This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Consolidate real-user monitoring, synthetic monitoring, session replay, observability, and business process analytics tools into a unified platform. Real-time customer experience remediation identifies and informs the organization about any issues and prevents them in the experience process sooner.
A high-level overview of how an attacker can exploit a CVE-2024-53677 vulnerable Struts application to upload a web shell into a web-accessible directory and then remotely execute commands on the web server via the web shell. This allows developers to easily access and process the file without handling the upload mechanics directly.
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Introducing sufficient jitter to the flush process can further reduce contention. This process can also be used to track the provenance of increments.
As every developer knows, logs are crucial for uncovering insights and detecting fundamental flaws, such as process crashes or exceptions. Using Live Debugger, we immediately get insights into the running code, including variable values, process and thread information, and even a trace ID for the captured transaction.
Whether a web server, mobile app, backend service, or other custom application, log data can provide you with deep insights into your software’s operations and events. Advanced processing on your observability platform unlocks the full value of log data. See Dynatrace Documentation for support and to browse the numerous examples.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Improved Vacuuming: A redesigned memory structure lowers resource use and speeds up the vacuum process. JSON_VALUE retrieves individual values from JSON documents.
Serverless architecture shifts application hosting functions away from local servers onto those managed by providers. This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Improving data processing. Boosting batch processing.
The following figure depicts imaginary “evolution” of the major NoSQL system families, namely, Key-Value stores, BigTable-style databases, Document databases, Full Text Search Engines, and Graph databases: NoSQL Data Models. Document databases advance the BigTable model offering two significant improvements.
KeyCDN has significantly simplified the way images are transformed and delivered with our Image Processing service. Our solution doesn't require any change on the origin server. Our Image Processing service makes it easy to do that. WebP delivery doesn't require any change on the origin server with the WebP caching feature.
Given such a scenario, MySQL documentation recommends that the crashed master must be discarded and should not be restarted. However, discarding a server like this is expensive and inefficient. Re-Slaving a Crashed #MySQL Master Server in Semisynchronous Replication Setup Click To Tweet.
Track changes via our change management process. The full list of secure development controls, along with many more details, are documented at Dynatrace secure development controls. These certificates are stored on physical devices which are plugged into specifically hardened build servers. Ensure manual penetration testing.
But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . OneAgent and its Operator .
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
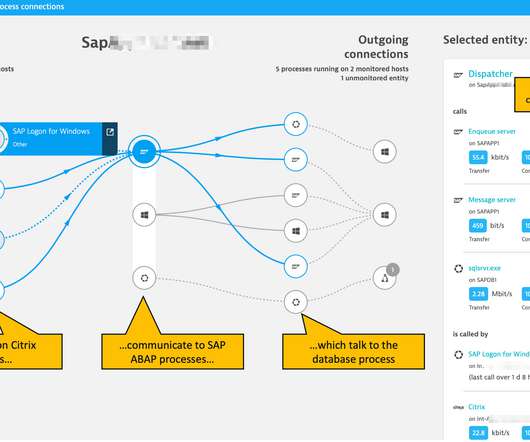
As of today, the SAP ABAP application server remains the central component of the SAP ERP solution. The ABAP platform monitoring solution is based on the remote monitoring approach and so relies on a Dynatrace ActiveGate extension: No agent installation on SAP servers is required. SAP technology and process awareness.
Logs include critical information that can’t be found elsewhere, like details on transactions, processes, users, and environment changes. Automatic contextualization of log data works out-of-the-box for popular languages like Java,NET, Node.js, Go, and PHP, as well as for NGiNX and Apache Web servers. New to Dynatrace?
This includes digging through each monitored data source and adding tags to the sensitive data points; this process is usually expensive, exhausting, error-prone, and unscalable. Read more about these options in Log Monitoring documentation. See the process-group settings example in the screengrab below.
