This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
.” While this methodology extends to every layer of the IT stack, infrastructure as code (IAC) is the most prominent example. Here, we’ll tackle the basics, benefits, and best practices of IAC, as well as choosing infrastructure-as-code tools for your organization. What is infrastructure as code? Consistency.
Take your monitoring, data exploration, and storytelling to the next level with outstanding data visualization All your applications and underlying infrastructure produce vast volumes of data that you need to monitor or analyze for insights. Infrastructure health: A honeycomb chart is often used to visualize infrastructure health.
On top of this, organizations are often unable to accurately identify root causes across their dispersed and disjointed infrastructure. Then, document the specifics of your desired end state. Retaining multiple tools generates huge volumes of alerts for analysis and action, slowing down the remediation and risk mitigation processes.
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
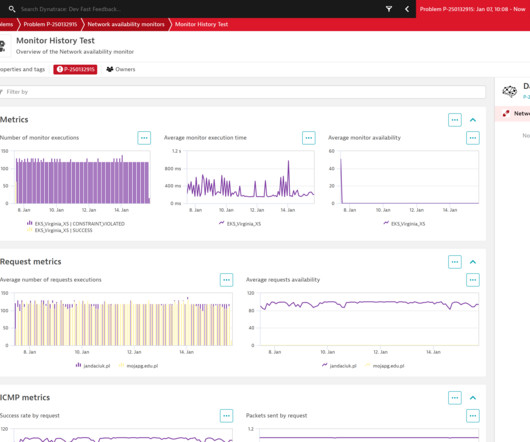
Whether necessary as part of deep root-cause analyses of issues faced by your users that impact your business or if you’re an engineer responsible for the infrastructure hosting your applications and network paths. Check out our Dynatrace NAM documentation to learn more about its functionality and how to use it to address your use cases.
This is partly due to the complexity of instrumenting and analyzing emissions across diverse cloud and on-premises infrastructures. Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization.
AWS Security Hub findings AWS Security Hub provides a great way of aggregating security findings, especially those related to cloud infrastructure. It can also be challenging to construct a full view of one’s security exposures when analyzing security findings across various environments and cloud infrastructures.
Expectations for network monitoring In today’s digital landscape, businesses rely heavily on their IT infrastructure to deliver seamless services to customers. The market demands a robust solution that can monitor applications and the underlying network infrastructure to ensure end-to-end availability and performance.
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. Eventually Consistent : This category needs accurate and durable counts, and is willing to tolerate a slight delay in accuracy and a slightly higher infrastructure cost as a trade-off.
Consider these examples from the updated documentation: You can choose the right level of runtime configurability versus fixed deployments by mixing Parameters and Configs. Take a look at two interesting examples of this pattern in the documentation. This has been a guiding design principle with Metaflow since its inception.
By gaining insights into how your Kubernetes workloads utilize computing and memory resources, you can make informed decisions about how to size and plan your infrastructure, leading to reduced costs. Proper Kubernetes monitoring includes utilizing observability information to optimize your environment.
This can include internal services within an organizations infrastructure or external systems. Visit Dynatrace Documentation for details. A critical security threat for cloud-native architectures SSRF is a web security vulnerability that allows an attacker to make a server-side application send requests to unintended locations.
But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes. Dynatrace AWS monitoring gives you an overview of the resources that are used in your AWS infrastructure along with their historical usage. Dynatrace OneAgent documentation .
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. With Analytics enablement and LORE, weve enabled our business users to truly have a conversation with thedata.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. Without seeing syslog data in the context of your infrastructure, metrics, and transaction traces, you’re slowed down by manual work with siloed data. See installation documentation for setup.
To solve this problem , Dynatrace offers a fully automated approach to infrastructure and application observability including Kubernetes control plane, deployments, pods, nodes, and a wide array of cloud-native technologies. None of this complexity is exposed to application and infrastructure teams.
In this blog post, youll learn how Dynatrace OneAgent automatically identifies Journald and ingests structured logs into Dynatrace while enriching them with topology and infrastructure context. Why migrate from Syslog to Journald Journald provides a more modern alternative that addresses the limitations of existing Syslog implementations.
Navigate digital infrastructure complexity In today’s rapidly evolving digital environment, organizations face increasing pressure from customers and competitors to deliver faster, more secure innovations. Use case: Digital infrastructure change The problem is not always in the application.
Without the ability to see the logs that are relevant to your service, infrastructure, or cloud function—at exactly the right time and in exactly the right format—your cloud or DevOps engineers lose the ability to find the root causes of the issues they troubleshoot. See CloudFormation template documentation for details.
OpenTelemetry provides a common set of tools, APIs, and SDKs to help collect observability signals from applications and infrastructure endpoints. You can find additional deployment options in the OpenTelemetry demo documentation. For details, see Dynatrace API – Tokens and authentication in theDynatrace documentation.
From the very first days of Dynatrace development, preventing the injection of malicious code that could potentially compromise customer infrastructure, has been a priority. The full list of secure development controls, along with many more details, are documented at Dynatrace secure development controls.
