This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We are introducing native support for document model like JSON into DynamoDB, the ability to add / remove global secondary indexes, adding more flexible scaling options, and increasing the item size limit to 400KB. NoSQL and Flexibility: Document Model. JSON-style document model enables customers to build services that are schema-less.
Optimizing RabbitMQ requires clustering, queue management, and resource tuning to maintain stability and efficiency. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. RabbitMQ ensures fast message delivery when queues are not overloaded.
Compliance with hardware requirements. See private locations documentation for further details and requirements. So stay tuned for more news about: Cluster-wide locations for Dynatrace Managed. What you need to start synthetic monitoring with Windows ActiveGates. Windows 2016 Server (or a supported Linux distribution ).
In this post, we will discuss some important kernel parameters that can affect database server performance and how these should be tuned. The PostgreSQL documentation contains more information about shared memory configuration. The PostgreSQL documentation contains more information about shared memory configuration. Summing up.
Improved performance : MongoDB continually fine-tunes its database engine, resulting in faster query execution and reduced latency. ” MongoDB upgrades follow a well-documented and structured approach, ensuring the process goes smoothly.
Tom Davidson, Opening Microsoft's Performance-Tuning Toolbox SQL Server Pro Magazine, December 2003. Waits and Queues has been used as a SQL Server performance tuning methodology since Tom Davidson published the above article as well as the well-known SQL Server 2005 Waits and Queues whitepaper in 2006. The Top Queries That Weren't.
MySQL 8 introduced a feature that is explained only in a single documentation page. assigning to a specific CPU) is a manageable resource, represented by the concept of “virtual CPU” as a term that includes CPU cores, hyperthreads, hardware threads, and so forth. Then we need to see IF implementing the tuning will work or not.
Resource allocation: Personnel, hardware, time, and money The migration to open source requires careful allocation (and knowledge) of the resources available to you. Evaluating your hardware requirements is another vital aspect of resource allocation. Look closely at your current infrastructure (hardware, storage, networks, etc.)
Complementing the hardware is the software on the RAE and in the cloud, and bridging the software on both ends is a bi-directional control plane. When a new hardware device is connected, the Local Registry detects and collects a set of information about it, such as networking information and ESN.
These smaller distilled models can run on off-the-shelf hardware without expensive GPUs. And they can do useful work, particularly if fine-tuned for a specific application domain. Spending a little money on high-end hardware will bring response times down to the point where building and hosting custom models becomes a realistic option.
Even with cloud-based foundation models like GPT-4, which eliminate the need to develop your own model or provide your own infrastructure, fine-tuning a model for any particular use case is still a major undertaking. That pricing won’t be sustainable, particularly as hardware shortages drive up the cost of building infrastructure.
Doubly so as hardware improved, eating away at the lower end of Hadoop-worthy work. A single document may represent thousands of features. Google goes a step further in offering compute instances with its specialized TPU hardware. Millions of tests, across as many parameters as will fit on the hardware.
This fine-tunes operational access inside RabbitMQ and facilitates complex naming conventions for resources and sophisticated rules regarding access. When persistent messages in RabbitMQ are encrypted, it ensures that even in the event of unsanctioned access to storage hardware, confidential information stays protected and secure.
Linux has been adding tracing technologies over the years: kprobes (kernel dynamic tracing), uprobes (user-level dynamic tracing), tracepoints (static tracing), and perf_events (profiling and hardware counters). There's a lot about Linux containers that isn't well documented yet, especially since it's a moving target.
FSD has a sense of purpose, a planning capability, has real time agency and responds to its environment via an ego model, predicting the behavior of pedestrians and other road users, and is being tuned to drive in a very human way, so that other road users interact with it as a predicable normal driver.
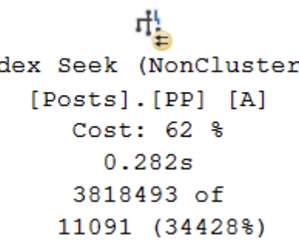
You can refer to the documentation for further details. There is a cool blog post from Vadim covering big data sets in MyRocks: MyRocks Use Case: Big Dataset Query tuning: It is common to find applications that at the beginning perform very well, but as data grows the performance starts to decrease.
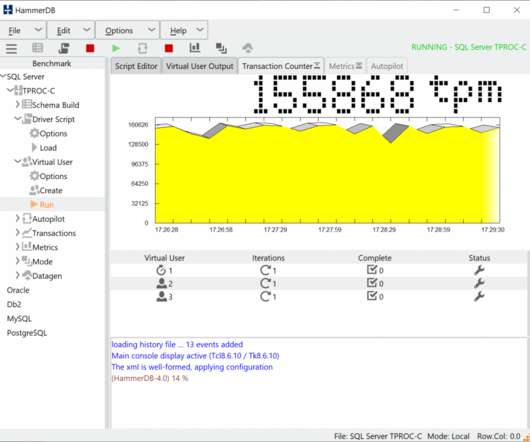
There are several ways to find out this information with the easiest way being by referring to the documentation. Instead, readers should refer to the HammerDB documentation. For the experiments in this blog, we did not tune the system. on identical hardware, with identical settings, but at different load levels.
