This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. The file can be downloaded here. This is just the beginning.
Access policies for Dynatrace Grail™ data lakehouse are still available as service-related policies; they allow you to control access to the monitoring data on a per-data-source level, for example, logs and metrics. For more information, go to our IAM policy boundaries documentation.
Service-level objectives are typically used to monitor business-critical services and applications. However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals.
Take your monitoring, data exploration, and storytelling to the next level with outstanding data visualization All your applications and underlying infrastructure produce vast volumes of data that you need to monitor or analyze for insights. Based on the color, you immediately see if any SLOs are off track.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. Recently, we’ve expanded our digital experience monitoring to cover the entire customer journey, from conversion to fulfillment.
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Follow along to create this host monitoring dashboard We will create a basic Host Monitoring dashboard in just a few minutes. Create a new dashboard.
Traditional monitoring approaches often require manual scripting and integration to get alerted about production-threatening issues in pre-production environments. Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics.
To set up the token, see Dynatrace APITokens and authentication in Dynatrace documentation. The post Demo: Monitoring the OpenTelemetry demo app Astronomy Shop with Dynatrace Dashboards appeared first on Dynatrace news. If you dont have one, you can use a trial account. A Dynatrace API token with the following permissions.
Digital experience monitoring (DEM) is crucial for organizations to meet this demand and succeed in today’s competitive digital economy. DEM solutions monitor and analyze the quality of digital experiences for users across digital channels.
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
Current synthetic capabilities Dynatrace Synthetic Monitoring is a powerful tool that provides insight into the health of your applications around the clock and as they’re perceived by your end users worldwide. Compared to other solutions I have tested, Dynatrace NAM monitors are the most configurable which is to my liking.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
Real-time monitoring : The periodic reports from cloud service providers lack real-time monitoring and actionable insights, limiting IT teams’ ability to make immediate adjustments to reduce carbon footprints. We implemented a wasted energy metric in the app to enhance practitioner actionability.
Over the last year, Dynatrace extended its AI-powered log monitoring capabilities by providing support for all log data sources. We added monitoring and analytics for log streams from Kubernetes and multicloud platforms like AWS, GCP, and Azure, as well as the most widely used open-source log data frameworks.
Many of our customers—the world’s largest enterprises—have embraced the Dynatrace SaaS approach to monitoring, which provides critical business insights powered by AI and automation for globally-distributed, heterogeneous IT landscapes. New self-monitoring environment provides out-of-the-box insights and custom alerting.
Real user monitoring can help you catch these issues before they impact the bottom line. What is real user monitoring? Real user monitoring (RUM) is a performance monitoring process that collects detailed data about a user’s interaction with an application. Real user monitoring collects data on a variety of metrics.
Automated AI-powered analytics are necessary to match the scale of monitoring these enterprises require. Our journey began in 2019 with the introduction of the Dynatrace Citrix monitoring extension. Listen, learn, improve, and repeat The latest update to the Citrix monitoring extension is now available.
For quite some time already, Dynatrace has provided full observability into AWS services by ingesting CloudWatch metrics that are published by AWS services. Amazon CloudWatch gathers metric data from various services that run on AWS. We’re happy to announce that Dynatrace is now a launch partner for Amazon CloudWatch Metric Streams.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. Monitoring such an application is easy.
Every software development team grappling with Generative AI (GenAI) and LLM-based applications knows the challenge: how to observe, monitor, and secure production-level workloads at scale. Production performance monitoring: Service uptime, service health, CPU, GPU, memory, token usage, and real-time cost and performance metrics.
Most business processes are not monitored. Business processes can be quite complex, often including conditional branches and loops; many business process monitoring initiatives are abandoned or simplified after attempting to map the process flow. First and foremost, it’s a data problem. A step may have up to five branches.
Teams are using concepts from site reliability engineering to create SLO metrics that measure the impact to their customers and leverage error budgets to balance innovation and reliability. Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
A typical design pattern is the use of a semantic search over a domain-specific knowledge base, like internal documentation, to provide the required context in the prompt. OneAgent automatic injection of monitoring and tracing code works not only for the NodeJS language binding but also when using the raw HTTPS request in NodeJS.
