This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Why browser and HTTP monitors might not be sufficient In modern IT environments, which are complex and dynamically changing, you often need deeper insights into the Transport or Network layers. Is it a bug in the codebase, a malfunctioning backend service, an overloaded hosting infrastructure, or perhaps a misconfigured network?
Time To First Byte: Beyond Server Response Time Time To First Byte: Beyond Server Response Time Matt Zeunert 2025-02-12T17:00:00+00:00 2025-02-13T01:34:15+00:00 This article is sponsored by DebugBear Loading your website HTML quickly has a big impact on visitor experience. TCP: Establishing a reliable connection to the server.
Host Monitoring dashboards offer real-time visibility into the health and performance of servers and network infrastructure, enabling proactive issue detection and resolution. This information is crucial for identifying network issues, troubleshooting connectivity problems, and ensuring reliable domain name resolution.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. A local endpoint in a protected network or DMZ is required to capture these messages. Read syslog ingestion documentation with configuration samples.
Like the driver documentation says, this is not recommended as it makes the connection susceptible to man-in-the-middle attacks. 1305:12 @(shell):1:1 2019-04-18T19:44:42.261+0530 I NETWORK [thread1] trying reconnect to SG-example-1.servers.mongodirector.com:27017 Testing Failover Behavior. 185:1 rs.stepDown@src/mongo/shell/utils.js:1305:12
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. Let’s explore each of these elements and what organizations can do to avoid them.
Access to source code repositories is limited on both the network and the user level. Source code management systems are only accessible from within the Dynatrace corporate network. Remote access to the Dynatrace corporate network requires multi-factor authentication (MFA). The diagram below provides an overview.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. The LTM pool members represent your application and web servers, which can be effortlessly monitored with OneAgent ®. Example F5 overview dashboard.
Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . Dynatrace root cause analysis documentation . When using autoscaling-mechanisms and having a lot of application containers, tracing requests through the network is a challenging task.
Getting insights into the health and disruptions of your networking or infrastructure is fundamental to enterprise observability. Syslog is a protocol with clear specifications that require a dedicated syslog server. Refer to F5 BIG-IP documentation for detailed and up-to-date instructions regarding remote Syslog configuration.
eBPF has been running in production for over half a decade at an internet scale on millions of servers. eBPF use cases range from observability, networking, security, tracing, and profiling. You'll see the term BPF in Linux source code, and you'll see BPF and eBPF used interchangeably in tooling and documentation.
They collect data from multiple sources through real user monitoring , synthetic monitoring, network monitoring, and application performance monitoring systems. The time from browser request to the first byte of information from the server. The time taken to complete the page load. Time to first byte. Time to render. Visually complete.
The possible navigation types are: Navigate: A hard navigation that resulted in an HTML page being fetched from the network. Navigate 70% of page views are Navigations , which means a user landed on them via a hard navigation and the file was fetched from the network. Cache: An HTML response returned from the HTTP cache.
In this case, the server appears to be continuously building responses, which is an expensive operation that indicates either we have a bug in the revision calculation of our message handler, or the list of ActiveGates is constantly changing, forcing frequent revision recalculation.
Since December 10, days after a critical vulnerability known as Log4Shell was discovered in servers supporting the game Minecraft, millions of exploit attempts have been made of the Log4j 2 Java library, according to one team tracking the impact, with potential threat to millions more applications and devices across the globe. Dynatrace news.
Concatenating our files on the server: Are we going to send many smaller files, or are we going to send one monolithic file? Compressing them over the network: Which compression algorithm, if any, will we use? Connection One thing we haven’t looked at is the impact of network speeds on these outcomes. Client There’s a fifth C !
Puppet software can be used to automate the management and configuration of your servers, including instrumentation for Dynatrace monitoring. The Dynatrace Puppet module is a natural next step in our support for automated server management and configuration. Why waste time on something that can be automated or scripted?
Rethinking Server-Timing As A Critical Monitoring Tool. Rethinking Server-Timing As A Critical Monitoring Tool. In the world of HTTP Headers, there is one header that I believe deserves more air-time and that is the Server-Timing header. Setting Server-Timing. Sean Roberts. 2022-05-16T10:00:00+00:00.
I can reload the exact same page under the exact same network conditions over and over, and I can guarantee I will not get the exact same, say, DOMContentLoaded each time. What if another file on the critical path had dropped out of cache and needed fetching from the network? There are myriad reasons for this that I won’t cover here.
With PowerConnect, collecting data from SAP systems and fueling the Dynatrace platform, Dynatrace automatically uncovers the topology model of the SAP landscape, providing a clear and comprehensive view of the relationships and dependencies among different systems, servers, databases, applications, and interfaces.
Dynatrace dashboards serve as a single pane of glass for monitoring artifacts like metrics, logs, events, user sessions, and server-side traces. Important : In Dynatrace Managed environments, you need to configure an additional Network scope setting. What you get with this update.
Migrating to cloud-based operations from a traditional on-premises networked system also requires artificial intelligence and end-to-end observability of the full software stack. Software factories: integrating AI to standardize cloud monitoring.
Let’s walk through the steps involved in installing and configuring the Prometheus server to store and display the metrics, an exporter (MySQL Exporter in this case) to collect the metrics and relay them to the Prometheus server, and Grafana to create dashboards. Prometheus requires an exporter for collecting MySQL server metrics.
