This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By ensuring that all processes—from data collection to storage and usage—comply with regulatory requirements, organizations can better manage potential threats. Read our documentation and explore how Dynatrace helps you address your regulatory and compliance requirements. Want to learn more? Ready to get started?
Using existing storage resources optimally is key to being able to capture the right data over time. Increased storage space availability. The compression of transaction data older than three days can free up to 50% more storage space in your Dynatrace Managed Cluster. Data compression is completed on June 12.
We are updating product documentation to include underlying static assumptions. Storage calculations assume that one terabyte consumes 1.2 Cloud storage is replicated twice, which doubles the energy consumption per terabyte. We implemented a wasted energy metric in the app to enhance practitioner actionability.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. Choosing the appropriate storage engine can have a significant impact on application performance.
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. Note: If a particular key is always present in your document, it might make sense to store it as a first class column. JSONB storage results in a larger storage footprint. Nested objects.
Masking at storage: Data is persistently masked upon ingestion into Dynatrace. Leverage three masking layers Masking at capture and masking at storage operations exclude targeted sensitive data points. Read more about these options in Log Monitoring documentation.
We are introducing native support for document model like JSON into DynamoDB, the ability to add / remove global secondary indexes, adding more flexible scaling options, and increasing the item size limit to 400KB. NoSQL and Flexibility: Document Model. JSON-style document model enables customers to build services that are schema-less.
The following figure depicts imaginary “evolution” of the major NoSQL system families, namely, Key-Value stores, BigTable-style databases, Document databases, Full Text Search Engines, and Graph databases: NoSQL Data Models. Document databases advance the BigTable model offering two significant improvements.
There are several limitations to store and fetch such data (all restrictions could be found in official documentation ). To resolve the problem it was suggested to find more suitable data storage. One day I faced the problem with downloading a relatively large binary data file from PostgreSQL.
Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. Message Broker vs. Distributed Event Streaming Platform RabbitMQ functions as a message broker, managing message confirmation, routing, storage, and delivery within a queue. What is RabbitMQ?
Cosmos DB is a multimodal database in Azure that supports schema-less storage. By default, Cosmos DB containers tend to index all the fields of a document uploaded. For key object storage, RU tends to be less, but it still depends on the payload size. Cosmos DB can be a good candidate for a key-value store.
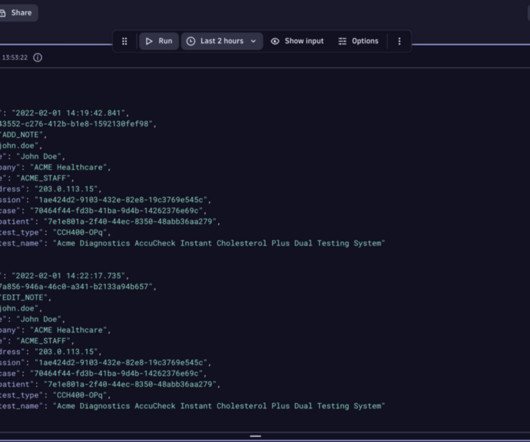
You can use the Grail Storage Record Deletion API to trigger a deletion request. To delete the records, use the Storage Record Deletion API. Check our Privacy Rights documentation to stay tuned to our continuous improvements. See documentation for Record deletion in Grail via API.
Grant users basic access to AppEngine AppEngine user policy This policy provides basic access to AppEngine to run apps and functions and access the main supporting services (such as the state service, document service, or document sharing). ALLOW app-engine:apps:run WHERE shared:app-id !=
Unlike full backups that duplicate everything, incremental backups store only changes since the last save, reducing storage needs and speeding up recovery. Key Benefits: Smaller Storage Footprint: Saves only modified data, cutting down backup size. JSON_VALUE retrieves individual values from JSON documents.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. It provides simple APIs for creating indices, indexing or searching documents, which makes it easy to integrate. Mapping is used to define how documents and their fields are supposed to be stored and indexed. Net, Ruby, Perl etc.).
Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . Dynatrace root cause analysis documentation . Similarly, integrations for Azure and VMware are available to help you monitor your infrastructure both in the cloud and on-premises.
Teams have introduced workarounds to reduce storage costs. Additionally, efforts such as lowered data retention times, two-tiered storage systems, shaky index management, sampled data, and data pipelines reduce the overall amount of stored data. Stop worrying about log data ingest and storage — start creating value instead.
Easier rollout thanks to log storage best practices. Easier rollout thanks to log storage best practices. The migration of the logs storage directory will happen automatically upon the update to OneAgent version 1.203; so there is really nothing you need to do. Advanced customization of OneAgent deployments made easy.
Streamline privacy requirements with flexible retention periods Data retention is a critical aspect of data handling, and it’s not just about privacy compliance—it’s about having the flexibility to optimize data storage times in Grail for your Dynatrace use cases. Other data types will be available soon). What’s next?
The full list of secure development controls, along with many more details, are documented at Dynatrace secure development controls. Every storage location involving data at rest is encrypted as well. Remote access to the Dynatrace corporate network requires multi-factor authentication (MFA). The diagram below provides an overview.
This means compromising between keeping data available as long as possible for analysis while juggling the costs and overhead of storage, archiving, and retrieval. Every API call is saved in audit logs to document the complete picture of activities in your environments.
You’re then presented with the Dynatrace Managed cluster deployment page, which contains basic information about Dynatrace, the solution itself, and a link to our documentation. We’re currently adding individual mount points for different storage types and separate disk setup for each of these storage types.
