This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
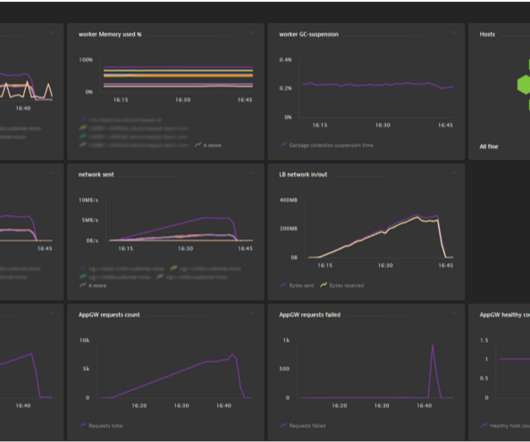
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Even if infrastructuremetrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
Take your monitoring, data exploration, and storytelling to the next level with outstanding data visualization All your applications and underlying infrastructure produce vast volumes of data that you need to monitor or analyze for insights. Infrastructure health: A honeycomb chart is often used to visualize infrastructure health.
This is partly due to the complexity of instrumenting and analyzing emissions across diverse cloud and on-premises infrastructures. Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization.
DataJunction: Unifying Experimentation and Analytics Yian Shang , AnhLe At Netflix, like in many organizations, creating and using metrics is often more complex than it should be. DJ acts as a central store where metric definitions can live and evolve. As an example, imagine an analyst wanting to create a Total Streaming Hours metric.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
By gaining insights into how your Kubernetes workloads utilize computing and memory resources, you can make informed decisions about how to size and plan your infrastructure, leading to reduced costs. Proper Kubernetes monitoring includes utilizing observability information to optimize your environment.
Whether necessary as part of deep root-cause analyses of issues faced by your users that impact your business or if you’re an engineer responsible for the infrastructure hosting your applications and network paths. A set of metrics allowing query results with Data Explorer and creating advanced reporting using Dynatrace Dashboards.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Whatever your use case, when log data reflects changes in your infrastructure or business metrics, you need to extract the metrics and monitor them.
Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. Take a look at two interesting examples of this pattern in the documentation. This has been a guiding design principle with Metaflow since its inception.
OpenTelemetry provides a common set of tools, APIs, and SDKs to help collect observability signals from applications and infrastructure endpoints. You can find additional deployment options in the OpenTelemetry demo documentation. metrics from span data. metrics from span data.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. Dynatrace AWS monitoring gives you an overview of the resources that are used in your AWS infrastructure along with their historical usage.
In this blog post, youll learn how Dynatrace OneAgent automatically identifies Journald and ingests structured logs into Dynatrace while enriching them with topology and infrastructure context. It provides unified observability by automatically correlating logs and placing them in the context of traces and metrics.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Source: OpenTelemetry Documentation. Logs, metrics, and traces make up the bulk of all telemetry data. What is telemetry data?
Teams are using concepts from site reliability engineering to create SLO metrics that measure the impact to their customers and leverage error budgets to balance innovation and reliability. Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data. See installation documentation for setup.
Dynatrace with Red Hat OpenShift monitoring stands out for the following reasons: With infrastructure health monitoring and optimization, you can assess the status of your infrastructure at a glance to understand resource consumption and thus optimize resource allocation for cost efficiency.
Building on its advanced analytics capabilities for Prometheus data , Dynatrace now enables you to create extensions based on Prometheus metrics. Many technologies expose their metrics in the Prometheus data format. Many technologies expose their metrics in the Prometheus data format. Our monitoring coverage already includes ?
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. As logs are first-class citizens alongside traces, metrics, business events, and other data types, you have an observability platform ready to scale with you in your cloud-native journey.
Cloud-native observability for Google’s fully managed GKE Autopilot clusters demands new methods of gathering metrics, traces, and logs for workloads, pods, and containers to enable better accessibility for operations teams. These CSI pods provide a unique way of solving a handful of infrastructure problems. Agent logs security.
Observability Observability is the ability to determine a system’s health by analyzing the data it generates, such as logs, metrics, and traces. There are three main types of telemetry data: Metrics. Metrics are typically aggregated and stored in time series databases for monitoring and alerting purposes.
By analyzing benchmark results, organizations can determine which system aligns best with their infrastructure needswhether its high-speed event processing or reliable message queuing for microservices. The choice between these authentication methods depends on an organizations security infrastructure.
The challenge for hybrid cloud deployments is maintaining critical observability, which must include the full set of monitoring signals: logs, metrics, and traces. For example, on the Dynatrace platform, open the new Infrastructure & Operations app and navigate to any monitored host running on Linux on IBM Z (s390 architecture).
Citrix is critical infrastructure For businesses operating in industries with strict regulations, such as healthcare, banking, or government, Citrix virtual apps and virtual desktops are essential for simplified infrastructure management, secure application delivery, and compliance requirements.
This allows us to provide our services to customers with a focus on these three key pillars: Scalability : Our solution uses scalable cloud infrastructure. Each step is automated from provisioning infrastructure to problem analysis. It automatically sends JMeter metrics to the Dynatrace cluster via the Metrics Ingest API.
By analyzing metric anomalies between hosts and load balancers, Davis AI can quickly resolve problems, thus expediting the process. Integration with SNMP Traps An effective way to receive alerts is through SNMP trap integration, which allows F5 devices to send notifications instead of setting thresholds on Dynatrace metrics.
Findings provide insights into Kubernetes practitioners’ infrastructure preferences and how they use advanced Kubernetes platform technologies. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes moved to the cloud in 2022.
