This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Go to our documentation to learn more about implementing honeycomb visualizations on your dashboards or notebooks. While histograms look much like time-series bar charts, they’re different in that each bar represents a count (often termed frequency) of metric values.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
To reduce your CloudWatch costs and throttling, you can now select from additional services and metrics to monitor. Get up to 300 new AWS metrics out of the box. Dynatrace ingests AWS CloudWatch metrics for multiple preselected services. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon Aurora.
These signals ( latency, traffic, errors, and saturation ) provide a solid means of proactively monitoring operative systems via SLOs and tracking business success. While this connection might sound simple, finding the right metrics to measure the needed SLIs takes time and effort. This is what Dynatrace captures as response time.
A typical design pattern is the use of a semantic search over a domain-specific knowledge base, like internal documentation, to provide the required context in the prompt. With these latency, reliability, and cost measurements in place, your operations team can now define their own OpenAI dashboards and SLOs.
To reduce your CloudWatch costs and throttling, you can now select from additional services and metrics to monitor. Get up to 300 new AWS metrics out of the box. Dynatrace ingests AWS CloudWatch metrics for multiple preselected services. Amazon ElastiCache (see AWS documentation for Memcached and Redis ). Amazon Aurora.
OpenTelemetry has become a standard for collecting traces, metrics, and logs. Given the prevalence of Python in AI model development, OpenTelemetry serves as a robust standard for collecting observability data, including traces, metrics, and logs. Maintained under the Apache 2.0 However, Python models are trickier.
Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. When we talk about downloading files, we—generally speaking—have two things to consider: latency and bandwidth. It gets worse.
Thats why the Time to First Byte (TTFB) metric is important: it measures how soon after navigation the browser starts receiving the HTML response. Generating the HTML document quickly plays a big part in minimizing TTFB delays. But actually, theres a lot more to optimizing this metric. TTFB stands for Time to First Byte.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
By collecting and analyzing key performance metrics of the service over time, we can assess the impact of the new changes and determine if they meet the availability, latency, and performance requirements. The results are then evaluated using specific metrics to determine whether the hypothesis is valid.
Real user monitoring collects data on a variety of metrics. For example, data collected on load actions can include navigation start, request start, and speed index metrics. Real user monitoring works by injecting code into an application to capture metrics while the application is in use. How real user monitoring works.
To prepare ourselves for a big change in the tech stack of our endpoint, we decided to track metrics around the time taken to respond to queries. After some consultation with our backend teams, we determined the most effective way to group these metrics were by UI screen.
Bringing together metrics, logs, traces, problem analytics, and root-cause information in dashboards and notebooks, Dynatrace offers an end-to-end unified operational view of cloud applications. To leverage these integrations and embark on a journey toward optimized AI performance, explore our documentation for seamless onboarding.
Davis AI contextually aligns all relevant data points—such as logs, traces, and metrics—enabling teams to act quickly and accurately while still providing power users with the flexibility and depth they desire and need. The Clouds app provides a view of all available cloud-native services.
Dynatrace monitors your full stack and offers you thousands of metrics with almost zero configuration. This article we help distinguish between process metrics, external metrics and PurePaths (traces). OneAgent & application metrics. OneAgent & cloud metrics. Dynatrace news.
The challenges with service management included: Stale documentation OS Updates High cognitive overhead A lack of continuous testing Scaling Image Creation Our existing AMI baking tool Aminator does not support Windows so we had to leverage other tools. Services are more reliable, testable, and documented.
It’s a cross-platform document-oriented database that uses JSON-like documents with schema, and is leveraged broadly across startup apps up to enterprise-level businesses developing modern apps. MongoDB is the #3 open source database and the #1 NoSQL database in the world. DigitalOcean Droplets.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
In response to these needs, developers now have the choice of relational, key-value, document, graph, in-memory, and search databases. Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. Build on.
Thus, the implemented solution must integrate with Netflix Spring facilities for authentication and metrics support at the very minimum?—?the By the following morning, alerts were received regarding high memory consumption and GC latencies, to the point where the service was unresponsive to HTTP requests. million elements.
In particular, the VMAF metric lies at the core of improving the Netflix member’s streaming video quality. This enables us to use our scale to increase throughput and reduce latencies. Here, based on the video length, the throughput and latency requirements, available scale etc., Assembly for two of the metrics (e.g.
Here are some key takeaways to keep in mind: Be skeptical of advice or metrics that sound too good to be true. For example, the metrics that come built-in to many tools rarely correlate with what you actually care about. Of course, theres more to making improvements than just relying on tools and metrics.
