This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
You can use it to visualize CPU utilization across your hosts, disk space used, server-side response time, web request/service failure rates, or any other area where you need to spot outliers immediately. Go to our documentation to learn more about implementing honeycomb visualizations on your dashboards or notebooks.
Time To First Byte: Beyond Server Response Time Time To First Byte: Beyond Server Response Time Matt Zeunert 2025-02-12T17:00:00+00:00 2025-02-13T01:34:15+00:00 This article is sponsored by DebugBear Loading your website HTML quickly has a big impact on visitor experience. TCP: Establishing a reliable connection to the server.
Redis Server: 5.07, x86/64. MongoDB server: 4.4.2, BangDB server: 2.0.0, We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. Again Yugabyte latency is quite high. The latency table for test D is as below.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Kafka clusters can be deployed in Kubernetes using Helm charts to simplify scaling and management across multiple servers.
Concatenating our files on the server: Are we going to send many smaller files, or are we going to send one monolithic file? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download.
A typical design pattern is the use of a semantic search over a domain-specific knowledge base, like internal documentation, to provide the required context in the prompt. With these latency, reliability, and cost measurements in place, your operations team can now define their own OpenAI dashboards and SLOs.
Resource consumption: Observing computational resource availability and saturation, whether deployed in cloud-native environments like Kubernetes or CPU-enabled servers. Data quality and drift: Monitoring the quality and characteristics of training and runtime data to detect significant changes that might impact model accuracy.
Using a connection pool in each module is hardly efficient: Even with a relatively small number of modules, and a small pool size in each, you end up with a lot of server processes. You either need an extra server (or 3), or your database server(s) must have enough resources to support a connection pooler, in addition to PostgreSQL.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
By batching and parallelizing the requests to retrieve many creatives via a single query to the GraphQL server, we can optimize the index building process. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index. The graph has two requirements. Search Indexer.
The challenges with service management included: Stale documentation OS Updates High cognitive overhead A lack of continuous testing Scaling Image Creation Our existing AMI baking tool Aminator does not support Windows so we had to leverage other tools. Services are more reliable, testable, and documented.
Rethinking Server-Timing As A Critical Monitoring Tool. Rethinking Server-Timing As A Critical Monitoring Tool. In the world of HTTP Headers, there is one header that I believe deserves more air-time and that is the Server-Timing header. Setting Server-Timing. Sean Roberts. 2022-05-16T10:00:00+00:00.
As a request flows between services, each distinct unit of work is documented as a span. A span: Represents a unit of work, such as a network call from one service to another (a client/server relationship) or a purely internal action (e.g., starting and finishing a method). Is this an anomaly or are we dealing with a pattern?
It’s a cross-platform document-oriented database that uses JSON-like documents with schema, and is leveraged broadly across startup apps up to enterprise-level businesses developing modern apps. Sharding is ideal for very large data sets or high throughput deployments that require more capacity that you can get with a single server.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. One can perform this comparison live on the request path or offline based on the latency requirements of the particular use case.
For each route we migrated, we wanted to make sure we were not introducing any regressions: either in the form of missing (or worse, wrong) data, or by increasing the latency of each endpoint. You can find a lot more details about how this works in the Spinnaker canaries documentation. This meant that data that was static (e.g.
million AI server units annually by 2027, consuming 75.4+ For production models, this provides observability of service-level agreement (SLA) performance metrics, such as token consumption, latency, availability, response time, and error count. For example, generating an image requires as much power as fully charging your smartphone.
The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. However, it is limited by the available free memory amount, and all data is lost when the server stops. It features document-level locking, prefix compression, and collection-level configuration options.
Behind the scenes, Amazon DynamoDB automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer. Amazon DynamoDB offers low, predictable latencies at any scale. s read latency, particularly as dataset sizes grow. Consistency. SimpleDBâ??s
Percona Server for MongoDB (PSMDB) supports all types of compression and enterprise-grade features for free. OS: CentOS Linux 7 I’ve used mgenerate command to insert a sample document. This can further reduce the amount of data that needs to be transmitted between server and client over the network. I am using PSMDB 6.0.4
Tim Berners-Lee tweets that 'This is for everyone' at the 2012 Olympic Games opening ceremony using the NeXT computer he used to build the first browser and web server. Regardless of architecture, Gmail needs to send an HTTP request to the server and update some HTML when the server replies. This Is for Everyone #.
OneAgents are optimized to send data to the Dynatrace servers with the smallest possible impact, querying the metrics every minute, and the data is a first-class citizen for the Dynatrace AI root-cause analysis. For examples of writing Custom devices, take a look at our document or take inspiration from our GitHub repository.
There is a section in our Documentation ( Introduction to Serverless PostgreSQL ) and a short overview of the primary components: Page Server The storage server with the primary goal of storing all data pages and WAL records Safe Keeper A component to store WAL records in memory (to reduce latency). 50051 2.
Recovering from a MongoDB rollback involves locating rollback files, using mongorestore to load data into a separate server, cleansing unneeded data, and importing the data back into the primary cluster, coupled with ongoing monitoring and maintenance of replica sets to maintain system health.
