This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
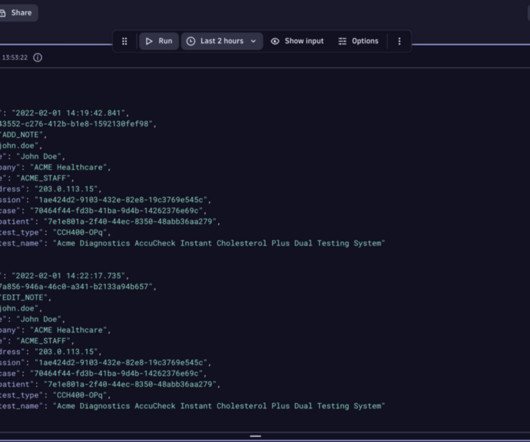
Dynatrace Simple Workflows make this process automatic and frictionlessthere is no additional cost for workflows. Why manual alerting falls short As your product and deployments scale horizontally and vertically, the sheer volume of data makes it impossible for teams to catch every error quickly using manual processes.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
At roughly 10 thousand public documents scanned every minute , this eventually led to a bottleneck. In a gearbox, if you want to increase torque, you need to decrease speed. So it wasn’t a surprise to find that our engine had the same problem: more power, less speed.
Consolidate real-user monitoring, synthetic monitoring, session replay, observability, and business process analytics tools into a unified platform. Real-time customer experience remediation identifies and informs the organization about any issues and prevents them in the experience process sooner.
You can also create individual reports using Notebooks —or export your data as CSV—and share it with your financial teams for further processing. Head over to Dynatrace Documentation to learn more about how to set up cost allocation in your environment. Support for additional capabilities will be added in the future.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
This blog post dissects the vulnerability, explains how Struts processes file uploads, details the exploit mechanics, and outlines mitigation strategies. This allows developers to easily access and process the file without handling the upload mechanics directly. Complete mitigation is only guaranteed in Struts version 7.0.0
For more information, go to our IAM policy boundaries documentation. Adopt the new Dynatrace security policies today Go to Dynatrace Documentation for complete information about these enhancements to Dynatrace access management and how you can benefit from them. Create a new policy boundary in the new user group management web UI.
Retaining multiple tools generates huge volumes of alerts for analysis and action, slowing down the remediation and risk mitigation processes. Then, document the specifics of your desired end state. This should help you proactively address issues in real time and eliminate manual, error-prone processes.
As every developer knows, logs are crucial for uncovering insights and detecting fundamental flaws, such as process crashes or exceptions. Using Live Debugger, we immediately get insights into the running code, including variable values, process and thread information, and even a trace ID for the captured transaction.
Advanced processing on your observability platform unlocks the full value of log data. Dynatrace now includes powerful log-processing capabilities for all types of log data. Log data is processed on ingest, whether coming from a fleet of OneAgents deployed across your enterprise hosts or generic API ingest from cloud services.
By ensuring that all processes—from data collection to storage and usage—comply with regulatory requirements, organizations can better manage potential threats. Streamlined audits: End-to-end compliance simplifies the audit process. Retention periods and access controls must be properly configured to protect such PII.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. You can even walk through the same example above.
However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals. By recognizing the insights provided, you can optimize processes and improve overall efficiency.
Workflows serves as the automation engine to efficiently process and triage the security findings, create working tickets for your DevSecOps teams, and send notifications to the relevant stakeholders. Also, visit Dynatrace Documentation to set up your integration and explore sample use cases.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. Actions resulting from the evaluation The certification process surfaced a few recommendations for improving the app.
This combination allows a malicious actor with local administrative privileges on a virtual machine to execute code as the virtual machine’s VMX process running on the host. It allows a malicious actor with privileges within the VMX process to trigger an arbitrary kernel write, which can lead to an escape from the sandbox.
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Introducing sufficient jitter to the flush process can further reduce contention. This process can also be used to track the provenance of increments.
Events are processed, mapped to the Dynatrace Semantic Dictionary in OpenPipeline , and stored in Grail . As part of this integration, we provide ready-made documents that can serve as a starting point for your data analysis and automation use cases. Ready to explore the Dynatrace Harbor integration for yourself?
Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. Take a look at two interesting examples of this pattern in the documentation. Try it athome It couldnt be easier to get started with Configs!Just
Key Steps in the Integration Process Container image scanning AWS ECR scans container images for vulnerabilities. For instructions, see the documentation. You can choose between basic and enhanced scanning. You can set it up using an AWS CloudFormation template provided by Dynatrace. Explore the AWS ECR integration in Dynatrace Hub.
This means high-frequency streamed logs from Firehose can be captured in your Dynatrace environment, automatically processed, stored in Grail for the retention period of your choice, and included in the full observability automation suite of the Dynatrace® platform, apps, and Davis ® AI problem detection.
You can read more about workflow triggers in Workflow schedule trigger documentation. OpenPipeline allows you to create custom endpoints for data ingestion and process the events in the pipeline (for example, adding custom pipe-dependent fields to simplify data analysis in a later phase).