This critical flaw allows for a path traversal attack, enabling attackers to upload malicious files and potentially execute arbitrary code on the server. To handle the challenging and time-consuming process of collecting, processing, and analyzing this information, we automated it with an LLM-based multi-agent framework.
With its ability to handle SSL offloading, distribute traffic across multiple servers, and provide security features like DDoS protection, application firewall, and SSL VPN, organizations of all sizes rely on F5 BIG-IP LTM to improve application performance, availability, and security. Example F5 overview dashboard.
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. Let’s explore each of these elements and what organizations can do to avoid them.
As of today, the SAP ABAP application server remains the central component of the SAP ERP solution. The ABAP platform monitoring solution is based on the remote monitoring approach and so relies on a Dynatrace ActiveGate extension: No agent installation on SAP servers is required. SAP technology and process awareness.
In that environment, the first PostgreSQL developers decided forking a process for each connection to the database is the safest choice. It is difficult to fault their argument – as it’s absolutely true that: Each client having its own process prevents a poorly behaving client from crashing the entire database.
While Google’s SRE Handbook mostly focuses on the production use case for SLIs/SLOs, Keptn is “Shifting-Left” this approach and using SLIs/SLOs to enforce Quality Gates as part of your progressive delivery process. This will enable deep monitoring of those Java,NET, Node, processes as well as your web servers.
“As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. As a result, IT teams often end up performing time-consuming, manual processes. Minimize overall documentation. Because configuration files form a single source of truth, they require minimal documentation.
Multiple Prometheus servers might be required, creating significant maintenance efforts. Alternatively, if you’re already using a Prometheus Server to gather data from your distributed systems, you can now seamlessly make this data work for you in Dynatrace as well—use your Prometheus server as the endpoint for scraping metrics.
When visiting or relocating to another country, you must go through the local Visa process, which is often done through an online portal ahead of your trip. More worrisome was a spike in CPU usage, resulting in severe service disruption as backend processing systems crashed due to the spike in load. Dynatrace news.
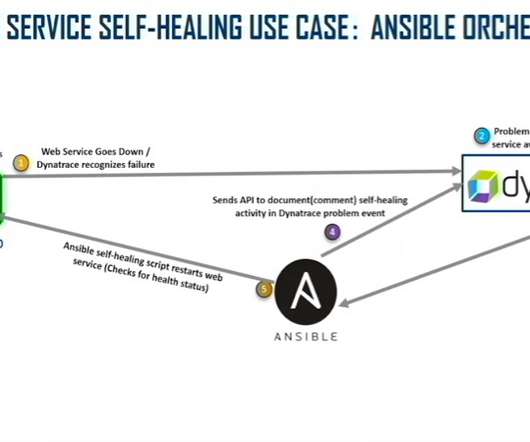
At Dynatrace Perform 2022 , David Walker, a Lockheed Martin Fellow, and William Swofford, a full-stack engineer at Lockheed Martin, discuss how to create a self-diagnosing and self-healing IT server environment using this AIOps combination for auto-baselining, auto-remediation, monitoring as code, and more. An example of the self-healing web.
By batching and parallelizing the requests to retrieve many creatives via a single query to the GraphQL server, we can optimize the index building process. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index. The graph has two requirements.
Baking Windows with Packer By Justin Phelps and Manuel Correa Customizing Windows images at Netflix was a manual, error-prone, and time consuming process. We looked at our process for creating a Windows AMI and discovered it was error-prone and full of toil. Last year, we decided to improve the AMI baking process.
This is not a general rule, but as databases are responsible for a core layer of any IT system – data storage and processing — they require reliability. Why choose Percona Server for MongoDB? Why release Percona Server for MongoDB 7 now? which was released as Percona Server for MongoDB RC 7.0.2-1.
Dynatrace has announced that it has successfully achieved the Google Cloud Ready – Cloud SQL designation for Cloud SQL, Google Cloud’s fully-managed, relational database service for MySQL, PostgreSQL, and SQL Server.
