This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations today are struggling to tame massive amounts of data by throwing myriad tools at the problem. This can result in a slower pace of innovation. For AWS customers, it can also be an opportunity to realize business benefits from existing AWS investments. The need for an AI-enabled, unified cloud observability and security platform to deliver automation and intelligence at scale across the digital enterprise has never been greater.
In the previous article , we spoke about hunting bugs. But a time will come when your hunters trophy collection grows to a scary size. More and more targets will be coming as if it were a zombie apocalypse. There will be red lamps flashing across your metrics dashboard. If (or rather when) that happens, it would mean its time for a bigger change than just routine debugging and streamlining your codebase.
Kubernetes is becoming a popular choice for running containerized applications. While the core idea is to have a single container running the application in a Pod, there are many cases where one or more containers need to run alongside the application container, such as containers for capturing logs, metrics, etc.
Modern distributed systems, like microservices and cloud-native architectures, are built to be scalable and reliable. However, their complexity can lead to unexpected failures. Chaos engineering is a useful way to test and improve system resilience by intentionally creating controlled failures. However, it can be costly due to resource usage, monitoring needs, and testing in production-like environments.
As more organizations move their PostgreSQL databases onto Kubernetes, a common question arises: Which storage solution best handles its demands? Picking the right option is critical, directly impacting performance, reliability, and scalability. For stateful workloads like PostgreSQL, storage must offer high availability and safeguard data integrity, even under intense, high-volume conditions.
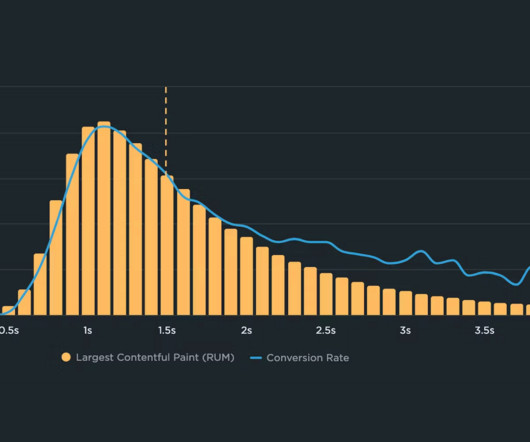
If you could measure the impact of site speed on your business, how valuable would that be for you? Say hello to correlation charts – your new best friend. Here's the truth: The business folks in your organization probably don't care about page speed metrics. But that doesn't mean they don't care about page speed. It just means you need to talk with them using metrics they already care about – such as conversion rate, revenue, and bounce rate.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content