This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With an increasing number of regulations and standards governing how businesses handle data, an end-to-end compliance strategy is crucial. By ensuring that all processes—from data collection to storage and usage—comply with regulatory requirements, organizations can better manage potential threats. Want to learn more?
are stored in secure storage layers. Amsterdam is built on top of three storage layers. It provides simple APIs for creating indices, indexing or searching documents, which makes it easy to integrate. Mapping is used to define how documents and their fields are supposed to be stored and indexed. Net, Ruby, Perl etc.).
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods.
Unlike full backups that duplicate everything, incremental backups store only changes since the last save, reducing storage needs and speeding up recovery. Key Benefits: Smaller Storage Footprint: Saves only modified data, cutting down backup size. JSON_VALUE retrieves individual values from JSON documents.
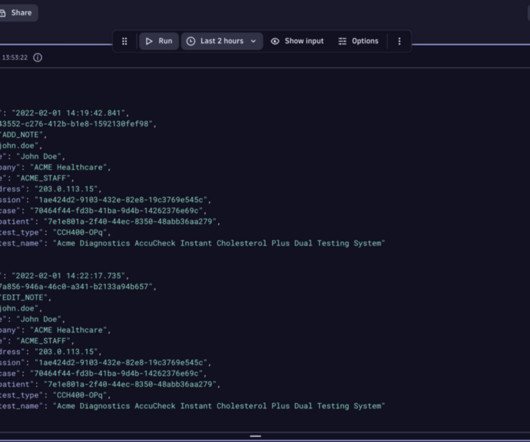
Strategically handle end-to-end data deletion Two key elements form the backbone of an effective deletion strategy in Dynatrace SaaS data management: retention-based and on-demand deletion. You can use the Grail Storage Record Deletion API to trigger a deletion request. To delete the records, use the Storage Record Deletion API.
JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. Note: If a particular key is always present in your document, it might make sense to store it as a first class column. JSONB storage results in a larger storage footprint. Nested objects.
Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. Distributed Event Streaming Platform RabbitMQ functions as a message broker, managing message confirmation, routing, storage, and delivery within a queue. What is RabbitMQ?
Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . Dynatrace root cause analysis documentation . Similarly, integrations for Azure and VMware are available to help you monitor your infrastructure both in the cloud and on-premises.
Some of our customers run tens of thousands of storage disks in parallel, all needing continuous resizing. Please see Davis Forecast analysis documentation to learn more about our AutoML approach and which algorithms are used within the Davis Forecast service. This can lead to hundreds of warnings and errors every week. What’s Next?
TimeSeries Abstraction The TimeSeries Abstraction was developed to meet these requirements, built around the following core design principles: Partitioned Data : Data is partitioned using a unique temporal partitioning strategy combined with an event bucketing approach to efficiently manage bursty workloads and streamline queries.
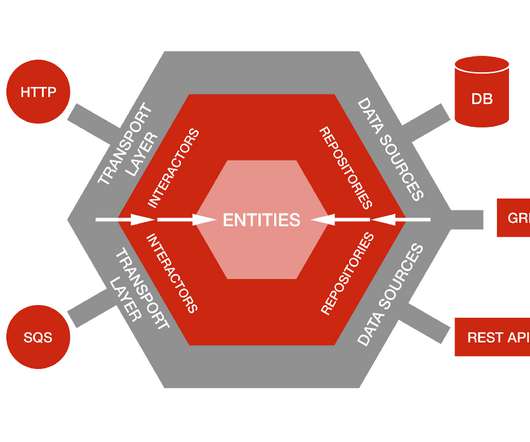
One of the main advantages we also saw in having an app with clear boundaries is our testing strategy?—?the Outside of the business logic are the Data Sources and the Transport Layer: Data Sources are adapters to different storage implementations. whether it be Relational or Documents.
As a leader in cloud infrastructure and platform services , the Google Cloud Platform is fast becoming an integral part of many enterprises’ cloud strategies. Google Cloud Storage. The installation process and architecture are well documented and described in the GitHub repository. Dynatrace news. Google Cloud Datastore.
It’s important to engage senior business leaders and position the value of Dynatrace SaaS in a way that aligns to their strategy and objectives. It’s important to start early, working backwards from these dates to identify when to initiate the discussion. Align to strategic initiatives. Reassure customers about their data.
Migrating Persistent Stores Stateful APIs pose unique challenges that require different strategies. This alternate migration strategy has proven effective for our systems that meet certain criteria. Continuous migration via Dual-writes: We utilize an active-active/dual-writes strategy to migrate the bulk of the data.
There is no need to think about schema and indexes, re-hydration, or hot/cold storage. OpenPipeline’s high-performance filtering and preprocessing provide full ingest and storage control for the Dynatrace platform. Keep in mind that Dynatrace Grail is schema-on-read and indexless, built with scaling in mind.
Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. They store data in various formats, including key-value pairs, documents, graphs, and column-family stores. Diverging from MySQLs methodology, MongoDB employs an architecture without fixed schemas.
These logs meticulously document every modification executed within the database in the data directory, providing essential incremental updates that facilitate time-specific recovery efforts. STATEMENT level – at which only SQL statements causing changes in data are documented succinctly.
Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . Dynatrace root cause analysis documentation . Similar ly, integrations for Azure and VMware are available to help you monitor your infrastructure both in the cloud and on-premises. .
In practice, session recording solutions make use of the document object model (DOM), which is a programming interface for web pages and document. Tools that feature client-side compression can help reduce total data transfer volumes and storage footprints. Develop a broad recording strategy. Are these costs consistent?