This allows NASA's engineers to fine-tune every aspect of the rover's behavior, optimizing for reliability rather than rapid development or ease of use. This isn't just brainstorming – it's a formal, documented process that leaves no stone unturned. The choice of C as the programming language is telling.
The main objective of this post is to share my experience over the past years tuning MongoDB and centralize the diverse sources that I crossed in this journey in a unique place. systemctl stop tuned $ systemctl disable tuned Dirty ratio The dirty_ratio is the percentage of total system memory that can hold dirty pages.
We’ll see it in the processing of the thousands of documents businesses handle every day. Andrew Ng , Christopher Ré , and others have pointed out that in the past decade, we’ve made a lot of progress with algorithms and hardware for running AI. Is special-purpose training to fine-tune a model’s behavior an option?
Some retired documentation from Microsoft stated that index fragmentation can have a negative impact from 13-460% depending on the size of the environment and the level of fragmentation. If you have big physical hardware with defaults, then you should look at optimizing MAXDOP. All the figures above are guidelines, not hard truths.
A data pipeline is a software which runs on hardware. The software is error-prone and hardware failures are inevitable. If tuned for performance, there is a good change reliability is compromised - and vice versa. A data pipeline can process data in a different order than they were received.
Used this documentation for the setup: [link]. Detailed documentation: [link]. Verify hardware sizing. Make application tuning much easier. They simulate actual and future growth pattern on pre-production stages, identify and fix hotspots and deploy those tuned application into production. 34.251.255.57.
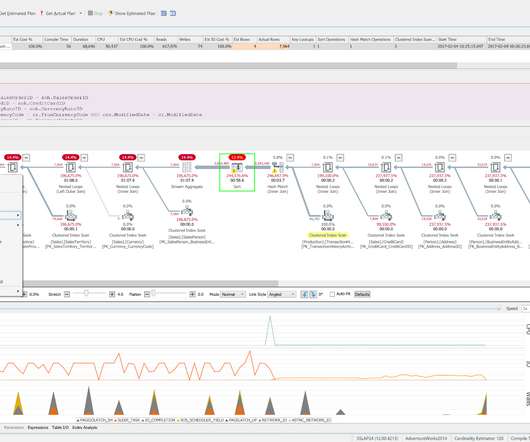
This can make it difficult to draw sound performance-tuning conclusions. This uses hardware, typically a crystal oscillator, that produces ticks at a very high constant rate regardless of processor speed, power settings, or anything of that nature. SQL Server uses the high-precision QueryPerformanceCounter API to capture timing data.
Hardware performance counter results for a simple benchmark code calling Intel’s optimized DGEMM implementation for this processor (from the Intel MKL library) show that about 20% of the dynamic instruction count consists of instructions that are not packed SIMD operations (i.e.,
Hardware performance counter results for a simple benchmark code calling Intel’s optimized DGEMM implementation for this processor (from the Intel MKL library) show that about 20% of the dynamic instruction count consists of instructions that are not packed SIMD operations (i.e., addl $1, %eax vfmadd213pd %zmm16, %zmm17, %zmm29.
Here’s how we explain it in our Documentation: Support for different cluster sizes in passive Database Replication (DR). because they want to use a lower k- factor (even 0) on the replica cluster to lower hardware costs. Stay tuned for more support Q&As – and don’t forget to download our newest version , v7.2.
Copyright The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document.
This is possible because the Tcl interpreter is exceptionally compact and lightweight (Also for this reason Tcl is often used as an embedded language in hardware such as Cisco Routers). But let’s quantify fast by running the same calculation in SQL Server (see the HammerDB documentation for the Oracle example).
In the simplest case, you have a growing workload, and you optimize it to run more efficiently so that you don’t need to buy or rent additional hardware, so your carbon footprint stays the same, but the carbon per transaction or operation is going down. I’ve written before about how to tune out retry storms.
This means that multiple partitions can be processed simultaneously, making better use of available hardware resources and further enhancing query performance. This helps identify potential issues and fine-tune the partitioning strategy. Documentation : Always be documenting!
On multi-core machines – which is the majority of the hardware nowadays – and in the cloud, we have multiple cores available for use. Documentation: [link]. In all versions of MySQL – at least at the time of writing – when you run a single query it will run in one thread, effectively utilizing one CPU core only. With faster disks (i.e.
As such, tuning congestion logic is usually only done by a select few developers, and evolution is slow. Some options for doing this are described in the IETF’s proposed document. Many network interface controllers (NICs) even have built-in hardware-offload features for TCP. Finally convinced?
Copyright The information that is contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. After reading this document you will better understand SQL Server I/O needs and capabilities.
Document store. Egnyte Connect as the content collaboration and data management platform is used by thousands of customers as the single Secure Content Platform for all of their document management needs. We use Mashery as a gateway, the API is documented at [link]. How are software and hardware upgrades rolled out?
Discover how their solution saves customers hours of manual effort by automating the analysis of tens of thousands of documents to better manage investor events, report internally to executive teams, and find new investors to target. Raman Pujani, Solutions Architect, AWS NOTE: This is an interesting new topic.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content