This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Twilio is a call management system that provides excellent call recording capabilities, but often organizations are in need of automatically downloading and storing these recordings locally or in their preferred cloud storage. However, downloading large numbers of recordings from Twilio can be challenging.
Besides the need for robust cloud storage for their media, artists need access to powerful workstations and real-time playback. Local storage and compute services are connected through the Netflix Open Connect network (Netflix Content Delivery Network) to the infrastructure of Amazon Web Services (AWS).
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Our object storage service splits objects into many parts and stores them in S3.
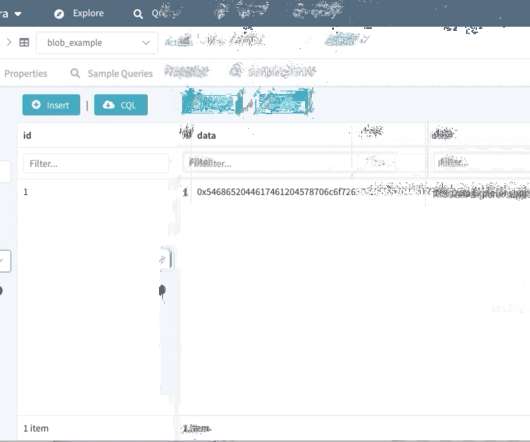
One day I faced the problem with downloading a relatively large binary data file from PostgreSQL. To resolve the problem it was suggested to find more suitable data storage. There are several limitations to store and fetch such data (all restrictions could be found in official documentation ).
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Greenplum’s high performance eliminates the challenge most RDBMS have scaling to petabtye levels of data, as they are able to scale linearly to efficiently process data. Polymorphic Data Storage. Major Use Cases.
Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances. From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Unlike data warehouses, however, data is not transformed before landing in storage.
Smaller network and Dynatrace cluster storage footprint. All of these changes effectively reduce the size of the Windows installer on Dynatrace by over 60%, which makes the installer faster to download, too. The post Rebuilt OneAgent installer for Windows provides more efficient installation appeared first on Dynatrace blog.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. GitOps practices can improve infrastructure management efficiency and stability.
This way, disruptions are minimized, MTTR is significantly decreased, and DevSecOps and SREs collaborate efficiently to boost productivity. Download the Dynatrace collection from the Red Hat Ansible Automation Hub and follow the installation guide. Get started by downloading samples from our workflow samples repository.
You can also check out our Working with JSON Data in PostgreSQL vs. MongoDB webinar in partnership with PostgresConf to learn more on the topic, and check out our SlideShare page to download the slides. JSONB supports indexing the JSON data, and is very efficient at parsing and querying the JSON data. What’s in this article?
We have been leveraging machine learning (ML) models to personalize artwork and to help our creatives create promotional content efficiently. Media Feature Storage: Amber Storage Media feature computation tends to be expensive and time-consuming. Step 1 We download a video file and produce shot boundary metadata.
How do you know if your MySQL database caching is operating efficiently? Its main data caching structure for the standard InnoDB storage engine is called Buffer Pool. I strongly believe there’s an important place for this graph on “data caching efficiency” for MySQL in PMM. MySQL does.
These capabilities enable deeper insights into all areas of GCP environments, which in turn allows businesses to quickly troubleshoot performance issues, optimize container workloads, and efficiently scale cloud operations. Google Cloud Storage. Google Cloud Datastore. Google Cloud Load Balancing. Google Cloud Pub/Sub.
Dynatrace OneAgent deployment and life-cycle management are already widely considered to be industry benchmarks for reliability and efficiency. Easier rollout thanks to log storage best practices. Easier rollout thanks to log storage best practices. Dynatrace news. Advanced customization of OneAgent deployments made easy.
Create and upload the extension Download the extension ZIP file. This alert serves as a valuable tool in maintaining operational efficiency, ensuring business continuity, and delivering optimal customer experiences. Don’t rename the file.
Carbon Impact uses host utilization metrics from OneAgents to report the estimated energy consumption for CPU, storage I/O, memory, and network. We provide a Notebook for you to follow along in your Dynatrace tenant; you can run or download the Notebook from the Dynatrace Playground and upload it to your tenant.
By doing so, they can improve efficiency, reduce costs, and deliver better customer experiences. Dynatrace for unified, AI-powered log management and analytics Dynatrace enables teams to analyze logs, metrics, and events in the context of traces, topology, and user sessions, with no schemas or storage tiers to manage.
The first version of our logger library optimized for storage by deduplicating facts and optimized for network i/o using different compression methods for each fact. Since we were optimizing at the logging level for storage and performance, we had less data and metadata to play with to optimize the query performance.
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. By default, MongoDB provides a snappy block compression method for storage and network communication.
A bloom filter is a space-efficient way of storing information about a list of keys. LSM storage engines like MyRocks are very different from the more common B-Tree-based storage engines like InnoDB. Bloom filter is an important feature improving performance of LSM storage engines.
For instance, video playback functionality on Netflix involves requesting URLs for the streams from a service, calling the CDN to download the bits from the streams, requesting a license to decrypt the streams from a separate service, and sending telemetry indicating the successful start of playback to yet another service.
Download Percona Distribution for PostgreSQL Today! As the size of the active dataset increases, the cache becomes less and less efficient. This is in addition to the read I/O required to bring the additional index pages from storage for specific queries. Indexes can get bloated and become less efficient over time.
We will also discuss related configuration variables to consider that can impact these KPIs, helping you gain a comprehensive understanding of your MySQL server’s performance and efficiency. Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution.
