This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Mobile applications (apps) are an increasingly important channel for reaching customers, but the distributed nature of mobile app platforms and delivery networks can cause performance problems that leave users frustrated, or worse, turning to competitors. User acquisition measures the number of new users downloading and installing an app.
Compressing them over the network: Which compression algorithm, if any, will we use? Given this limitation, it was advantageous to have fewer files: if we needed to download 18 files, that’s three separate chunks of work; if we could somehow bring that number down to six, it’s only one discrete chunk of work. main.af8a22.css
They collect data from multiple sources through real user monitoring , synthetic monitoring, network monitoring, and application performance monitoring systems. Align business and development teams’ input on what user experience metrics to measure to understand users’ most critical digital experience aspects. Speed index.
As businesses increasingly embrace these technologies, integrating IoT metrics with advanced observability solutions like Dynatrace becomes essential to gaining additional business value through end-to-end observability. Both methods allow you to ingest and process raw data and metrics.
The journey toward business observability Traditional IT monitoring that relies on a multitude of tools to collect, index, and correlate logs from IT infrastructure, networks, applications, and security systems is no longer effective at supporting the need of the wider organization for business insights.
The forecast operation is selected within the Davis action, and a DQL query is used to specify the set of disks and the capacity indicator metric that should be predicted. Tip: Download the TypeScript template from our documentation. In this example, two parallel actions are defined. Create an alarm event for predicted shortages.
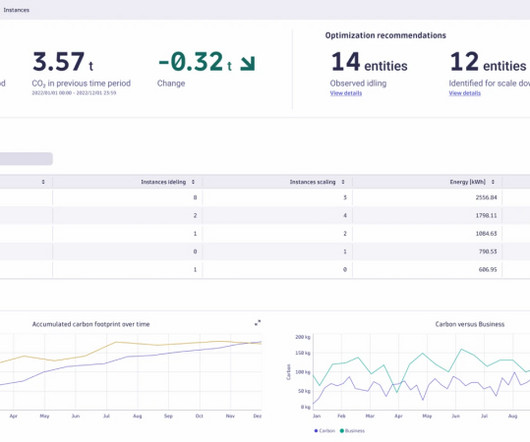
The app’s advanced algorithms and real-time data analytics translate utilization metrics into their CO2 equivalent (CO2e). These metrics include CPU, memory, disk, and network I/O. To learn more about our commitment to our ESG strategy, download the Dynatrace 2023 Global Impact Report.
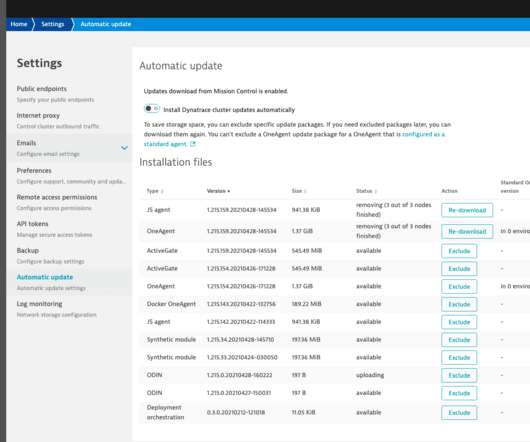
If you opt-out from automatic updates download, you’ll start to receive e-mail notifications with update package URLs ready to download by you. Defining which OneAgent binaries don’t need to be downloaded Dynatrace Managed Updates. See Update Dynatrace Managed topic. Cluster Management Console. Resolved issues.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. Not just infrastructure connections, but the relationships and dependencies between containers, microservices , and code at all network layers. Watch webinar now!
As a result, site reliability has emerged as a critical success metric for many organizations. The growing amount of data processed at the network edge, where failures are more difficult to prevent, magnifies complexity. The following three metrics are commonly used to measure success: Service-level agreements (SLAs).
However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. For many traditional web applications , User action duration is considered the best metric available for web-performance optimization.
For Carbon Impact, these business events come from an automation workflow that translates host utilization metrics into energy consumption in watt hours (Wh) and into greenhouse gas emissions in carbon dioxide equivalent (CO2e). Again, utilization metrics are the key to distributing emissions by individual software processes.
