This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. So, stay tuned for more enhancements and features.
Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Click on Select metric. Change it now to sum.
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
With the most important components becoming release candidates , Dynatrace now supports the full OpenTelemetry specification on all runtimes and automatically adds intelligence to metrics at enterprise scale. So these metrics are immensely valuable to SRE and DevOps teams. Automation and intelligence for metrics at enterprise scale.
You can find additional deployment options in the OpenTelemetry demo documentation. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. metrics from span data. Select + then select Metrics from the drop-down.
Amazon Bedrock , equipped with Dynatrace Davis AI and LLM observability , gives you end-to-end insight into the Generative AI stack, from code-level visibility and performance metrics to GenAI-specific guardrails. Send unified data to Dynatrace for analysis alongside your logs, metrics, and traces.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
To reduce your CloudWatch costs and throttling, you can now select from additional services and metrics to monitor. Get up to 300 new AWS metrics out of the box. Dynatrace ingests AWS CloudWatch metrics for multiple preselected services. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon Aurora.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Dynatrace Documentation maintains a list of events, which will grow as we unlock new use cases.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Many technologies expose their metrics in the Prometheus data format. Easily gain actionable insights with the Dynatrace Extension for Prometheus metrics. Prometheus in Kubernetes ?and
To reduce your CloudWatch costs and throttling, you can now select from additional services and metrics to monitor. Get up to 300 new AWS metrics out of the box. Dynatrace ingests AWS CloudWatch metrics for multiple preselected services. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon Aurora.
The training times and other quality metrics, such as the RMSE (Root Mean Squared Error), SMAPE (Scaled Mean Absolute Percentage Error), and coverage probability, are monitored using Dynatrace. Our data scientists utilize metrics and events to store these quality metrics. For full details, see Dynatrace Documentation.
Optimizing RabbitMQ requires clustering, queue management, and resource tuning to maintain stability and efficiency. It also provides an HTTP API for retrieving performance metrics and a command-line tool for advanced management tasks. RabbitMQ supports high message volumes but may experience performance drops under heavy loads.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
Jaeger and Prometheus backends for displaying the collected traces and metrics, but you can easily configure alternative backends. For details, see the OpenTelemetry demo application deployment documentation as a reference. is the custom metrics ingest endpoint that is used by the collector to export metrics.
To stay tuned, keep an eye on our release notes. Enhanced API documentation for the latest OneAngent endpoint of the Deployment API. (APM-365055). Improved efficiency and response time of filter operators in metric selectors that both apply an entity selector and filter a dimension called `Container` or `Process`. (APM-368260).
To stay tuned, keep an eye on our release notes. Log Monitoring documentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoring documentation to better focus on concepts and information that you, the user, look for and need. Legacy Log Monitoring v1 Documentation. Dashboards.
Any time you run a test with WebPageTest, you’ll get this table of different milestones and metrics. Higher variance means a less stable metric across pages. I can see from the screenshot above that TTFB is my most stable metrics—no one page appears to have particularly expensive database queries or API calls on the back-end.
The challenge for hybrid cloud deployments is maintaining critical observability, which must include the full set of monitoring signals: logs, metrics, and traces. That’s why a hybrid cloud scenario, where workloads are shared between public clouds and highly performant mainframe platforms like IBM Z, is a robust and effective strategy.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. They enable us to further fine-tune and configure the system, ensuring the new changes are integrated smoothly and seamlessly.
Great news: OpenTelemetry endpoint detection, analyzing OpenTelemetry services, and visualizing Istio service mesh metrics just got easier. As a CNCF open source incubating project, OpenTelemetry provides a standardized set of APIs, libraries, agents, instrumentation, and specifications for logging, metrics, and tracing.
The challenges with service management included: Stale documentation OS Updates High cognitive overhead A lack of continuous testing Scaling Image Creation Our existing AMI baking tool Aminator does not support Windows so we had to leverage other tools. Services are more reliable, testable, and documented.
A single pane of glass to view trace information along with AWS CloudWatch metrics. See your AWS serverless workloads in full context with customer experience and business outcome metrics. extension provides insights into traces and metrics from each monitored Lambda function. documentation. the metrics you’ll?find
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. Chunk your documents from unstructured data sources, as usual in GraphRAG.
We asked hundreds of developers, engineers, software architects, dev teams, and IT leaders at DeveloperWeek to discover the current NoSQL vs. SQL usage, most popular databases, important metrics to track, and their most time-consuming database management tasks. Other category, including migrations, queries, comparing, tuning, and replication.
Logs complement metrics and enable automation Cloud practitioners agree that observability, security, and automation go hand in hand. Logs complement out-of-the-box metrics and enable automated actions for responding to availability, security, and other service events.
Observability is divided into three major verticals—metrics, logs, and distributed traces—the so-called three pillars of observability. 1) Metrics. As a full-stack monitoring platform, Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Dynatrace news. 2) Distributed traces.
Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures. Business leaders can decide which logs they want to use and tune storage to their data needs. Dynatrace Grail unifies data from logs, metrics, traces, and events within a real-time model. Seamless integration.
