This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
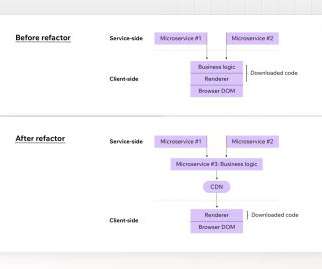
Given this limitation, it was advantageous to have fewer files: if we needed to download 18 files, that’s three separate chunks of work; if we could somehow bring that number down to six, it’s only one discrete chunk of work. 4,362ms of cumulative latency; 240ms of cumulative download. main.af8a22.css It’s a balancing act for sure. ?
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. HTML downloaded. Speed index. Visually complete.
Performance, errors, and user experience Dynatrace has long understood the importance of performance as a foundational component of user experience and the impact that page speed and any friction introduced by errors have on user behavior. The addition of more and more metrics over time has only made this increasingly complex.
Here are some common questions I’m asked when I talk with people about performance: Which metrics should I care about? Page Speed Benchmarks is an interactive dashboard that lets you explore and compare web performance data for leading websites across several industries – from retail to media. How fast should I be?
How does this affect your page speed, your Core Web Vitals, your search rank, your business, and most important – your users? For almost fifteen years, I've been writing about page bloat, its impact on site speed, and ultimately how it affects your users and your business. Keep scrolling for the latest trends and analysis.
Observability requires complete access to metrics, traces, and logs. OpenTelemetry is an open source standard for gathering observability signals, including metrics, traces, and logs. If you are interested in learning more about RIA and its research, download the report and take a deeper look. .
This traditional approach presents key performance metrics in an isolated and static way, providing little or no insight into the business impact or progress toward the goals systems support. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends.
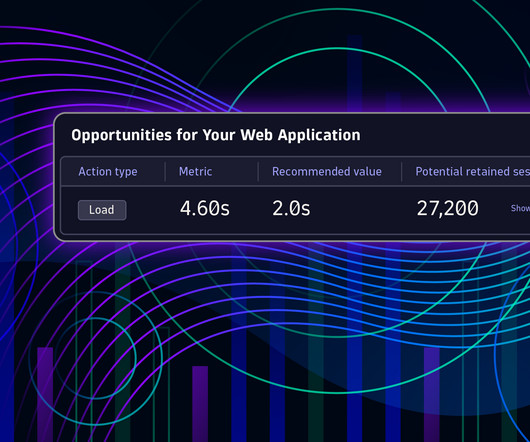
However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. For many traditional web applications , User action duration is considered the best metric available for web-performance optimization.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Check out the on-demand Power Demo, Dynatrace and Business Observability: Tying IT Metrics to Business Outcomes. See observability in action! Watch webinar now!
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation tools speed up delivery cycles by reducing human error and bottlenecks, resulting in fewer and shorter feedback loops. It helps to assess the long- and short-term efficiency and speed of DevOps.
Here’s a list of some key hyperscale benefits: Speed : Hyperscale makes it easy to manage your shifting computing needs. This helps you transform faster by taming modern cloud complexity with observability, automation, and intelligence in a single platform delivering multicloud observability that’s more than metrics, logs, and traces.
But with many organizations relying on traditional, manual processes to ensure service reliability and code quality, software delivery speed suffers. DevOps automation is necessary to increase speed and efficiency in the software development pipeline. Download now! Automation is a crucial aspect of achieving DevOps excellence.
Customer lifetime value (CLV) has long been established as the key metric financial services firms use to gauge their profitability and competitive position in the market. Over a quarter of respondents (26%) expect it to continue to speed up in the future.
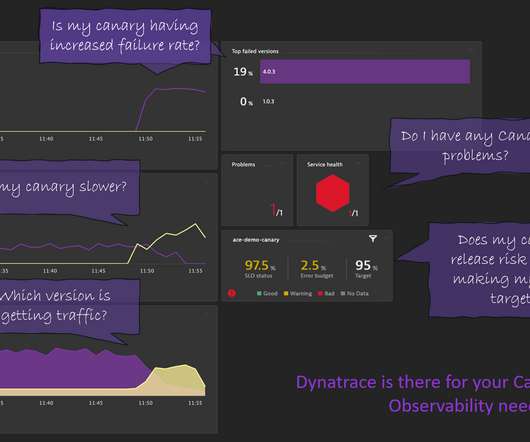
As a result, site reliability has emerged as a critical success metric for many organizations. Microservices-based architectures and software containers enable organizations to deploy and modify applications with unprecedented speed. The following three metrics are commonly used to measure success: Service-level agreements (SLAs).