However, with today’s highly connected digital world, monitoring use cases expand to the services, processes, hosts, logs, networks, and of course, end-users that access these applications – including your customers and employees. Download Magic Quadrant. APM can be referred to as: Application performance monitoring.
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time. Define core metrics.
It can be used along with a visualization tool like Grafana to easily create and edit dashboards, query, visualize, alert on, and understand your metrics. These tools will provide additional insight to your metrics, usage patterns, and datasets along with your ScaleGrid MySQL monitoring , query analysis , and alerts. cut -d '"' -f 4.
OneAgent gives you all the operational and business performance metrics you need, from the front end to the back end and everything in between—cloud instances, hosts, network health, processes, and services. But what if a particular metric is crucial for your monitoring needs and it isn’t there?
As your team begins its journey toward DevOps automation, consider tracking key DevOps metrics such as the following to help assess your organization’s progress and to encourage buy-in from reluctant stakeholders: Deployment frequency measures how often a team successfully releases to production. Automated network provisioning.
Unified observability is the ability to know how systems and infrastructure are performing based on the data they generate, such as logs, metrics, and traces. Observability provides banks and other financial institutions with real-time insight into their IT environment, including applications, infrastructure, and network traffic.
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. You can’t change that someone was from Nigeria, you can’t change that someone was on a mobile, and you can’t change their network conditions. RTT data should be seen as an insight and not a metric.
Furthermore, the movie file is very large (often several 100s of GB), and we want to avoid downloading the entire file for each individual video encoder that might be processing only a small segment of the whole movie. MezzFS collects metrics on data throughput, download efficiency, resource usage, etc. Actions ?—?MezzFS
Users can run the Dynatrace OTel Collector to mask sensitive data next to applications and ensure that no sensitive data leaves the internal network. Users can also filter telemetry data for all signals (traces, metrics, and logs). Ingest and multiplex data.
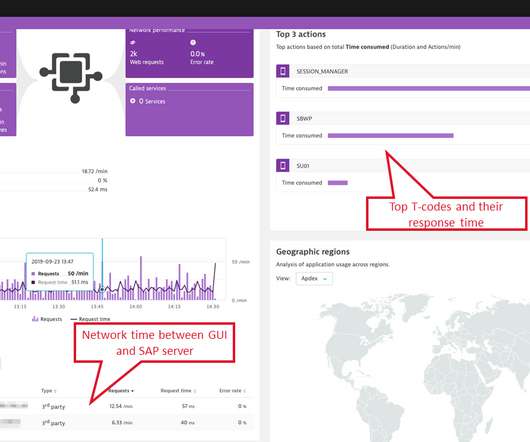
This also helps the Operations teams that are tasked with SAP user performance problem triaging, which usually requires cross-disciplinary knowledge, ranging from network monitoring through infrastructure load and dependencies to SAP application and transaction specifics. Understand the root cause of the degraded GUI response time.
There are certain situations when an agent based approach isn’t possible, such as with network or storage devices, or a very old OS. To get started, download and install one of the extensions by following the instructions on GitHub. Dynatrace OneAgent is great for monitoring the full stack. Get started with Dynatrace extensions.
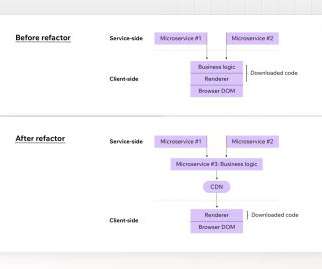
But cloud transformation makes this much more challenging as outages can be caused by your cloud provider, your third party helping you deliver personalized experiences, your content delivery network (CDN) , and many other services you are leveraging. It’s also from a brand perspective highly relevant. What are KPIs you want to look at?
Having the right metrics available on demand and at a high resolution is key to understanding how a system behaves and helps to quickly troubleshoot performance issues. Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? or “are there noisy neighbors affecting my container task?”.
To simulate those users’ journeys, multiple synthetic locations deployed within various sections of internal networks are required. After saving the location’s configuration, you’re allowed to download the generated YAML file automatically which will be the basis for your deployment.
While mobile devices have come a long way in terms of network and CPU speed, many of them are still significantly underpowered when compared to desktops, especially in countries where mobile connectivity is still poor. Better tooling and metrics standardization. In other words, the field lacked standardization.
