This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
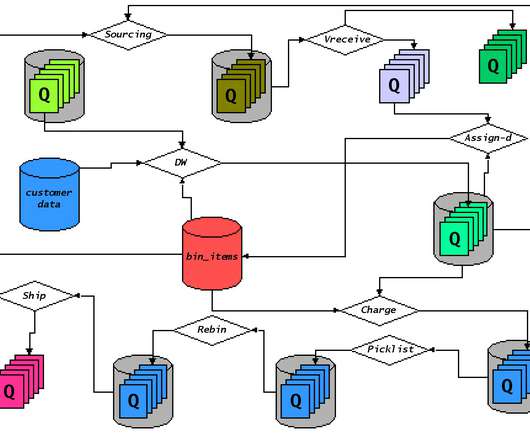
By Soheil Esmaeilzadeh , Negin Salajegheh , Amir Ziai , Jeff Boote Introduction Streaming services serve content to millions of users all over the world. These services allow users to stream or download content across a broad category of devices including mobile phones, laptops, and televisions. However, some restrictions are in place, such as the number of active devices, the number of streams, and the number of downloaded titles.
The containerization craze has continued for enterprises, with benefits such as portability, efficiency, and scalability. In fact, according to a Gartner forecast , revenue for global container management software and services will reach $944 million in 2024 — up from $465.8 million in 2020. With the significant growth of container management software and services, enterprises need to find ways to simplify the process.
Suppose we need to sort the collection by multiple keys. In C#, we can do this with the help of OrderBy().OrderBy() or OrderBy().ThenBy(). But what is the difference between these calls? To answer this question, we need to delve into the source code.
Today, I am publishing the Distributed Computing Manifesto, a canonical document from the early days of Amazon that transformed the architecture of Amazon's ecommerce platform. It highlights the challenges we were facing at the end of the 20th century, and hints at where we were headed.
A Guide To Image Optimization On Jamstack Sites. A Guide To Image Optimization On Jamstack Sites. Alba Silvente. 2022-11-17T10:00:00+00:00. 2022-11-17T14:33:01+00:00. This article is sponsored by Storyblok. Today, creating content on the Internet is the norm, not the exception. It has never been easier to build a personalized website, digitalize a product and start seeing results.
By Vadim Filanovsky and Harshad Sane In one of our previous blogposts, A Microscope on Microservices we outlined three broad domains of observability (or “levels of magnification,” as we referred to them)?—?Fleet-wide, Microservice and Instance. We described the tools and techniques we use to gain insight within each domain. There is, however, a class of problems that requires an even stronger level of magnification going deeper down the stack to introspect CPU microarchitecture.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, a critical task that’s easier said than done. Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. A 2022 Outage Analysis report found that enterprises are struggling to achieve a measurable reduction in outage rates and severity.
Sign up to get articles personalized to your interests!
Technology Performance Pulse brings together the best content for technology performance professionals from the widest variety of industry thought leaders.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, a critical task that’s easier said than done. Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. A 2022 Outage Analysis report found that enterprises are struggling to achieve a measurable reduction in outage rates and severity.
This is an article from DZone's 2022 Performance and Site Reliability Trend Report. For more: Read the Report. Distributed tracing, as the name suggests, is a method of tracking requests as it flows through distributed applications. Along with logs and metrics, distributed tracing makes up the three pillars of observability. While all three signals are important to determine the health of the overall system, distributed tracing has seen significant growth and adoption in recent years.
The optimization of performance testing can contribute to achieving sustainable software engineering. Why is the digital carbon footprint getting bigger every day? What are the best practices to reduce it? Find out everything in this article, with an interview with Mercedes Quintero, Federico Toledo, and. The post Sustainable Software Engineering Through Performance Testing appeared first on Abstracta Software Testing Services.
User experience is the number one priority for every business in the market today. As a developer, even the brief you get on your project talks about the simplicity of the user interface it is supposed to feature.
by Christos G. Bampis , Li-Heng Chen and Zhi Li When you are binge-watching the latest season of Stranger Things or Ozark, we strive to deliver the best possible video quality to your eyes. To do so, we continuously push the boundaries of streaming video quality and leverage the best video technologies. For example, we invest in next-generation, royalty-free codecs and sophisticated video encoding optimizations.
Following the launch of Dynatrace® Grail for Log Management and Analytics , we’re excited to announce a major update to our Business Analytics solution. Business events powered by our new Grail™ data lakehouse and by other Dynatrace platform technologies ensures the real-time precision that business and IT teams need to make data-driven decisions and improve business outcomes.
