This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There was a rather heated discussion around A Context-Driven Approach to Automation in Testing by James Bach and Michael Bolton (referred below as the article and the authors – other references would be explicit). Here are a couple of places where it got fiercely attacked Reviewing “Context Driven Approach to Automation in Testing” by Chris McMahon. and Open letter to “CDT Test Automation” reviewers as well as in many other different places.
Load averages are an industry-critical metric – my company spends millions auto-scaling cloud instances based on them and other metrics – but on Linux there's some mystery around them. Linux load averages track not just runnable tasks, but also tasks in the uninterruptible sleep state. Why? I've never seen an explanation. In this post I'll solve this mystery, and summarize load averages as a reference for everyone trying to interpret them.
Memcached is in-memory key value store whereas Redis is in-memory data structures store. Memcached supports only string data type which is ideal for storing read-only data. Redis supports almost all types of data. Redis can also be used as a messaging system such as pubsub. Memcached cannot be used as a pubsub system. Memcached is more memory efficient than Redis.
A couple of month ago, someone asked if I'd written a page bloat update recently. The answer was no. I've written a lot of posts about page bloat, starting way back in 2012, when the average page hit 1MB. To my mind, the topic had been well covered. We know that the general trend is that pages are getting bigger at a fairly consistent rate of growth.
If you’ve used any of these tools, you may wonder why the results are sometimes different. The post serves to highlight the key differences in these performance analysis tools.
Decision making is tricky business. Decisions often move up and down the chain of command without the input of those best equipped to make those decisions. In smaller companies, there's often too much reliance on the CEO, and that doesn't scale as the company grows. Ultimately, we can easily end up in a situation where the input of those most knowledgeable is not considered.
An interesting discussion started around a very good post Open Source Load Testing Tool Review by Ragnar Lönn. Somehow the latest comment, which I got in my e-mail, didn’t get published. So I decided to copy the discussion as is and publish the comment (and my answer) here. Check the original post (as well as many other great posts) following the link above – but the discussion below is somewhat independent.
One thing that tripped me up early on in my career was the difference between performance and scalability. At first I thought they were exactly the same. I was quite surprised when my first project to scale a system actually made my code run slower… in my dev environment at least. Let’s get definitions out of the way. Scalability is being able to handle large amounts of users/data/traffic.
Sign up to get articles personalized to your interests!
Technology Performance Pulse brings together the best content for technology performance professionals from the widest variety of industry thought leaders.
One thing that tripped me up early on in my career was the difference between performance and scalability. At first I thought they were exactly the same. I was quite surprised when my first project to scale a system actually made my code run slower… in my dev environment at least. Let’s get definitions out of the way. Scalability is being able to handle large amounts of users/data/traffic.
For a quick introduction on what Apache Cassandra is, take a look here. Consistency is a significantly large topic to cover in one part. So I’ll be completing it in 3 parts. This first part defines consistency in general, write consistency, read consistency, consistency levels (CL), immediate, eventual and tunable consistency. Consistency The topic and concept of consistency is very important when you work with a distributed database like Cassandra.
If you haven’t had the chance to watch it yet, Paul Lewis put together an awesome video series that demonstrates how to build a media player alongside some of the great features of Progressive Web Apps. There are a series of videos on YouTube that take place over a couple of days as he builds each new part of the site. Watching videos of developers showcasing their work is definitely one of my favourite ways of learning new things!
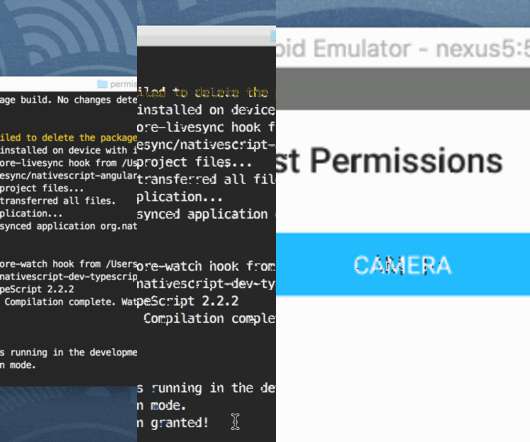
With every version of Android comes more security measures dropped into place. For example, in Android 6+ the user needs to grant permissions when doing certain activities, such as using the camera. These security measures are more aggressive than the previous form of asking permissions in the manifest file. So what if we want to prompt the user to grant permissions at a time other than when trying to use the feature that requires the permissions?
The key to a good user experience is quickly delivering the content your visitors care about the most. This is easy to say, but tricky to do. Every site has unique content and user engagement goals, which is why measuring how fast critical content renders has historically been a challenging task. That's why we're very excited to introduce Hero Rendering Times, a set of new metrics for measuring the user experience.
I’m a software developer. When I see a technical problem, my first thoughts are always for technical solutions. It is the obvious thing to do. However, solving a problem well often requires understanding what caused the problem in the first place. “The previous developer is so bad and I am so baller” was often the answer when I was a lot younger. That specific answer is often incorrect.