Therefore, it requires multidimensional and multidisciplinary monitoring: Infrastructure health —automatically monitor the compute, storage, and network resources available to the Citrix system to ensure a stable platform. These metrics help you understand whether your Citrix landscape is sized correctly for its load.
However, with today’s highly connected digital world, monitoring use cases expand to the services, processes, hosts, logs, networks, and of course end-users that access these applications – including your customers and employees. Download the 2020 Gartner Magic Quadrant report for APM here. You can download the report here.
They collect metrics and raise alerts, but they provide few answers as to what went wrong in the first place. Davis—the Dynatrace AI engine —uses the application topology and service flow maps together with high-fidelity metrics to perform a fault tree analysis. Conventional (not built for cloud) monitoring tools are not much help.
BOSH loves YAML (so it’s in good company with Kubernetes) and follows a declarative approach for defining the desired state of Cloud Foundry’s various components as well as the underlying virtual machines, networks, and storage devices. In the lightweight approach, BOSH downloads the latest OneAgent from the Internet.
The Four LCP Subparts LCP subparts split the Largest Contentful Paint metric into four different components: Time to First Byte (TTFB) : How quickly the server responds to the document request. Resource Load Delay : Time spent before the LCP image starts to download. Resource Load Time : Time spent downloading the LCP image.
Web performance metrics track the efficiency (or lack thereof) of any individual aspect of your website’s performance. Once you have started collecting some of these must-track web performance metrics for your website, inefficiencies will become clearer. Top 10 Web Perf Metrics to Track. Resource Download Time.
Technically, “performance” metrics are those relating to the responsiveness or latency of the app, including start up time. At Netflix the term “performance” usually encompasses both performance metrics (in the strict meaning) and memory metrics, and that’s how we’re using the term here. What do we mean by Performance?
It's important that the critical content is downloaded and rendered before users get frustrated. Networkmetrics have been around for decades, but rendering metrics are newer. These are a few of the rendering metrics that currently exist. A brief history of performance metrics. Metrics quantify behavior.
This also helps the Operations teams that are tasked with SAP user performance problem triaging, which usually requires cross-disciplinary knowledge, ranging from network monitoring through infrastructure load and dependencies to SAP application and transaction specifics. Understand the root cause of the degraded GUI response time.
Additionally, teams are measuring and tracking key business metrics – conversion rates, cart abandonment rates, customer lifetime value, revenue by traffic source, and so on. Why Are User-centric Metrics Essential for Ecommerce? Which Metrics Matter for Ecommerce? At this point, you’re probably saying, “Great.
Lazy-load offscreen images (reduce network contention for key resources). For low impact to First Input Delay : Avoid images causing network contention with other critical resources like CSS and JS. Cumulative Layout Shift (CLS, a Core Web Vitals metric) measures the instability of content. Lighthouse. Large preview ).
Have you ever looked at the page speed metrics – such as Start Render and Largest Contentful Paint – for your site in both your synthetic and real user monitoring tools and wondered "Why are these numbers so different?" And as the graph below shows, even some urban centres can suffer download speeds as low as 20 Mbps.
In this blog post, we’ll use Dynatrace Security Analytics to go threat hunting, bringing together logs, traces, metrics, and, crucially, threat alerts. Attack tactics describe why an attacker performs an action, for example, to get that first foothold into your network. Scanned our internal network with nmap.
Smaller HTML means less time for Google to download and process those long strings of text. Part of having a small LCP is to let the user download as small HTML as possible. Part of having a small LCP is to let the user download as small HTML as possible. In the meanwhile, React javascript is being downloaded and executed.
Training Performance Media model training poses multiple system challenges in storage, network, and GPUs. Step 1 We download a video file and produce shot boundary metadata. Feature value storage We store embeddings in Amber , which guarantees immutability, versioning, auditing, and various metrics on top of the feature values.
The tests are all going to be run using WebPageTest , on a Moto G4, over a fast 3G network. The Optimizely script is 133.2kb, and it’s loaded as a blocking script (meaning, the browser won’t parse any more HTML until it gets downloaded and executed). to download. and a Largest Contentful Paint time of 5.5s.
Application performance monitoring (APM) is the practice of tracking key software application performance metrics using monitoring software and telemetry data. Causes can run the gamut — from coding errors to database slowdowns to hosting or network performance issues. Dynatrace news. What does APM stand for? Performance monitoring.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content