From business operations to personal communication, the reliance on software and cloud infrastructure is only increasing. To manage high demand, companies should invest in scalable infrastructure , load-balancing, and load-scaling technologies. Outages can disrupt services, cause financial losses, and damage brand reputations.
In the Magic Quadrant report, Gartner defines APM as, “software that enables the observation of application behavior and its infrastructure dependencies, users, and business key performance indicators (KPIs) throughout the application’s life cycle.” The Gartner document is available upon request from Dynatrace. Gartner Disclaimers.
Findings provide insights into Kubernetes practitioners’ infrastructure preferences and how they use advanced Kubernetes platform technologies. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes moved to the cloud in 2022.
Dynatrace with Red Hat OpenShift monitoring stands out for the following reasons: With infrastructure health monitoring and optimization, you can assess the status of your infrastructure at a glance to understand resource consumption and thus optimize resource allocation for cost efficiency.
By analyzing benchmark results, organizations can determine which system aligns best with their infrastructure needswhether its high-speed event processing or reliable message queuing for microservices. The choice between these authentication methods depends on an organizations security infrastructure.
GKE Autopilot empowers organizations to invest in creating elegant digital experiences for their customers in lieu of expensive infrastructure management. These CSI pods provide a unique way of solving a handful of infrastructure problems. To learn more about how to start using the new GKE Autopilot integration, view our documentation.
Getting insights into the health and disruptions of your networking or infrastructure is fundamental to enterprise observability. Even for a supported component, delivering logs from applications and infrastructure to DevSecBizOps workflows requires significant manual configuration.
In this blog, I would like to share a few best practices for creating High Available (HA) Applications in Mule 4 from an infrastructure perspective ONLY ( CloudHub in this article refers to CloudHub 1.0 Most of the configuration details (only relevant to HA) shared here are taken from MuleSoft Documentation/Articles/Blogs.
For example, you might create a segment that tracks vulnerabilities in your payment processing system separately from general infrastructure assets. Please see the instructions in Dynatrace Documentation. Create custom segments based on attributes like vulnerability type or Davis AI assessment. Not a Dynatrace customer yet?
These methods improve the software development lifecycle (SDLC), but what if infrastructure deployment and management could also benefit? Development teams use GitOps to specify their infrastructure requirements in code. Known as infrastructure as code (IaC), it can build out infrastructure automatically to scale.
It removes the burden of managing underlying infrastructure and is broadly adopted for cloud-native application environments. For details on monitoring such containers, see Deploy OneAgent to container-image packaged functions in Dynatrace Documentation. Dynatrace news. But serverless functions don’t exist in a vacuum.
Releasing the Dynatrace OTel Collector reinforces the company’s commitment to open source software and democratizing how organizations collect data from cloud infrastructure and applications. Sample configurations and documentation. Immediate Security patches.
Organizations running these ESXi versions should prioritize implementing the recommended patches or mitigations to protect their virtualization infrastructure from these significant security threats. If you’re an existing Dynatrace VSPM customer, check out the Dynatrace Runecast documentation. Request a demo of Dynatrace VSPM.
Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Why use a serverless architecture? Serverless architecture offers several benefits for enterprises. Simplicity. The first benefit is simplicity.
It provides simple APIs for creating indices, indexing or searching documents, which makes it easy to integrate. Mapping is used to define how documents and their fields are supposed to be stored and indexed. All the assets of a specific type use the specific index defined for that asset type to create or update the asset document.
In addition to APM , th is platform offers our customers infrastructure monitoring spanning logs and metrics, digital business analytics, digital experience monitoring, and AIOps capabilities. as part of a larger research document and should be evaluated in the context of the entire document.
Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics. Alternatively, you can link to anything that will be useful when looking at SLO details, like a runbook or other documentation. Cutting through noise. Now click “Create SLO.”.
Scaling with Flexible Identity Federation Identity federation plays a critical role in modern IT infrastructure, serving as a foundational component that enables seamless, secure access to various systems and applications across different domains and platforms. See Dynatrace Documentation for full details.
A GraphQL processor executes the user provided GraphQL query to fetch documents from the federated gateway. Writing an Avro schema for such a document is time consuming and error prone to do by hand. This index needs to be kept up-to-date with the data exposed by the various services in the federated graph in near-real time.
This tier extended existing infrastructure by adding new backend components and a new remote call to our ads partner on the playback path. The replay traffic environment generated responses containing a standard playback manifest, a JSON document containing all the necessary information for a Netflix device to start playback.
Gain comprehensive visibility into your Kubernetes clusters As organizations continue to adopt Kubernetes-centric infrastructure, it’s increasingly crucial that their platform engineers have the right tools and capabilities to properly manage and track their Kubernetes clusters end-to-end. Want to try it for yourself? Check it out here.
Motivation Growth in the cloud has exploded, and it is now easier than ever to create infrastructure on the fly. At many companies, managing cloud hygiene and security usually falls under the infrastructure or security teams. A quick start guide is available in our documentation. If you missed the talk, check it out here.
Remediation details are linked to the problem in Dynatrace and documented in ServiceNow. With Dynatrace Ownership information, relevant stakeholders can be easily identified and informed, and high-risk security or infrastructure problems can be escalated. It so initiates the remediation scenario to reset the canary weighting.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content