Business value : Once we have a rubric for evaluating our systems, how do we tie our macro-level business value metrics to our micro-level LLM evaluations? Any scenario in which a student is looking for information that the corpus of documents can answer. Wrong document retrieval : Debug chunking strategy, retrieval method.
Such a template should contain a get-started tutorial, sample source-code framework, policy guardrails, CI/CD pipeline, infrastructure-as-code templates, and reference documentation. Allow for flexibility Custom query variables are available to fine-tune guardian objectives and maintain flexibility in fetching data from Grail.
Key highlights of PMM 2.35: Access Control (Tech Preview): Limit access to metrics Disclaimer: Please note that PMM Access Control is currently in technical preview and is subject to change. PMM Dashboards offer valuable insights for monitoring database metrics and troubleshooting. Stay tuned!
Since we index the data as-is from the federated graph, the indexing query itself acts as self-documentation. This integration with the federation gateway allows the search DGS to just return the matching entity keys from the search index instead of the whole matching document(s).
Improve cloud platform management with deeper insights into platform metrics. Automatically monitor all important Go metrics. Upon checking the Go-specific metrics of the foxy process, a suspicious, continuous increase of goroutines can be observed. So stay tuned! Get always-on 24/7 code-level CPU profiling. Do much more.
Here are some key takeaways to keep in mind: Be skeptical of advice or metrics that sound too good to be true. For example, the metrics that come built-in to many tools rarely correlate with what you actually care about. Of course, theres more to making improvements than just relying on tools and metrics.
In this blog post, we will discuss how to extend Percona Monitoring and Management (PMM) to get PostgreSQL metrics on checkpointing activity, internal buffers, and WAL usage. With this data, we’ll be able to better understand and tune our Postgres servers. You can search the blog for more information on this if needed.
Label-based access control is a security mechanism that allows companies to control who can access specific metrics based on their labels. To simplify access management : Label-based access control can simplify access management by allowing companies to assign labels to metrics. Which approach should I use when assigning roles?
In particular, the VMAF metric lies at the core of improving the Netflix member’s streaming video quality. The request provides the source and the derivative whose quality is to be computed and requests that the VQS provides quality scores using VMAF, PSNR and SSIM as quality metrics. Assembly for two of the metrics (e.g.
We do not use it for metrics, histograms, timers, or any such near-real time analytics use case. Flexible : This metadata can be adjusted per time slice, allowing us to tune the partition settings of future time slices based on observed data patterns in the current time slice.
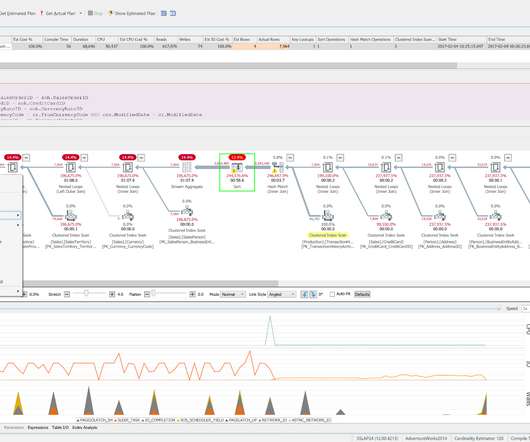
Tom Davidson, Opening Microsoft's Performance-Tuning Toolbox SQL Server Pro Magazine, December 2003. Waits and Queues has been used as a SQL Server performance tuning methodology since Tom Davidson published the above article as well as the well-known SQL Server 2005 Waits and Queues whitepaper in 2006. The Top Queries That Weren't.
Thus, the implemented solution must integrate with Netflix Spring facilities for authentication and metrics support at the very minimum?—?the However, it can be adjusted by tuning the max-poll-interval-ms and max-poll-records configuration values, which need to be somehow determined empirically beforehand for best performance.
Documentation is slow and laborious to produce. Infrastructure is provisioned and modified in code, eliminating much of the need for manual installation and tuning. Teams can capture and analyze metrics, logs, traces, and user-experience data in the context of dependencies among services and infrastructure.
Many changes and new features are brought to the system, and as part of keeping in tune with the changes and how they can impact us, we go through the changes to better understand them. adds two new methods that return metrics that are very useful in evaluating either existing or potential new shard keys.
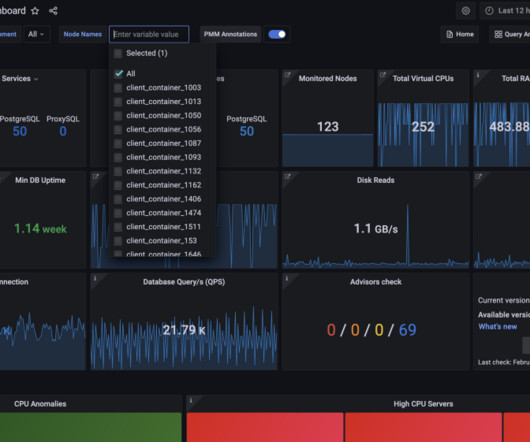
The new Status column on the Inventory page shows the status of your databases based on metrics coming directly from them. Stay tuned! Experimental Kubernetes Pods Status dashboard Kubernetes Pods Status dashboard provides detailed information about the state and performance of your pods, including CPU, Memory, and Network metrics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content