It’s a cross-platform document-oriented database that uses JSON-like documents with schema, and is leveraged broadly across startup apps up to enterprise-level businesses developing modern apps. MongoDB Replication Strategies. MongoDB is the #3 open source database and the #1 NoSQL database in the world.
Implementing pagination can be done using two primary strategies: offset-based and cursor-based methods. Offset-based involves utilizing functions such as skip , limit and a query which indicates how many documents should be skipped or returned at maximum. This can be expressed as db.collection_name.find().limit(number). limit(number).
If you want to read up on migration strategies check out my blog on 6-R Migration Strategies. In order to support these modernization strategies, it takes a more granular approach to dependency analysis as we have a more specific set of questions to answer: Which services do we actually have? These examples include e.g:
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads.
Source: OpenTelemetry Documentation. The data is incredibly plentiful and difficult to store over long periods due to capacity limitations — a reason why private and public cloud storage services have been a boon to DevOps teams. OpenTelemetry reference architecture. What is telemetry data? Monitoring begins here. Watch webinar now!
Encryption Strategies for RabbitMQ RabbitMQ implements transport-level security using TLS/SSL encryption to safeguard data during transmission. When persistent messages in RabbitMQ are encrypted, it ensures that even in the event of unsanctioned access to storage hardware, confidential information stays protected and secure.
Strategy: Choosing your path Having a strategy for your migration will make the move to open source go that much smoother. Your approach should align with your goals, abilities, and organizational requirements, and there are some common migration strategies for you to consider as you move forward.
To learn more about backup and restore types supported by PBM, visit our documentation. For the largest MongoDB clusters, the sheer amount of data impacts the backup strategy. You can learn more about using physical incremental backups with PBM in our documentation. Introducing incremental physical backups! Tech preview.
In this post, we cover the methods used to achieve an enterprise-grade backup strategy for the PostgreSQL cluster. Having a backup strategy in place that takes regular backups and has secure storage is essential to protect the database in an enterprise-grade environment to ensure its availability in the event of failures or disasters.
To aid our transition, we introduced another Cosmos microservice: the Document Conversion Service (DCS). Also, the Media Content Playback team, the Media Compute/Storage Infrastructure team and the entire Cosmos platform team that brought Cosmos to life and whole-heartedly supported us in our venture into Cosmos.
Therefore, establishing a strong backup strategy is essential to ensure data security and minimize potential disruptions. A full backup is a comprehensive data backup strategy that involves creating a complete, exact copy of all data and files in a database. Looking for a MongoDB backup solution? What is a full backup?
MongoDB is a non-relational document database that provides support for JSON-like storage. For example, we can use a $regex query on a collection of 10 million documents and use.explain(true) to view how many milliseconds the query takes. It provides a flexible data model allowing you to easily store unstructured data.
In this age of digital information, robust backup and recovery strategies are the pillars on which the stability of applications stands. In this blog, we will review all of the potential MySQL backup and restore strategies, the cornerstones of any application. There are two main different MySQL backup types: physical and logical.
Data-bearing members face a higher risk of encountering issues caused by rollbacks, compared to others who utilize different storage methods. Monitoring and Maintaining Replica Sets Ensuring the stability and consistency of your MongoDB replica sets is essential, even after implementing strategies to prevent and recover from rollbacks.
Configure the PostgreSQL hostname by editing configuration files and restarting the server, with secure storage of connection details to enhance security. Such a solution must be part of a broader strategy that includes proper network configuration, firewall settings, and regular security audits.
It progressed from “raw compute and storage” to “reimplementing key services in push-button fashion” to “becoming the backbone of AI work”—all under the umbrella of “renting time and storage on someone else’s computers.” A single document may represent thousands of features.
We are rapidly entering into an era where massive computing power, digital storage and global network connections can be deployed by anyone as quickly and easily as turning on the lights. One of the key themes of the ECP’s vision document is the call for a cloud computing framework that focuses on customers and empowers Europeans.
We’ll also discuss the costs and benefits of CDNs and dedicated file storage solutions. Together, we’ll develop an intuition for the strategies available to Django developers for serving these files to users worldwide in a secure, performant, and cost-effective manner. For more details, see the Django documentation. Media Files.
IndexedDB is an in-browser NoSQL storage system that you can use to cache and retrieve the required data to make your PWA work offline. The most straightforward way is to use Google’s Workbox tool, which includes numerous ready-made plugins for caching strategies. Suppose you want to define a custom caching strategy.
Invariably, the sagas that were at fault were examples of the scatter-gather pattern, and the ultimate culprit was contention at the storage level due to the optimistic concurrency strategy that was being used. If you want to get more of a general overview, the saga concurrency article in our documentation is a good starting place.
The key to a successful Cosmos DB system is its data partitioning strategy. Check out the documentation for more API options for advanced scenarios. In this strategy, message handlers for multiple messages can start processing concurrently, but the first one to commit their changes wins. In version 1.1
Scraping those product pages can net you invaluable data such as: The competitors’ pricing strategy. Cheerio allows us to select tags of an HTML document by using selectors: $("div"). The developer tools help us interactively explore the website’s Document Object Model (DOM). Large preview ). out of 5 stars' }.
That’s why it’s essential to implement the best practices and strategies for MongoDB database backups. In the absence of a proper backup strategy, the data can be lost forever, leading to significant financial and reputational damage. Why are MongoDB database backups important?
It takes you through the thinking processes and engineering practices behind the design of a key part of the control plane for AWS Elastic Block Storage (EBS): the Physalia database that stores configuration information. This paper is a real joy to read.
Otherwise, the storage engine does a scatter-gather and queries ALL partitions in a UNION that is not concurrent. This method distributes data evenly across partitions to achieve balanced storage and optimal query performance. Partitioning influences indexing strategies by narrowing the scope of indexing.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content