In part 1 , I introduced the basics of consistency in general, write consistency, read consistency, consistency levels (CL), immediate, eventual and tunable consistency. In this part 2, I will talk about how to achieve immediate and eventual consistency using different write and read consistency levels. Source: [link] Cassandra has tunable consistency which means that not only on the database level, you can tune the immediate and eventual consistency of your data per query/operation by setting t
"Greed and patience don't live together very well." -- Keith Jackson, ESPN 30 for 30, Who Killed the USFL? Businesses rely on a network of suppliers to operate and grow, including providers of components, back-office operations, distribution, marketing, retail, information technology and even office supplies. They do this for a variety of reasons, ranging from areas of specialty (assembling large finished goods is different from manufacturing small, precision components), depth of expertise (som
While all eyes and instruments were aimed at the total eclipse of August 21st, I had a video camera pointed in the opposite direction. I was hoping to catch changes in the landscape – perhaps the Moon's shadow as it raced by. This was filmed from on a road north east of Madras, Oregon, almost right on the center line. It was just an experiment that I wasn't going to share, but when I saw it afterwards I thought it might interest some.
When building an application, regardless if it is mobile, web, or neither, it is a good idea to come up with a collection of tests that can be used in a continuous integration scenario. I must admit, I don’t have the best habits when it comes to writing tests, but I’m sure my applications would be significantly better if I did. Previously I had written about unit testing in Golang as well as unit testing in NativeScript with Angular.
I just finished Team of Teams and it is one of my favorite books now. I’ve written about the most effective dev team I’ve been in before, but it came with the caveat that I had not seen that kind of structure scale up. Team of Teams describes a similar structure… scaled up to the size of all US forces in Afghanistan. While there are significant differences between technology companies and the military, the one important similarity is that both are composed of people.
In part 2 , I explained how to achieve immediate and eventual consistency using different write and read consistency levels. In this part, I’ll go a bit deeper into understanding different configuration settings and consistency levels. Immediate Consistency with Write CL = ALL, Read CL = ONE The write request is sent to all replicas. Complete write operation is considered successful when all replicas respond a write success.
I was recently shopping at my neighborhood grocery store and encountered yet another real example of the omnipresence of work-as-imagined versus work-as-performed. With only 12 checkout lanes, this is a smaller store. It’s also a heavily trafficked store, sometimes causing long lines. So, any out-of-service lanes have a big customer and operational impact.
Best leaders are admired by their teams. They lead the team without positional authority. They command the unparalleled deep respect of team which is generally quite evident. They are driven by a purpose to serve and not by the power which comes with positional authority.
If you haven’t had the chance to watch it yet, Paul Lewis put together an awesome video series that demonstrates how to build a media player alongside some of the great features of Progressive Web Apps. There are a series of videos on YouTube that take place over a couple of days as he builds each new part of the site. Watching videos of developers showcasing their work is definitely one of my favourite ways of learning new things!
While we've been working hard on supporting.NET Core lately, you may have noticed that we also released a brand new (and dare we say better?) persistence library for NServiceBus called SQL Persistence. The new persister supports multiple database engines and uses raw ADO.NET and native SQL queries, without the need for an intermediate ORM. We dreamed up some powerful new features that would take NServiceBus persistence to the next level.
One thing that tripped me up early on in my career was the difference between performance and scalability. At first I thought they were exactly the same. I was quite surprised when my first project to scale a system actually made my code run slower… in my dev environment at least. Let’s get definitions out of the way. Scalability is being able to handle large amounts of users/data/traffic.
I am pleased to announce that the latest episode of The Polyglot Developer Podcast is now available to download from all the popular podcasting networks. In this episode titled, Authorizing Access with OAuth , I’m joined by Ryan Chenkie from Auth0 to talk about OAuth and how it can be used to authorize access to your data by third-party applications.
Author Abhishek Tiwari is an experienced product and engineering leader with demonstrated competencies across multiple verticals including but not limited to SaaS, E-commerce, Retail, Media, Ad-Tech, MarTech, and Bioinformatics. He played a pivotal role in the development and scaling of several SaaS products and digital platforms with an Annual Run Rate (ARR) of $100M+/year.
I just finished Team of Teams and it is one of my favorite books now. I’ve written about the most effective dev team I’ve been in before, but it came with the caveat that I had not seen that kind of structure scale up. Team of Teams describes a similar structure… scaled up to the size of all US forces in Afghanistan. While there are significant differences between technology companies and the military, the one important similarity is that both are composed of people.
If you haven’t had the chance to watch it yet, Paul Lewis put together an awesome video series that demonstrates how to build a media player alongside some of the great features of Progressive Web Apps. There are a series of videos on YouTube that take place over a couple of days as he builds each new part of the site. Watching videos of developers showcasing their work is definitely one of my favourite ways of learning new things!
I’m a software developer. When I see a technical problem, my first thoughts are always for technical solutions. It is the obvious thing to do. However, solving a problem well often requires understanding what caused the problem in the first place. “The previous developer is so bad and I am so baller” was often the answer when I was a lot younger. That specific answer is often incorrect.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content