This is an article from DZone's 2022 Performance and Site Reliability Trend Report. For more: Read the Report. In the past few years, the complexity of systems architectures drastically increased, especially in distributed, microservices-based architectures. It is extremely hard and, in most cases, inefficient to debug and watch logs, particularly when we have hundreds or even thousands of microservices or modules.
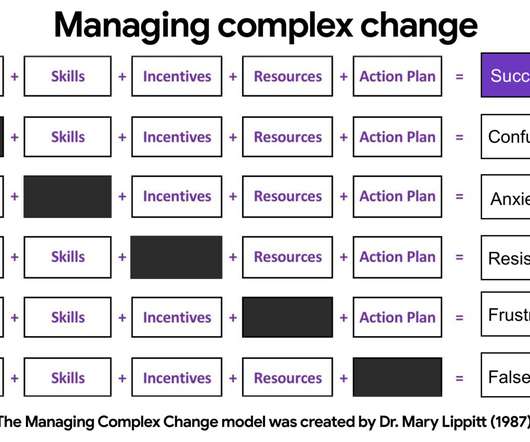
Observability allows visibility into distributed systems for automated problem identification and resolution. Observability-driven development (ODD) is an approach to shift left observability to the earliest stage of the software development life cycle. This article provides a guide on ODD and its benefits, its role in SDLC, and key considerations for adoption.
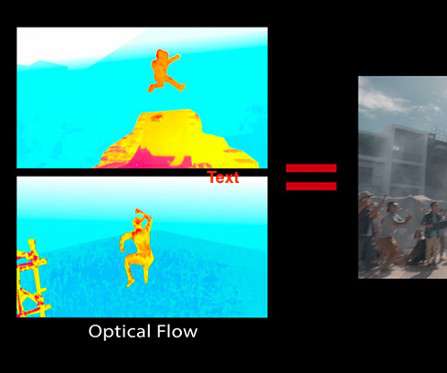
By: Peter Cioni (Netflix), Alex Schworer (Netflix), Mac Moore (Conductor Tech.), Rachel Kelley (AWS), Ranjit Raju (AWS) Rendering is core to the the VFX process VFX studios around the world create amazing imagery for Netflix productions. Nearly every show that is produced today includes digital visual effects, from the creatures in Stranger Things , to recreating historic London in Bridgerton.
More organizations are adopting a hybrid IT environment, with data center and virtualized components. However, today’s IT teams are stretched thin, with little time to firefight issues with deployment, integration, and data center management. Therefore, they need an environment that offers scalable computing, storage, and networking. That’s where hyperconverged infrastructure, or HCI, comes in.
This is an article from DZone's 2022 Performance and Site Reliability Trend Report. For more: Read the Report. Software testing is straightforward — every input => known output. However, historically, a great deal of testing has been guesswork. We create user journeys, estimate load and think time, run tests, and compare the current result with the baseline.
A few minutes ago, the ISO C++ committee completed its second-to-last meeting of C++23 in Kona, HI, USA. Our host, the Standard C++ Foundation, arranged for high-quality facilities for our six-day meeting from Monday through Saturday. We currently have 26 active subgroups, nine of which met in six parallel tracks throughout the week; some groups ran all week, and others ran for a few days or a part of a day, depending on their workloads.
By Vi Iyengar , Keila Fong , Hossein Taghavi , Andy Yao , Kelli Griggs , Boris Chen , Cristina Segalin , Apurva Kansara , Grace Tang , Billur Engin , Amir Ziai , James Ray , Jonathan Solorzano-Hamilton Welcome to the first post in our multi-part series on how Netflix is developing and using machine learning (ML) to help creators make better media?—?
Complexity and data volume for IT infrastructure soars to new heights. The volume of data and events grows in tandem with the rising complexity of IT infrastructure. Monitoring modern IT infrastructure is difficult, sometimes impossible, without advanced network monitoring tools. While the market is saturated with many Network Administrator support solutions, Dynatrace can help you analyze the impact on your organization in an automated manner.
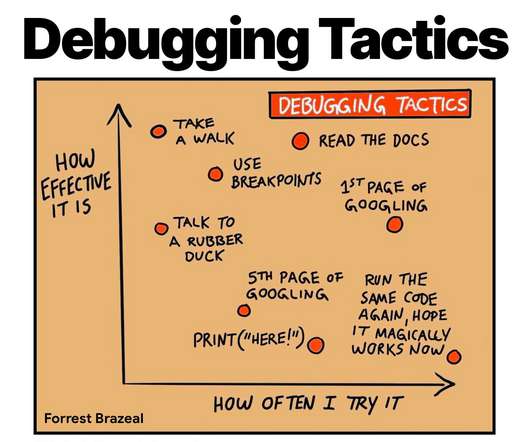
This is an article from DZone's 2022 Performance and Site Reliability Trend Report. For more: Read the Report. Site reliability engineering (SRE) is the state of the art for ensuring services are reliable and perform well. SRE practices power some of the most successful websites in the world. In this article, I'll discuss who site reliability engineers (SREs) are, what they do, key philosophies shared by successful SRE teams, and how to start migrating your operations teams to the SRE model.