Questions Q: I have a MySQL server with 500 GB of RAM; my data set is 100 GB. Keep in mind that setting the buffer pool size too high may result in other processes on your server competing for memory, which can impact performance. Q: I have a MySQL server, and my application is writing at a rate of 100 MB/hour in my redo logs.
In this blog, we’ll show you how to connect to a MongoDB server configured with self-signed certificates for SSL using both the Ruby MongoDB driver and the popular Object-Document-Mapper (ODM) mongoid. The connection options available for the driver are documented here , and the options we will need are: :ssl. ssl_verify.
Compared to the most recent master version of libaom (AV1 reference software), SVT-AV1 is similar in compression efficiency and at the same time achieves significantly lower encoding latency on multi-core platforms when using its inherent parallelization capabilities.
For documentation, the sysbench commands are: Test1 sysbench./src/lua/windmills/oltp_read.lua Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. That allows it to go a bit further. and ProxySQL 6.6k.
All these resource hints use the rel attribute of the <link> element that you’ll be familiar with finding in the <head> of your HTML documents. One step on from DNS prefetching is preconnecting to a server. A brief “conversation” between the browser and server to create the connection. Preconnecting.
By batching and parallelizing the requests to retrieve many creatives via a single query to the GraphQL server, we can optimize the index building process. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index. The graph has two requirements. Search Indexer.
Remember: This is a critical aspect as you do not want to migrate a service and suddenly introduce high latency or costs to a system that you forgot about having a dependency with! The following shows one of the slides I use to answer the question: What happens if I move this group of servers? Where to invest in data compression?
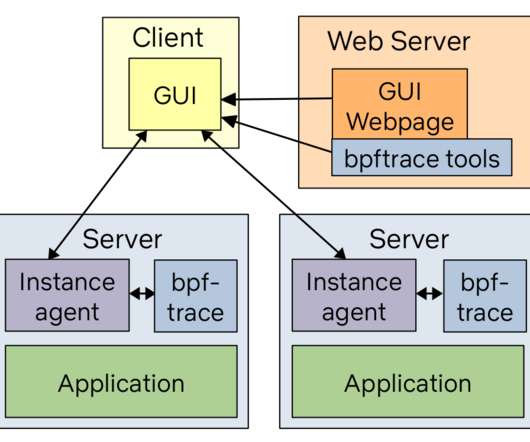
biolatency Disk I/O latency histogram heat map. runqlat CPU scheduler latency heat map. There is already documentation as man pages and example files in the bcc and bpftrace repositories that you can link to, to help your customers understand the tool output. execsnoop New processes (via exec(2)) table.
Yet, for all these technological developments, it’s interesting that many of us are still serving sites in the same way Tim did with the very first website — a web server serving static website files. What’s interesting is there was little mention of static sites in MoveableType’s documentation at all. More after jump!
1 among non-relational/document-based systems ( DB-Engines, July 2023 ). Instead of the table-based structure of relational databases, MongoDB stores data in documents and collections, a design for handling large amounts of unstructured data and for real-time web applications. It ranks No.
The resource loading waterfall is a cascade of files downloaded from the network server to the client to load your website from start to finish. Client Side Rendering, Server Side Rendering And Jamstack. To run it, you have to make another API call to the server and retrieve any data you want to load. Jump to online workshops ?.
By batching and parallelizing the requests to retrieve many creatives via a single query to the GraphQL server, we can optimize the index building process. Once all documents have been indexed with no errors, we swap the alias from the currently active index to the newly built index. The graph has two requirements. Search Indexer.
With clearly documented performance goals, various teams can have meaningful conversations about the optimal delivery of content. CDNs can alleviate last-mile latency, shorten a video’s start time, and potentially reduce buffering issues. Becoming familiar with those components will enable you to set performance goals.
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. We are planning to open source DBLog in 2020 and include additional documentation. References [1] Das, Shirshanka, et al. “ All aboard the Databus!:
Passive instances across regions are also possible, though it is recommended to operate in the same region as the database host in order to keep the change capture latencies low. We are planning to open source DBLog in 2020 and include additional documentation. References [1] Das, Shirshanka, et al. “ All aboard the Databus!:
They understood that most websites lack tight latency budgeting, dedicated performance teams, hawkish management reviews, ship gates to prevent regressions, and end-to-end measurements of critical user journeys. "Server-Side Rendering", a.k.a. "SSR" " [ an intro to "isomorphic javascript", a.k.a. "Server-Side
I would like to share a couple of recent examples that help illustrate how using deprecated SQL Server features continues to bite us. The system table sys.sysprocesses was replaced way back in SQL Server 2005 by a set of dynamic management views (DMVs), most notably sys.dm_exec_requests , sys.dm_exec_sessions , and sys.dm_exec_connections.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Engagement: Poor performance has a well-documented relationship to reduced engagement.
Time To First Byte (TTFB) This is the time it takes for the first piece of information from the server to reach the user’s browser. You need to beware that slow server response times can significantly increase TTFB, often due to server overload, network issues, or un-optimized logic on the server side.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content