Remediation details are linked to the problem in Dynatrace and documented in ServiceNow. For more details, see the documentation , sign up for a trial , and download examples from the sample repository. It so initiates the remediation scenario to reset the canary weighting. Which implementation scenario is the right one for you?
To leverage the best of GKE Autopilot and cloud-native observability, Dynatrace and Google focused especially on Dynatrace’s innovative use of Container Storage Interface (CSI) pods. We use the Dynatrace Operator Helm chart to deploy Dynatrace Kubernetes Application observability as described in the documentation.
Among these, you can find essential elements of application and infrastructure stacks, from app gateways (like HAProxy), through app fabric (like RabbitMQ), to databases (like MongoDB) and storage systems (like NetApp, Consul, Memcached, and InfluxDB, just to name a few). documentation. Prometheus Data Source documentation.
Flexible Storage : The service is designed to integrate with various storage backends, including Apache Cassandra and Elasticsearch , allowing Netflix to customize storage solutions based on specific use case requirements. Note : With Cassandra 4.x
Buckets are similar to folders, a physical storage location. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Suppose a single Grail environment is central storage for pre-production and production systems.
AWS AppFabric ingests and normalizes audit logs from SaaS applications and delivers them to an Amazon Simple storage service (Amazon S3) bucket in an organization’s AWS account. To learn more, visit the DQL guide documentation. To connect your SaaS applications to AWS AppFabric, follow the getting started documentation.
Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures. “Logs magnify these issues by far due to their volatile structure, the massive storage needed to process them, and due to potential gold hidden in their content,” Pawlowski said, highlighting the importance of log analysis.
AWS Storage Gateway. You can refer to Dynatrace documentation for detailed information and requirements. Amazon Managed Apache Cassandra Service (Keyspaces). Amazon Managed Streaming for Apache Kafka. Amazon SageMaker. AWS Step Functions. AWS OpsWorks. ACM Private CA. Amazon Transfer Family. Amazon Route 53. AWS Service Catalog.
There is no need to think about schema and indexes, re-hydration, or hot/cold storage. OpenPipeline’s high-performance filtering and preprocessing provide full ingest and storage control for the Dynatrace platform. Keep in mind that Dynatrace Grail is schema-on-read and indexless, built with scaling in mind.
Google Cloud Storage. The installation process and architecture are well documented and described in the GitHub repository. The Dynatrace solution installs predefined dashboards for the following services: Google Cloud SQL. Google Cloud Datastore. Google Cloud Load Balancing. Google Cloud Pub/Sub. Google Cloud Filestore.
In this blog post, you will learn: how to leverage FDE on Kubernetes with Percona Operator for PostgreSQL how to start using encrypted storage for already running cluster Prepare In most public clouds, block storage is not encrypted by default. The configuration of the storage class depends on your storage plugin.
Log Monitoring documentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoring documentation to better focus on concepts and information that you, the user, look for and need. Legacy Log Monitoring v1 Documentation. Improved error handling for unexpected storage issues. (APM-360014).
Compliance, retention, archiving, or data governance regulations often require multicasting logs from the original source to multiple destinations, like an observability platform with long-term log storage. Refer to F5 BIG-IP documentation for detailed and up-to-date instructions regarding remote Syslog configuration.
He explained how those concerns can be allayed by discussing types of data the customer already stores in the cloud, showing how Managed clusters can be kept online for long term storage, and outlining the security certifications and standards that Dynatrace adheres to. Start small if you need to.
Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. They store data in various formats, including key-value pairs, documents, graphs, and column-family stores. Diverging from MySQLs methodology, MongoDB employs an architecture without fixed schemas.
Objectives Modern AI innovations require proper infrastructure, especially concerning data throughput and storage capabilities. While GPUs drive faster results, legacy storage solutions often lag behind, causing inefficient resource utilization and extended times in completing the project.
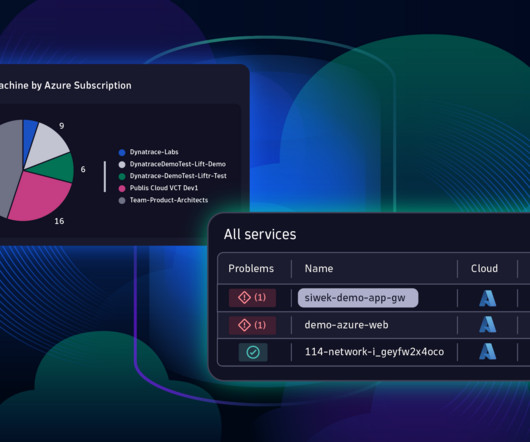
Set up complete monitoring for your Azure subscription with Azure Monitor integration After activating the Azure Native Dynatrace Service (see Dynatrace Documentation for details), the Azure Monitor integration is enabled easily via the Microsoft Azure Portal, as shown in the following screenshot.
Redis is an in-memory key-value store and cache that simplifies processing, storage, and interaction with data in Kubernetes environments. Accordingly, for classic database use cases, organizations use a variety of relational databases and document stores. Databases : Among databases, Redis is the most used at 60%.
AWS offers a broad set of global, cloud-based services including computing, storage, networking, Internet of Things (IoT), and many others. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon Simple Storage Service (S3). Dynatrace news. Amazon CloudFront. Amazon Cognito. Amazon EC2 Spot Fleet. Amazon EMR.
Some of our customers run tens of thousands of storage disks in parallel, all needing continuous resizing. Please see Davis Forecast analysis documentation to learn more about our AutoML approach and which algorithms are used within the Davis Forecast service. This can lead to hundreds of warnings and errors every week. What’s Next?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content