Business value : Once we have a rubric for evaluating our systems, how do we tie our macro-level business value metrics to our micro-level LLM evaluations? Any scenario in which a student is looking for information that the corpus of documents can answer. Wrong document retrieval : Debug chunking strategy, retrieval method.
The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. In-Memory Storage Engine, as the name suggests, stores data in memory for faster performance and lower latencies. It features document-level locking, prefix compression, and collection-level configuration options.
This architecture affords Amazon ECS high availability, low latency, and high throughput because the data store is never pessimistically locked. As you can see, the latency remains relatively jitter-free despite large fluctuations in the cluster size. latency and stability) with Empire as well as security benefits.
Compared to the most recent master version of libaom (AV1 reference software), SVT-AV1 is similar in compression efficiency and at the same time achieves significantly lower encoding latency on multi-core platforms when using its inherent parallelization capabilities. The plot shows the results of the 2-pass encoding mode in both codecs.
The metrics that we report against implicitly cleave these into different "camps", leaving us thinking about pre- and post-load as distinct universes. The chief effect of the architectural difference is to shift the distribution of latency within the loop. Improving latency for one scenario can degrade it in another.
Amazon DynamoDB offers low, predictable latencies at any scale. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer. s read latency, particularly as dataset sizes grow.
This allows resource requests, including the HTML document itself, to be enriched with data during its lifecycle, and that information can be inspected for measuring the attributes of that resource! The header is constructed via a name with an optional description and/or metric value. The only required field is the name.
With clearly documented performance goals, various teams can have meaningful conversations about the optimal delivery of content. However, having a performance budget as a standalone metric might not be of much help. CDNs can alleviate last-mile latency, shorten a video’s start time, and potentially reduce buffering issues.
Remember: This is a critical aspect as you do not want to migrate a service and suddenly introduce high latency or costs to a system that you forgot about having a dependency with! There is a lot of documentation on the Dynatrace website and there are a handful of examples on the Dynatrace GitHub repo: [link].
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Engagement: Poor performance has a well-documented relationship to reduced engagement.
The talks are up on YouTube , including my own (behind a paywall, but the slides are freely available [1] ): The talk, like this post, is an update on network and CPU realities this series has documented since 2017. The web performance community should eventually come to a more session-depth-weighted understanding of metrics and goals.
Therefore, companies must carefully consider key performance metrics and methodologies to stay relevant and successful in timely and trend-oriented markets. By incorporating journaling into MongoDB, data integrity is maintained while reducing latency for writing, ultimately improving the overall stability and performance of the database.
The mean and percentile measurements hide this structure, but the rest of this post will show how the structure can be measured and analyzed so that you can figure out a useful model of your system, understand what is driving the long tail of latencies and come up with better SLAs and measures of capacity.
Google’s Core Web Vitals is a set of performance metrics that site owners can use to evaluate performance and diagnose performance issues. These metrics provide a different perspective on user experience: Largest Contentful Paint (LCP) Measures the time it takes for the main content on a webpage to load. One of the key Next.js
This helps support executive sponsors who then have meaningful metrics to point to in justifying the investments being made. Very rarely have we seen a team succeed that doesn’t set budgets, gather RUM metrics, and carry representative customer devices. Main-document scrolling (assuming no active touch listeners).
In addition to availability, our respondents focus most heavily on supporting the following data attributes: “accessibility, accuracy, authoritativeness, freshness, latency, structuredness, ontological typing, connectedness, and semantic joinability.” To address this, rigorous rollout processes are required.
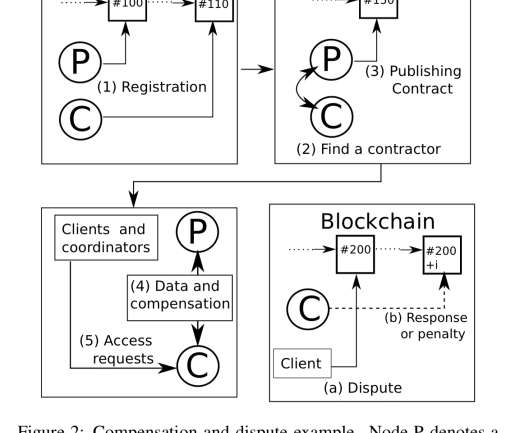
How’s that going to work given what we know about the throughput and latency of blockchains, and the associated mining costs?" 10 minutes) with the bookkeeping metrics for each batch written to the blockchain. A contractor must serve the minimum number of records within each period. Periods (e.g.
Large preview ) While browsers are generally pretty fast, these steps still take time to load, typically in seconds, and even longer on slower, high-latency network connections. So noticeable, in fact, that Core Web Vitals has a metric all about it called Largest Contentful Paint (LCP). This gives us the illusion of a background image.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content