Red Hat and Dynatrace integration overview The strategic partnership and integration between Red Hat and Dynatrace are game changers that solve each mentioned pain point: Easily ingest (and gain precise insights into) your logs, metrics, traces, and business data. In-context topology identification.
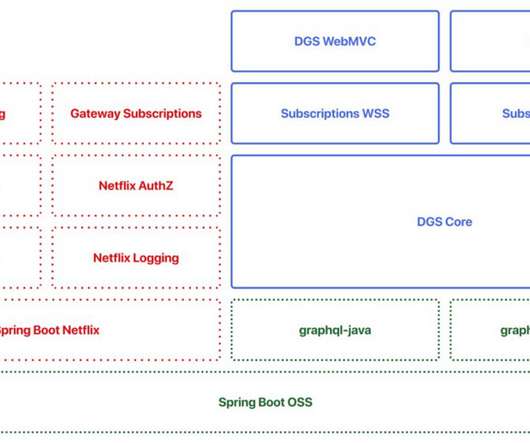
This framework was initially intended to be internal only, focusing on integration with the Netflix ecosystem for tracing, logging, metrics, etc. Comprehensive documentation is available on the website but let’s walk through an example to show you how easy it is to use this framework. Let’s start with a simple schema.
As a leader in cloud infrastructure and platform services , the Google Cloud Platform is fast becoming an integral part of many enterprises’ cloud strategies. Complete observability with Dynatrace provides you with all the metrics from all your Cloud Functions and services across your GCP projects and displays them on dashboard charts.
In addition to APM , th is platform offers our customers infrastructure monitoring spanning logs and metrics, digital business analytics, digital experience monitoring, and AIOps capabilities. as part of a larger research document and should be evaluated in the context of the entire document.
Log management and analytics is an essential part of any organization’s infrastructure, and it’s no secret the industry has suffered from a shortage of innovation for several years. Find time- or entity-bound anomalies or patterns in your infrastructure monitoring logs. Turn log data into value and activate Grail.
This tier extended existing infrastructure by adding new backend components and a new remote call to our ads partner on the playback path. The replay traffic environment generated responses containing a standard playback manifest, a JSON document containing all the necessary information for a Netflix device to start playback.
This gives organizations visibility into their hybrid and multicloud infrastructures , providing teams with contextual insights and precise root-cause analysis. With a single source of truth, infrastructure teams can refocus on innovating, improving user experiences, transforming faster, and driving better business outcomes.
While platform engineers can build and prepare the necessary infrastructure and templates for self-adoption, developers must still provide some customization. Our data scientists utilize metrics and events to store these quality metrics. For full details, see Dynatrace Documentation.
Based on IDC’s research, 83% of enterprises are rationalizing, or optimizing, their technology infrastructure. According to IBM , application modernization takes existing legacy applications and modernizes their platform infrastructure, internal architecture, or features. What is application modernization?
Releasing the Dynatrace OTel Collector reinforces the company’s commitment to open source software and democratizing how organizations collect data from cloud infrastructure and applications. Sample configurations and documentation. Users can also filter telemetry data for all signals (traces, metrics, and logs).
Let me walk you through how I have built my Dynatrace Performance Insights Dashboard showing SLIs split by Test Name as well as SLIs for the specific technology and infrastructure: Enriching your load testing scripts with meta data allows building test context specific SLI-dashboards in Dynatrace. Step #4: Tag your Load Testing steps.
A central element of platform engineering teams is a robust Internal Developer Platform (IDP), which encompasses a set of tools, services, and infrastructure that enables developers to build, test, and deploy software applications. Dynatrace Documentation maintains a list of events, which will grow as we unlock new use cases.
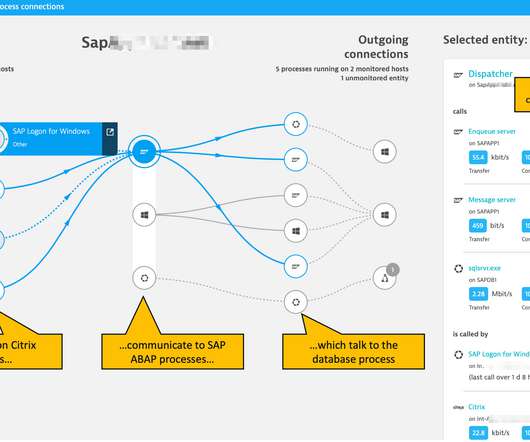
This extends Dynatrace visibility into SAP ABAP performance from the infrastructure and ABAP application platform perspective. The SAP Basis team needs a comprehensive picture of infrastructure performance and dependencies that determine their SAP system’s performance. Why SAP ABAP platform monitoring in Dynatrace? Prerequisites.
Define monitoring goals and user experience metrics Next, define what aspects of a digital experience you want to monitor and improve — such as website performance, application responsiveness, or user engagement — and prioritize what to measure for each application. The time it takes to begin the page’s load event. Load event end.
Symptoms : No data is provided for affected metrics on dashboards, alerts, and custom device pages populated by the affected extension metrics. Infrastructure Monitoring. Settings > Anomaly detection > Infrastructure. Infrastructure Monitoring. Infrastructure Monitoring. Resolved issues.
Jaeger and Prometheus backends for displaying the collected traces and metrics, but you can easily configure alternative backends. Both methods ingest data, but by using the Dynatrace OneAgent, users can automatically discover additional insights about their infrastructure, applications, processes, services and databases.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content