This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. So, stay tuned for more enhancements and features.
Looking at the frameworks documentation, we’re unable to find any reference to such a keyword. We also notice a reference to the top keyword in DefaultExcludedPatternsChecker.java#L39 , which is used across different interceptors to check if a given string matches one of the excluded patterns, according to the documentation.
It provides an easy way to select, integrate, and customize foundation models with enterprise data using techniques like retrieval-augmented generation (RAG), fine-tuning, or continued pre-training. Guardrail analysis: Detect hallucinations, track prompt injections, mitigate PII leakage, and ensure brand-safe outputs.
You can find additional deployment options in the OpenTelemetry demo documentation. For details, see Dynatrace API – Tokens and authentication in theDynatrace documentation. Traces, metrics, and logs are already well covered, but interesting enhancements are being made frequently, so stay tuned.
For more information, you can always check our documentation. Stay tuned for Part 2 of this series, where we’ll explore how to harness AI to elevate your dashboard to the next level. Not only can you select a metric, but you can also add multiple filters, use sorting, or directly apply calculations like average or sum.
This step lets you fine-tune your query to identify all matching data points, ensuring a thorough and accurate retrieval process. Check out the documentation for the Privacy Rights app. Stay tuned to our continuous improvements by checking the Privacy Rights documentation.
Dynatrace Documentation maintains a list of events, which will grow as we unlock new use cases. Stay tuned Currently, the API allows for the configuration of an event processing pipeline. What’s next Explore: See the analytics sample in our documentation , which is executable in the playground environment.
Read more about these options in Log Monitoring documentation. To fine-tune your masking settings, select the entity you want to adjust and leverage the entity-specific settings. Stay tuned to this Privacy Spotlight blog series to learn more about these continuous improvements.
The Dynatrace data-centric approach ensures compliance isn’t a burden; it’s an opportunity to fine-tune operations. Imagine a dashboard that whispers, “Hey, there’s a vulnerability brewing in Server Room B.” But here’s the twist: At Dynatrace, we don’t just preach; we listen.
We are introducing native support for document model like JSON into DynamoDB, the ability to add / remove global secondary indexes, adding more flexible scaling options, and increasing the item size limit to 400KB. NoSQL and Flexibility: Document Model. JSON-style document model enables customers to build services that are schema-less.
Dynatrace released Cloud Native Full Stack injection with a short list of temporary limitations — referenced in our documentation — which don’t apply to Classic Full Stack injection. First, go to the Monitor Kubernetes / OpenShift page in the Dynatrace web UI, as documented in help, and generate a deployment file (see the example below).
Check our Privacy Rights documentation to stay tuned to our continuous improvements. See documentation for Record deletion in Grail via API. Go to Documentation The post Privacy spotlight: Ensure compliance by hard deleting individual records in Grail appeared first on Dynatrace news.
Optimizing RabbitMQ requires clustering, queue management, and resource tuning to maintain stability and efficiency. Another example is document generation, where users submit files that RabbitMQ processes into PDFs before emailing them. RabbitMQ supports high message volumes but may experience performance drops under heavy loads.
What’s next Dynatrace will continue to monitor and fine-tune the cost-event detection algorithms used by cost monitors to ensure that notifications are accurate. For full details on how to get the most from them, please see our Cost monitor documentation. Simple configuration of cost notifications.
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. Chunk your documents from unstructured data sources, as usual in GraphRAG.
A GraphQL processor executes the user provided GraphQL query to fetch documents from the federated gateway. Writing an Avro schema for such a document is time consuming and error prone to do by hand. This index needs to be kept up-to-date with the data exposed by the various services in the federated graph in near-real time.
The necessary documentation for institutional knowledge transfer does not exist. Tune in to the full episode for more insights from Bannon on AI. Complicating things further, there’s an aging generation of developers who have not been backfilled.
Dynatrace has closely collaborated with Google Cloud to add support for Cloud SQL, MySQL, PostgreSQL, or SQL Server into Dynatrace solutions in addition to tuning existing functionality for optimal outcomes.
Once instrumented, enable Session Replay for crashes on mobile by following the guidelines in Dynatrace Documentation. This includes selecting the app to be instrumented, fine-tuning cost controls, and enabling users to opt-in to Session Replay recording.
We’re further extending the support of extensions for additional protocols and technologies, and improving the process of creating extensions, so be sure to stay tuned. documentation. Prometheus Data Source documentation. To start leveraging your Prometheus metrics in Dynatrace, please visit: Extension Framework 2.0
The challenges with service management included: Stale documentation OS Updates High cognitive overhead A lack of continuous testing Scaling Image Creation Our existing AMI baking tool Aminator does not support Windows so we had to leverage other tools. Services are more reliable, testable, and documented.
Check out further information in our SLO documentation. Stay tuned for the next blog post in this series to learn how to extend problem remediation beyond the feature flag mechanism and level up your software delivery by integrating Cloud Automation into your existing DevOps toolchain.
To stay tuned, keep an eye on our release notes. Enhanced API documentation for the latest OneAngent endpoint of the Deployment API. (APM-365055). Classic user sessions page end-of-life. We are deprecating the classic User sessions page soon and replacing it with a more powerful page for session segmentation. Application Security.
See documentation for monitoring logs with OneAgent , or see details in the OneAgent capability support matrix Install OneAgent to start monitoring logs on Linux s390 architecture What’s next Stay tuned for an upcoming blog post about log collection in OpenShift for Linux on IBM Z and LinuxONE.