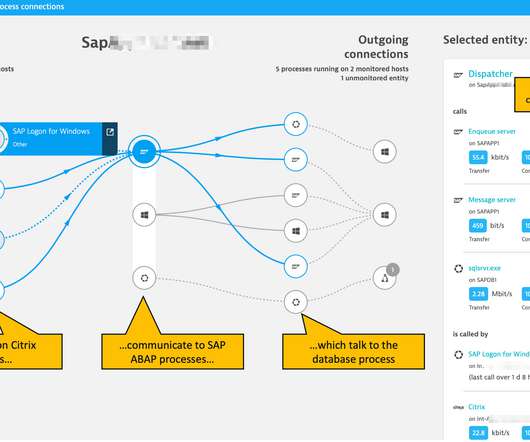
Having released this functionality in a Preview Release back in May 2019, we’re now happy to announce the General Availability of our SAP ABAP monitoring extension. Why SAP ABAP platform monitoring in Dynatrace? What is ABAP platform monitoring? Monitoring is purely remote and implemented using public SAP ABAP interfaces.
Observability and monitoring as a source of truth. To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. To provide actionable answers monitoring systems store, baseline, and analyze telemetry data.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Source: OpenTelemetry Documentation. Monitoring begins here. Logs, metrics, and traces make up the bulk of all telemetry data.
At Dynatrace, we’re constantly improving our AWS monitoring capabilities. Monitor and understand additional AWS services. Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Get up to 300 new AWS metrics out of the box. Updated AWS monitoring policy. Amazon EMR.
We’re proud to announce the Early Access Program (EAP) for monitoring of SAP ABAP performance from the infrastructure and ABAP application platform perspective. Why SAP ABAP platform monitoring in Dynatrace? What is ABAP platform monitoring? Monitoring is purely remote and implemented using public SAP ABAP interfaces.
With over 700 ready-made apps and integrations on the Hub, Dynatrace seamlessly automates full stack monitoring, ensuring comprehensive coverage regardless of the technologies you’re utilizing. Search the Hub to find Extensions for effortlessly importing technology-specific metrics. Looking to integrate data into Dynatrace?
Dynatrace with Red Hat OpenShift monitoring stands out for the following reasons: With infrastructure health monitoring and optimization, you can assess the status of your infrastructure at a glance to understand resource consumption and thus optimize resource allocation for cost efficiency.
At Dynatrace, we’re constantly improving our AWS monitoring capabilities. Monitor and understand additional AWS services. Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Get up to 300 new AWS metrics out of the box. Updated AWS monitoring policy. Amazon EMR.
Complex syslog ecosystems can be challenging Monitoring devices and applications that provide output via the syslog protocol is a must-have for many organizations. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Many technologies expose their metrics in the Prometheus data format. Easily gain actionable insights with the Dynatrace Extension for Prometheus metrics. Prometheus in Kubernetes ?and
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. SREs and DevOps engineers need cloud logs in an integrated observability platform to monitor the whole software development lifecycle. See CloudFormation template documentation for details.
Monitoring your MySQL database performance in real-time helps you immediately identify problems and other factors that could be causing issues now or in the future. This is usually done through monitoring software and tools either built-in to the database management software or installed from third-party providers.
Optimizing cloud services can prove quite challenging because logs, metrics, and traces are not always put together in context, and you don’t have access to the underlying hosts. When you use Dynatrace Log Monitoring, it’s enough to forward your logs and have Dynatrace take care of the rest. For details, see Log viewer documentation.
One-click activation of log collection and Azure Monitormetric collection in the Microsoft Azure Portal allows instant ingest of Azure Monitor logs and metrics into the Dynatrace platform. Dashboards leverages the power of DQL for Azure monitoring in one place.
already address SNMP, WMI, SQL databases, and Prometheus technologies, serving the monitoring needs of hundreds of Dynatrace customers. JMX monitoring extensions are currently being migrated. Dynatrace provides tooling and documentation to help you migrate your Extensions 1.0 and focusing on a much-improved version 2.0
Log Monitoringdocumentation. Starting with Dynatrace version 1.239, we have restructured and enhanced our Log Monitoringdocumentation to better focus on concepts and information that you, the user, look for and need. Log Monitoring. Legacy Log Monitoring v1 Documentation. Synthetic Monitoring.
Why monitor F5 BIG-IP load balancers? That’s why monitoring every BIG-IP instance is crucial to ensure smooth operation. Monitoring also enables you to: Track application usage patterns and user behavior, leading to optimized application delivery and an enhanced customer experience.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content