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Improved Vacuuming: A redesigned memory structure lowers resource use and speeds up the vacuum process. JSON_VALUE retrieves individual values from JSON documents.
Dynatrace Grail™ is a data lakehouse optimized for high performance, automated data collection and processing, and queries of petabytes of data in real time. Another consideration is compliance with end-user privacy rights to delete personal data processed about them in line with data protection laws like GDPR and CCPA.
Across the globe, privacy laws grant individuals data subject rights, such as the right to access and delete personal data processed about them. 2] — Nader Henein, VP Analyst, Gartner The Privacy Rights app is designed to streamline this process in Dynatrace. Check out the documentation for the Privacy Rights app.
Amazon compute solutions are designed to streamline resource provisioning and container management with two services: AWS Lambda : Lambda provides serverless compute infrastructure that lets you run code in response to predetermined events or conditions and automatically manage all compute resources required for these processes.
You can find additional deployment options in the OpenTelemetry demo documentation. For details, see Dynatrace API – Tokens and authentication in theDynatrace documentation. To set up the demo using Docker , follow the steps below. If you don’t have one, you can use a trial account.
If something goes wrong at this stage, the impact will be amplified throughout the software testing process. It is a key document that contains a set of procedures and conditions that must be followed on the software app in order to confirm the feature's intended performance and usefulness. What Are Test Cases in Software Testing.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . OneAgent and its Operator .
Your one-stop shop for discovering, learning, and activating monitoring Dynatrace Hubacts as the central entry point to the Dynatrace platform, simplifying the onboarding process for new customers and helping existing customers stay updated with the latest features. Of course, seeing is believing.
Well, the MySQL documentation provides a straightforward answer to this, quoting: InnoDB processes SELECT COUNT(*) statements by traversing the smallest available secondary index unless an index or optimizer hint directs the optimizer to use a different index. What index will be used when you count all rows in a table?
A GraphQL processor executes the user provided GraphQL query to fetch documents from the federated gateway. Writing an Avro schema for such a document is time consuming and error prone to do by hand. This index needs to be kept up-to-date with the data exposed by the various services in the federated graph in near-real time.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. While the overall process may be more complicated in practice, this is the gist. One more embellishment is to use a graph neural network (GNN) trained on the documents. at Facebook—both from 2020.
View segmentation The Vulnerabilities app utilizes a cross-platform segmentation feature that helps you focus on specific areas of your environment: Slice environments into categories like process groups, applications, or even individual services. Please see the instructions in Dynatrace Documentation. Not a Dynatrace customer yet?
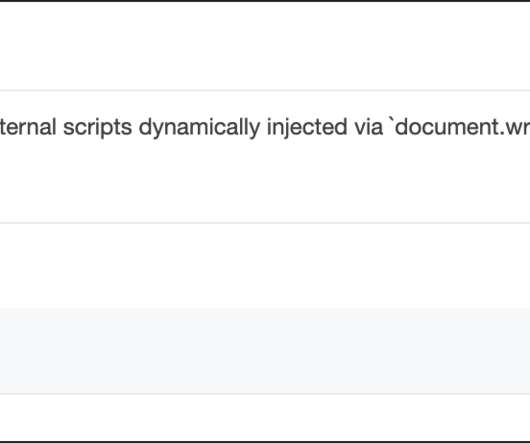
The Preload Scanner and the primary parser begin processing the HTML at more-or-less the same time, so the Preload Scanner doesn’t really get much of a head start. Because the Preload Scanner deals with tokeniseable src and href attributes, anything buried in JavaScript is invisible to it: document. src = ' file.js ' ; document.
The risk of impact from an existing known vulnerability also depends on whether certain processes are using the vulnerable parts of a software component. Process group 1 doesn’t use the function that contains the vulnerability. The vulnerable function in the software package is highlighted in red. an RCE vulnerability.
To handle the challenging and time-consuming process of collecting, processing, and analyzing this information, we automated it with an LLM-based multi-agent framework. Additionally, we searched and analyzed multiple security blogs and forums for expert insights and further detailed analysis of vulnerabilities.
Track changes via our change management process. The full list of secure development controls, along with many more details, are documented at Dynatrace secure development controls. The signatures are automatically verified during the update process on the customer infrastructure. Automatically run thousands of automated tests.
To support using these building blocks, we provide you with our Dynatrace Developer documentation , which acts as a one-stop shop for all information about creating a Dynatrace custom app. Perhaps the documentation does not solve your problem, you have an error, or you can’t find the answer.
The adoption process takes time and consideration. If an unhealthy workload is owned by another team, having access to the provided ownership information enables engineers to promptly notify the correct team, ensuring a faster, more efficient resolution process. You can find out more about the Kubernetes app in Dynatrace Documentation.
Dynatrace released Cloud Native Full Stack injection with a short list of temporary limitations — referenced in our documentation — which don’t apply to Classic Full Stack injection. First, go to the Monitor Kubernetes / OpenShift page in the Dynatrace web UI, as documented in help, and generate a deployment file (see the example below).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content