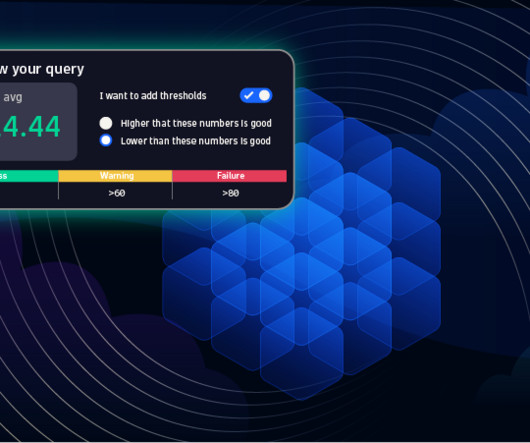
Once the learning phase is complete, all subsequent validation results are fed into Davis AI to fine-tune the thresholds based on changed behavior. For full details, see Dynatrace Documentation. It analyzes the next five validations to derive this objective’s proper warning and failure thresholds.
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Distributed Counter Abstraction To meet the outlined requirements, the Counter Abstraction was designed to be highly configurable. We hope you found this blog post insightful.
So, stay tuned. To learn more about OpenTelemetry and Dynatrace, see our Documentation and our “How to do OpenTelemetry with Dynatrace” webinar recording. We’re evolving the automated analysis of all enterprise application traces, metrics, and logs in context to supercharge observability.
In this post, we will discuss some important kernel parameters that can affect database server performance and how these should be tuned. The PostgreSQL documentation contains more information about shared memory configuration. The PostgreSQL documentation contains more information about shared memory configuration. Summing up.
Refer to F5 BIG-IP documentation for detailed and up-to-date instructions regarding remote Syslog configuration. Get more guidance for syslog configuration in documentation. Dynatrace OTel Collector was released in Preview in January and is available generally from March 2024.
You can read all about it in our Configuration as Code documentation. If Terraform is your tool of choice, please have a look at our Terraform provider documentation. Stay tuned for more examples and easy-to-adopt automations provided in our public Github project.
To stay tuned, keep an eye on our release notes. Log Monitoring documentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoring documentation to better focus on concepts and information that you, the user, look for and need. Legacy Log Monitoring v1 Documentation. Log Monitoring.
For details, see the OpenTelemetry demo application deployment documentation as a reference. Dynatrace documentation. Support for metrics will be extended in the near future, so stay tuned. To set up the demo, follow these steps: Step 1. Download the demo application. git clone [link]. cd opentelemetry-demo/.
Any scenario in which a student is looking for information that the corpus of documents can answer. Wrong document retrieval : Debug chunking strategy, retrieval method. For example, if youre building a document QA tool, upgrading from basic OCR to AI-powered extractionthink Mistral OCRmight give the biggest lift on your system!
The OpenTelemetry website provides detailed documentation for each language to guide you through the necessary steps to set up your environment. OpenTelemetry provides [extensive documentation]([link] and examples to help you fine-tune your configuration for maximum effectiveness.
We will further enhance the detection and blocking capability to cover additional attack types, so stay tuned for updates! To learn more, see Application Security in Dynatrace Documentation. This is one step towards delivering the promise of runtime application self-protection. How to get started.
To learn more about unified services, see Unified services in the Dynatrace documentation. Stay tuned for more improvements of OpenTelemetry and OneAgent analysis with the Grail data lakehouse. __ Many thanks to Arlino Lima and Matthew Reider for contributing to this article.
Prodicle Distribution Prodicle Distribution allows a production office coordinator to send secure, watermarked documents, such as scripts, to crew members as attachments or links, and track delivery. One distribution job might result in several thousand watermarked documents and links being created.
In a fuzzy diff setting, we might want to say that these sentences are too similar to highlight, but md5 and k-hot document encoding with kNN do not support that. Dense, low dimensional representations are really useful for short documents, like lines of a build or a system log. 0.3, -0.5, -0.7, 0.35, -0.5, -0.7,
For more information, please see our documentation for metric transformations and aggregations. With the new ingestion, it will be easier to import metrics into Dynatrace in a flexible and seamless way—stay tuned for more this year. Easily access all metadata for a selected metric.
The number of signal fluctuations and the sliding evaluation window for alerting allow you to further fine-tune alerting sensitivity. For more details, see our Auto-adaptive baselining for custom metric events documentation.
Such a template should contain a get-started tutorial, sample source-code framework, policy guardrails, CI/CD pipeline, infrastructure-as-code templates, and reference documentation. Allow for flexibility Custom query variables are available to fine-tune guardian objectives and maintain flexibility in fetching data from Grail.
See private locations documentation for further details and requirements. So stay tuned for more news about: Cluster-wide locations for Dynatrace Managed. A synthetic-enabled environment ActiveGate: ActiveGate version 1.173+. Windows 2016 Server (or a supported Linux distribution ). Compliance with hardware requirements.
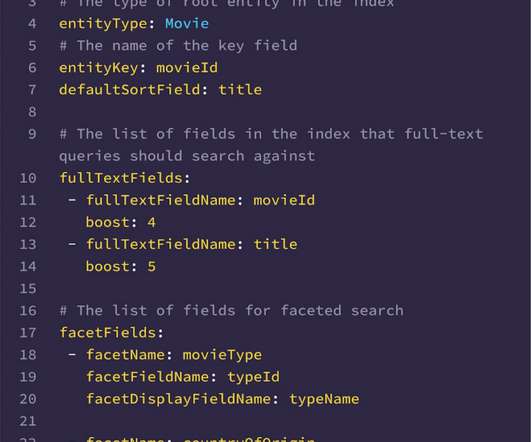
Since we index the data as-is from the federated graph, the indexing query itself acts as self-documentation. This integration with the federation gateway allows the search DGS to just return the matching entity keys from the search index instead of the whole matching document(s).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content