Overall, 53% of IT leaders say t he number of tools needed to monitor the end-to-end technology stack makes it difficult to operate efficiently. For more insights into the challenges government CIOs face and their recommendations on overcoming them, download the ” 2022 Dynatrace CIO Report: Government and Public Sector.” .
Benefits of Power BI The advantages of Power BI are manifold, from its intuitive interface to its ability to handle large datasets efficiently. Download and install it before proceeding with the integration. Also, make sure to download and install the MySQL connector. Why connect Power BI to a MySQL Database?
It offers highlights, critical information, links to the full release notes, and direct links to the software or service itself to download. Percona Distribution for PostgreSQL installs PostgreSQL and complements it with a selection of extensions that enable solving essential practical tasks efficiently. Take a look!
Citrix is a sophisticated, efficient, and highly scalable application delivery platform that is itself comprised of anywhere from hundreds to thousands of servers. Dynatrace automation and AI-powered monitoring of your entire IT landscape help you to engage your Citrix management tools where they are most efficient. Dynatrace news.
There has got to be a balance between the propagation and duplicative storage as far as the savings that would be realized by the efficiency of saving requests. Is that more energy-efficient than creating that area by attaching a click handler on a button that toggles the class of an element that visually opens and closes it?
It also provides tools to view the storage layout on disk; browse the supported sample queries (to help design efficient point queries); guide you through the process of choosing a compaction strategy, and many other advanced settings. The Data Explorer won’t fetch binary value data by default (as the persisted data might be sizable).
pgBackRest is a highly efficient and versatile tool for managing PostgreSQL backups. This issue tends to occur when your backup storage is located offsite, your database is quite large, and the backup process generates a lot of files. This way, they won’t interfere with each other, enabling efficient parallel execution.
Fortunately, there are ways to skip the local storage entirely and stream MongoDB backups directly to the destination. At the same time, the common goal is to save both the network bandwidth and storage space (cost savings!) However, I find zstd way more efficient, so I’ll use it in the examples. 0 document(s) failed to restore.
Public accessibility enables and allows users to download, modify, and distribute the code. Further, open source databases can be modified in infinite ways, enabling institutions to meet their specific needs for data storage, retrieval, and processing. Additionally, it enables dynamic rows for table columns, which bolsters flexibility.
Linux native Input/Output (I/O) statistics Pipe viewer utility By following these approaches, we can effectively monitor the restoration process and manage your MySQL database restoration efficiently. Look for the ‘rchar’ field, representing the total bytes read from storage. Happy Monitoring!
Vacuum efficiency will improve as data resides in smaller partitions, reducing the time required for table maintenance compared to dealing with large sets of data. Download Percona Distribution for PostgreSQL Today! Query Performance will improve when dealing with partitioned data specifically.
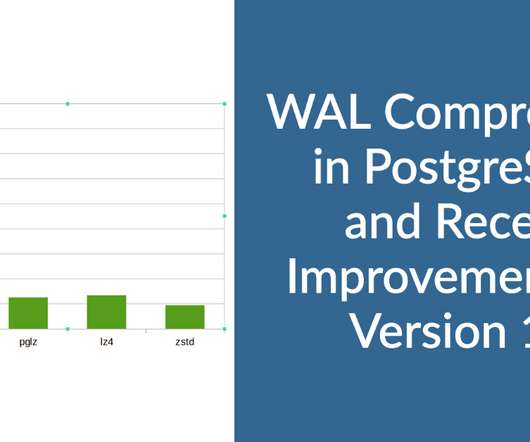
Summary Some of the key points/takeaways I have from the discussion in the community and as well as in my simple tests: The compression method pglz available in the older version was not very efficient. Download Percona Distribution for PostgreSQL Today! Modern compression algorithms and libraries are excellent.
Increased Storage Requirements : One of the disadvantages of full backups is the increased storage requirements due to the fact that they capture a complete copy of all data and files. This results in smaller backup sets, reducing storage requirements, time to take the backup, and network usage, as compared to full backups.
Mbps download speed Jake Archibald mentioned his relative getting or the 0.8 Mbps download speed my in-laws get at their house. Ballooning bandwidth and storage have fostered complacency that we can do without. My home internet connection gives me somewhere around 3 Mbps down. It seems blazingly fast compared to the 0.42
Download our free eBook, “ Why Choose Open Source? Look closely at your current infrastructure (hardware, storage, networks, etc.) start the installation process by downloading the distribution for your chosen platform and following the installation instructions provided by the vendor or as discussed in the open source community.
It progressed from “raw compute and storage” to “reimplementing key services in push-button fashion” to “becoming the backbone of AI work”—all under the umbrella of “renting time and storage on someone else’s computers.” ” (It will be easier to fit in the overhead storage.)
MongoDB is a non-relational document database that provides support for JSON-like storage. First released in 2009, it is the most used NoSQL database and has been downloaded more than 325 million times. This is more efficient than $regex but needs you to prepare in advance by adding text indexes to your data sets.
We could create a Complete event for every sample, with stacks, but even being more efficient than the output generated by perf, there is still a lot of overhead, especially from repeated stacks. The significant reduction in file size, from raw perf output to nflxprofile , allows for faster download time from external storage.
But while eminently capable of performing OLAP, it’s not quite as efficient. The CITUS columnar extension feature set includes: Highly compressed tables: Reduces storage requirements. The complete CITUS feature set which, except for the Columnar storage component, is not covered in this blog, includes: Distributed tables.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content