Some aspects are just easy to grasp as they are well defined in the operator custom resources and documentation, but some are often considered to be a hidden craft. Network exposure in cases of sharded clusters is quite straightforward, […]
In this blog, we will discuss both data and network-level compression offered in MongoDB. We will discuss snappy and zstd for data block and zstd compression in a network. Percona Server for MongoDB (PSMDB) supports all types of compression and enterprise-grade features for free. I am using PSMDB 6.0.4
The value of SBM, as explained in the MySQL documentation , depends on the state of the MySQL slave in general, and the states of MySQL slave SQL_THREAD and IO_THREAD in particular. Lastly, it’s important to note that in our discussions so far, we have not assumed any network bottlenecks. Possible Values of Seconds Behind Master.
Dynatrace VMware and virtualization documentation . Dynatrace Kubernetes documentation . Dynatrace OneAgent documentation . Dynatrace root cause analysis documentation . When using autoscaling-mechanisms and having a lot of application containers, tracing requests through the network is a challenging task.
Should have an excellent way to measure server and query performance. SQL Import/Export that supports major databases: Oracle, SQL Server, MySQL, and PostgreSQL. Import data from RDBMS like MySQL, PostgreSQL, and SQL Server. Similarly, you can export data from MongoDB to MySQL, PostgreSQL, SQL Server, and Oracle.
This means Dynatrace isn’t collecting the metrics on the Prometheus server, but directly at the source of truth – the exporters. Additionally, you don’t have to worry about scaling the Prometheus infrastructure because doesn’t even have to be collected by the Prometheus server. The new can collect metrics exposed by your exporters.
Our default settings work well for most SSO servers that utilize the SAML protocol. Available options include: document , assertion , both , or none. Backup process was improved to not utilize all available host network and CPU resources. More flexible SAML configuration. Two algorithms are available: SHA-256 and SHA-1.
Key Components in SIEM Log Collection: SEIM systems collect and aggregate log data from Various sources across an organization’s network, including servers, endpoints, firewalls, applications, and other devices. They offer capabilities for tracking and documenting security incidents from detection to resolution.
Kafka clusters can be deployed in Kubernetes using Helm charts to simplify scaling and management across multiple servers. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. RabbitMQ ensures fast message delivery when queues are not overloaded.
Measuring Performance With Server Timing. Measuring Performance With Server Timing. That issue is slow server response times. There’s very little browser optimisations can do to improve a page that is simply slow to build on the server. Encompassed in that wait time is everything the server needs to do to build the page.
While most of our cloud & platform partners have their own dependency analysis tooling, most of them focus on basic dependency detection based on network connection analysis between hosts. What is the network traffic going to be between services we migrate and those that have to stay in the current data center?
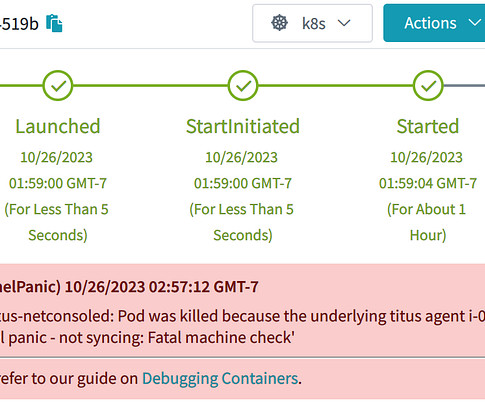
When this happens, usually a k8s cloud-controller provided by the cloud vendor will detect that the actual server, in our case an EC2 Instance, has actually gone away, and will in turn delete the k8s node object. The annotations help document what happened to the node & pod: A real pod lost on a real k8s node that had a real kernel panic!
Having the ability to monitor the performance and availability of your organization’s internal applications—in addition to your organization’s customer-facing applications—from within your corporate network is an important benefit of synthetic monitoring. Windows 2016 Server (or a supported Linux distribution ).
AWS will contribute code and improved documentation as well as invest in the ecosystem around MXNet. MXNet is a fully featured, flexibly programmable, and ultra-scalable deep learning framework supporting state of the art in deep learning models, including convolutional neural networks (CNNs) and long short-term memory networks (LSTMs).
Make sure your website doesn’t go down with a server or datacenter crash by configuring a master-slave setup for high availability. This means, if one of your servers goes down, we will automatically failover your primary server to a healthy and available region. You can also learn more in our MySQL Firewalls documentation.
Since a few days ago this weblog serves 100% of its content directly out of the Amazon Simple Storage Service (S3) without the need for a web server to be involved. I had held out implementing an alternative to my simple blog server that had. No Server Required - Jekyll & Amazon S3. By Werner Vogels on 17 February 2011 07:45 AM.
Key Takeaways Rollbacks in MongoDB are triggered by disruptions in the replication process due to primary node crashes, network partitions, or other failures, which can lead to substantial data loss and inconsistencies. This failure in replication could happen due to crashes, network partitions, or other situations where failover occurs.
Is the server too slow? The Four LCP Subparts LCP subparts split the Largest Contentful Paint metric into four different components: Time to First Byte (TTFB) : How quickly the server responds to the document request. A network request waterfall can help us understand what resources are loading through each stage.
This blog post introduces the new REST API improvements and some best practices for streamlining API requests and decreasing load on the API by reducing the number of requests required for reporting and reducing the network bandwidth required for implementing common API use cases.
In this blog, we’ll show you how to connect to a MongoDB server configured with self-signed certificates for SSL using both the Ruby MongoDB driver and the popular Object-Document-Mapper (ODM) mongoid. The connection options available for the driver are documented here , and the options we will need are: :ssl. ssl_verify.
OneAgents are optimized to send data to the Dynatrace servers with the smallest possible impact, querying the metrics every minute, and the data is a first-class citizen for the Dynatrace AI root-cause analysis. For examples of writing Custom devices, take a look at our document or take inspiration from our GitHub repository.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content