With PowerConnect, collecting data from SAP systems and fueling the Dynatrace platform, Dynatrace automatically uncovers the topology model of the SAP landscape, providing a clear and comprehensive view of the relationships and dependencies among different systems, servers, databases, applications, and interfaces.
Rethinking Server-Timing As A Critical Monitoring Tool. Rethinking Server-Timing As A Critical Monitoring Tool. In the world of HTTP Headers, there is one header that I believe deserves more air-time and that is the Server-Timing header. Setting Server-Timing. Sean Roberts. 2022-05-16T10:00:00+00:00.
Log Monitoring documentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoring documentation to better focus on concepts and information that you, the user, look for and need. Legacy Log Monitoring v1 Documentation. This will happen with Dynatrace version 1.242 or later. Log Monitoring.
Remediation tracking now enables you to view the risk assessment for the process groups affected by a vulnerability. Enhanced API documentation for the latest OneAngent endpoint of the Deployment API. (APM-365055). Fixed an issue with “500 Internal Server Error” response of Anomaly detection – Disk events API. (APM-370270).
In this case, the server appears to be continuously building responses, which is an expensive operation that indicates either we have a bug in the revision calculation of our message handler, or the list of ActiveGates is constantly changing, forcing frequent revision recalculation. The handler is responsible for ~3.5
On-premises data centers invest in higher capacity servers since they provide more flexibility in the long run, while the procurement price of hardware is only one of many cost factors. Redis is an in-memory key-value store and cache that simplifies processing, storage, and interaction with data in Kubernetes environments.
For example, a cluster utilization of 50% should allow you to roughly double the currently processed load before the cluster reaches its maximum capacity. trace processing?provides User actions processed per minute shows you the trend of user actions that are successfully processed, correlated with server-side?
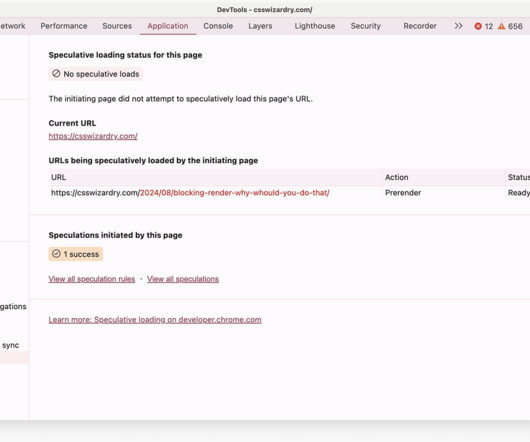
None of the target URL’s subresources are fetched, and no processing of the response is done. prefetch is much more light-touch than… prerender : This will fetch the target URL and its subresources, as well as parse and render the resulting page, and process timers, scripts, etc. prerender is much more intensive.
Whenever you install your favorite MySQL server on a freshly created Ubuntu instance, you start by updating the configuration for MySQL, such as configuring buffer pool, changing the default datadir director, and disabling one of the most outstanding features – query cache. It’s a nice thing to do, but first things first.
The EMCA recently implemented a new monitoring approval process, which breaks down details such as how a system functions, how information is being shared, and the overall software capabilities. The ECMA has created “cloud teams” to aid in the application monitoring process.
Replay traffic testing gives us the initial foundation of validation, but as our migration process unfolds, we are met with the need for a carefully controlled migration process. A process that doesn’t just minimize risk, but also facilitates a continuous evaluation of the rollout’s impact.
The time from browser request to the first byte of information from the server. Document these metrics, including the benchmark values and any insights gained from analysis, to use as a reference for tracking progress and evaluating the effectiveness of optimization efforts over time. The time taken to complete the page load.
This means Dynatrace isn’t collecting the metrics on the Prometheus server, but directly at the source of truth – the exporters. Additionally, you don’t have to worry about scaling the Prometheus infrastructure because doesn’t even have to be collected by the Prometheus server. The new can collect metrics exposed by your exporters.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content