Agile testing methodology is an integral part of the agile software development process. It is because agile testers allow product owners and stakeholders to communicate.
So you’re building serverless applications with Microsoft Azure Functions, but you need to persist data to a database. What do you do about controlling the number of concurrent connections to your database from the function? What happens if the function currently connected to your database shuts down or a new instance comes online to scale with demand?
by Tomasz Bak and Fabio Kung Introduction Titus is the Netflix cloud container runtime that runs and manages containers at scale. In the time since it was first presented as an advanced Mesos framework, Titus has transparently evolved from being built on top of Mesos to Kubernetes, handling an ever-increasing volume of containers. As the number of Titus users increased over the years, the load and pressure on the system increased substantially.
Today, AWS Compute Optimizer has expanded its metric ingest beyond Cloudwatch, which will be announced at the Amazon re:Invent 2022 conference in Las Vegas November 28-December 2. AWS Compute Optimizer now includes third-party metrics to further power user insights surrounding memory usage in Amazon Elastic Cloud Compute (EC2) Instances. Now offering a native integration with the AWS offering, Dynatrace can dynamically send memory metrics on monitored EC2 instances across AWS environments.
This is an article from DZone's 2022 Performance and Site Reliability Trend Report. For more: Read the Report. Open-source software (OSS) has had a profound impact on modern application delivery. It has transformed how we think about collaboration, lowered the cost to maintain IT stacks, and spurred the creation of some of the most popular software applications and platforms used today.
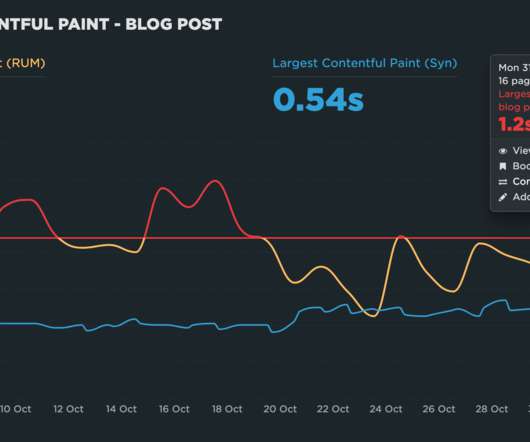
Labeling your pages in your synthetic and real user monitoring (RUM) tools is a crucial step in your performance monitoring setup. We recently released some exciting new capabilities for labeling your RUM pages that we want to share with you. This is also a great opportunity to reiterate why page labels are important, and to show you how easy it is to apply labels to your pages.
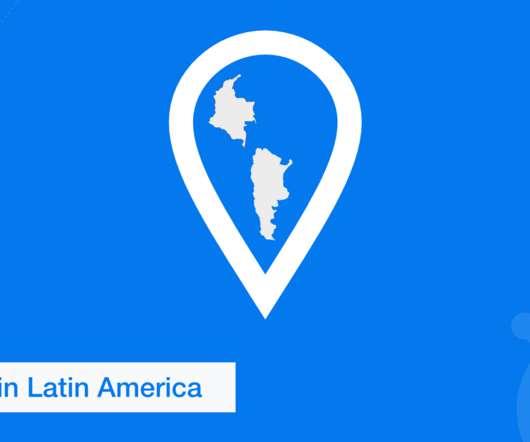
We are excited about the newly established points of presence (POPs) in Latin America! So far, we could cover Latin America through Mexico City, Santiago, and São Paulo. Now Buenos Aires and Bogotá have been added. KeyCDN is always looking for ways to minimize latency and accelerate the delivery of assets worldwide. The proximity to Latin American users now enables even more reliable and faster connections within Latin America and outside the region to anywhere else in the world.
How was the Workshop on Performance and Reliability (WOPR) born? What is the vision behind it? Find out in this article, featuring Eric Proegler and Paul Holland. By Natalie Rodgers WOPR is still making significant contributions even after 29 editions. The first one was held. The post A Look at WOPR’s History From Within appeared first on Abstracta Software Testing Services.
Dynatrace is proud to be an AWS launch partner in support of Amazon Lambda SnapStart. The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). Today, application modernization efforts are centered on application programming interfaces and microservices that are sensitive to startup latency.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content