According to Google G-Suite researchers , a good availability metric should be meaningful (captures user experience), proportional (change in the metric should be proportional to the change in user-perceived availability), and actionable (insight into why the metric is low or high). Let’s take service availability for example.
By providing customers the most comprehensive, intelligent, and easy-to-deploy observability solution in the market, Dynatrace and Microsoft have laid the groundwork for organizations to successfully migrate to cloud environments and continuously modernize with speed and scalability. This monitoring is ongoing.
It’s true that what might be considered the “most important” or “best” web performance metrics can vary by industry. These six metrics were not chosen at random – they work together to give you a snapshot of your site’s performance and overall user experience so you can set a baseline and improve speed and usability.
Progressive Delivery enables speeding up while managing the risk of software deployments and configuration changes. As mentioned above I encourage you to watch Kristof’s video closely and also download the slides from Dynatrace University. Having metrics with version information, e.g, Dynatrace news. Step 3: SLOs. So – go ahead!
However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality. Read this blog to learn more.
And for DevOps, it means accelerating DevOps processes, improving agility, and speeding time to market. To dive deeper into this research, download the free ebook, “ Generative AI in IT Operations: Fueling the Next Wave of Modernization.” Traditional and new challenges are emerging when integrating AI into IT operations.
Observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. This process includes the following functionalities: The Dynatrace dashboard tile defines any metric along with its target or SLO. The collected set of metrics are queries for some timeframe.
Latency is a key limiting factor on the web: given that most assets fetched by webpages are relatively small (compared to, say, downloading a software update or streaming a movie), we find that most experiences are latency-bound rather than bandwidth-bound. RTT data should be seen as an insight and not a metric.
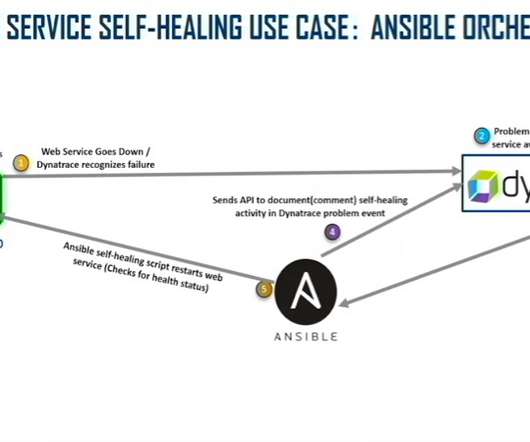
Each piece of the AIOps triumvirate plays a crucial role in the automation process to speed innovation. These metrics can show DevSecOps teams whether the problem is with Apache, the central processing unit, MySQL, or a query issue. This platform-based approach to observability enables IT teams to automate remediation efforts.
We deployed these enhancements gradually over time to ensure that our users didn’t experience any disruptions, but instead only a consistent improvement of their site speed. While some noticeable progress was made, it was challenging to implement significant changes just for the sake of speed. Creating A Performance Culture.
Lets take a look at what the LCP subparts are, what they mean for your website speed, and how you can measure them. The Four LCP Subparts LCP subparts split the Largest Contentful Paint metric into four different components: Time to First Byte (TTFB) : How quickly the server responds to the document request.
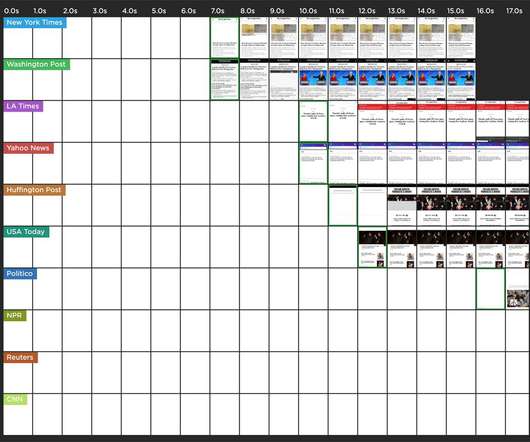
The first is where an application package is downloaded from the service or a CDN. Application version adoption over time for a staged rollout This chart represents a counter metric, which exhibits version adoption over the duration of a staged rollout. Client Applications We deal with two classes of client application updates.
Web performance metrics track the efficiency (or lack thereof) of any individual aspect of your website’s performance. Once you have started collecting some of these must-track web performance metrics for your website, inefficiencies will become clearer. Top 10 Web Perf Metrics to Track. Resource Download Time.
