICD pipelines and GitOps workflows has long been a challenge for MongoDB deployments. With Percona Operator for MongoDB 1.17, we introduce a new feature, currently in technical preview, that streamlines this process.
When reporting summary statistics for performance test results, there's a common assumption that the data follows a central tendency. But is this always true? What if the data does not exhibit a single central tendency? In such cases, the traditional metrics like averages might be misleading. This article explores why it's crucial to check for modality of performance test results, how to detect multimodal distributions, and how to handle them.
Discover the essentials of benchmark software testing and how it enhances software quality. This guide will help you to get the most out of your software. The post Benchmark Software Testing Unveiled appeared first on Blog about Software Development, Testing, and AI | Abstracta.
Industrial IoT (IIoT) really means making industrial devices work together so they can communicate better for the sake of ultimately improving data analytics, efficiency, and productivity. But in IIoT, as in other industries, data silos are a huge issue. If your data lives in silos, you’re not making the most of it. Unified Namespace (UNS) plays a key role in making IIoT work well — ie, affordably and efficiently – by eliminating data silos and bringing together under one roof all the data from
MongoDB high availability is essential to ensure reliability, customer satisfaction, and business resilience in an increasingly interconnected and always-on digital environment. Ensuring high availability for database systems introduces complexity, as databases are stateful applications. Adding a new operational node to a cluster can take hours or even days, depending on the dataset size.
Current State of MySQL 5.7 MySQL 5.7 is not ideal in terms of scalability. The following figure illustrates the relationship between TPC-C throughput and concurrency in MySQL 5.7.39 under a specific configuration. This includes setting the transaction isolation level to Read Committed and adjusting the innodb_spin_wait_delay parameter to mitigate throughput degradation.
When a machine learning model is trained on a dataset, not all data points contribute equally to the model's performance. Some are more valuable and influential than others. Unfortunately value of data for training purposes is often nebulous and difficult to quantify. Applying data valuation to large language models (LLMs) like GPT-3, Claude 3, Llama 3.1 and their vast training datasets has faced significant scalability challenges to date.
I have always been wondering about performance regression when upgrading in MongoDB. From MongoDB v3.6, despite continuous improvement in the MongoDB feature development, the growing feature set has not included much, if anything in the way of performance improvements.
Personal data processing forms the backbone of many big tech service providers. Tech giants like Netflix, Meta, and Amazon employ intricate networks of microservices to automatically process user data, creating complex data flows that span multiple layers of computation. Privacy concerns and regulatory frameworks like the General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), Brazilian Lei Geral de Protec ̧a ̃o de Dados (LGPD), Digital Markets Act (DMA) ma
Microservices have become the dominant architectural paradigm for building large-scale distributed systems, but until now, their inner workings at major tech companies have remained shrouded in mystery. A recent new paper by Huye et. al - researchers at Tufts University and Meta - provides an unprecedented look under the hood at Meta's massive microservices architecture.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content