

Automate complex metric-related use cases with the Metrics API version 2
Dynatrace
MAY 20, 2020
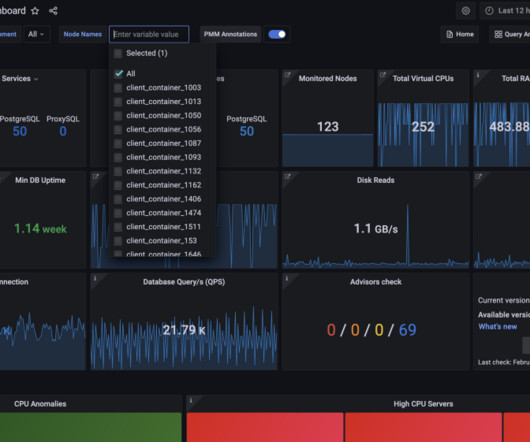
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.









































Let's personalize your content