Dynatrace’s Software Intelligence Platform includes multiple modules, underpinned by a common data platform, and offers users APM, AIOps, infrastructure monitoring spanning logs and metrics, digital business analytics and digital experience monitoring capabilities. Want to learn more?
Davis tells you which statements need to be improved to speed up your application. For each statement, we provide you with 14 metrics. Download the execution plan to analyze it. Oracle performance metrics. From the hundreds of available Oracle performance metrics, we’ve selected those that matter most.
It’s one of the most frequently asked questions I see asked, “I’ve tested my site speed, so now what do these metrics mean?” Here we’ll explain what each of the common web performance metrics mean, and how can you use that data to optimize your site and make it faster. Standard Website SpeedMetrics.
This has been confirmed by the operations lead of a European organization catering to disabled people, “it significantly speeds deployment up and allows us to replicate the locations very quickly in a test environment.” This way the location is always big enough to effectively handle the load but does not consume more resources than needed.
Across the performance industry, the metric that's used the most is "page load time" (i.e, "window.onload" or "document complete"). In the last few years some better alternatives to page load time have gained popularity, such as start render time and Speed Index. The way to do this is to create custom metrics with User Timing.
Have you ever looked at the page speedmetrics – such as Start Render and Largest Contentful Paint – for your site in both your synthetic and real user monitoring tools and wondered "Why are these numbers so different?" And as the graph below shows, even some urban centres can suffer downloadspeeds as low as 20 Mbps.
It's important that the critical content is downloaded and rendered before users get frustrated. Network metrics have been around for decades, but rendering metrics are newer. Speed Index. These are a few of the rendering metrics that currently exist. A brief history of performance metrics. Start Render.
They collect metrics and raise alerts, but they provide few answers as to what went wrong in the first place. Davis—the Dynatrace AI engine —uses the application topology and service flow maps together with high-fidelity metrics to perform a fault tree analysis. Conventional (not built for cloud) monitoring tools are not much help.
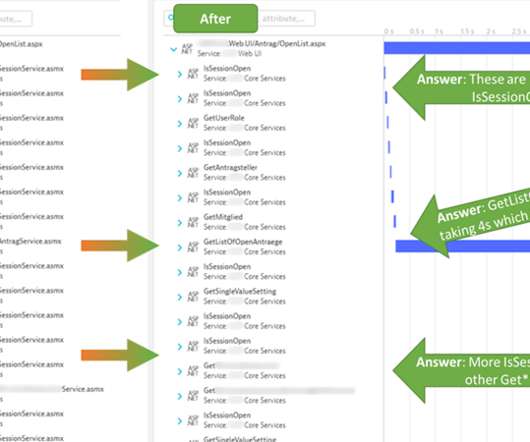
The challenge with ASP.NET Web Service Observability, Diagnostics and Performance Optimization is that most monitoring & diagnostic tools only provide global Service Level Indicators metrics (SLIs) such as response time, failure rate, and throughput, but not metrics for each individual service endpoint.
The COVID-19 pandemic accelerated the speed at which organizations digitally transform — especially in industries such as eCommerce and healthcare — as expectations for a great customer experience dramatically increased. Download our free whitepaper, “ Observability: How to lead your federal agency to a digital transformation.”
Additionally, teams are measuring and tracking key business metrics – conversion rates, cart abandonment rates, customer lifetime value, revenue by traffic source, and so on. Why Are User-centric Metrics Essential for Ecommerce? Which Metrics Matter for Ecommerce? At this point, you’re probably saying, “Great.
There are three web vitals metrics Google uses to measure different aspects of website performance: Largest Contentful Paint (LCP), Cumulative Layout Shift (CLS), Interaction to Next Paint (INP). Large preview ) Largest Contentful Paint (LCP) The Largest Contentful Paint metric is the closest thing to a traditional load time measurement.
However, if utilized carelessly, CSS can greatly affect our page speed. That’s good to know, but I know you’re looking for a css speed test, or techniques for optimizing your css for speed. If these aren’t being downloaded asynchronously (see below), that’s a problem. Perform an Audit of Your Site.
Datadog is a cloud-scale monitoring platform that combines infrastructure metrics, distributed traces, and logs all in one place. Get visibility into your production issues without juggling multiple tabs and different services -- all of your logs, server metrics and alerts are in your browser and at your fingertips.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content