This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. After selecting a mode, users can interact with APIs without needing to worry about the underlying storage mechanisms and counting methods.
We are updating product documentation to include underlying static assumptions. Storage calculations assume that one terabyte consumes 1.2 Cloud storage is replicated twice, which doubles the energy consumption per terabyte. We implemented a wasted energy metric in the app to enhance practitioner actionability.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. What is RabbitMQ?
Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. Performance Optimizations PostgreSQL 17 significantly improves performance, query handling, and database management, making it more efficient for high-demand systems. JSON_VALUE retrieves individual values from JSON documents.
Thanks to its structured and binary format, Journald is quick and efficient. Dynatrace Grail lets you focus on extracting insights rather than managing complex schemas or index and storage concepts. It offers structured logging, fast indexing for search, access controls, and signed messages.
There are several limitations to store and fetch such data (all restrictions could be found in official documentation ). To resolve the problem it was suggested to find more suitable data storage. One day I faced the problem with downloading a relatively large binary data file from PostgreSQL.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storage systems. Speed is next; serverless solutions are quick to spin up or down as needed, and there are no delays due to limited storage or resource access. AWS offers four serverless offerings for storage.
The following figure depicts imaginary “evolution” of the major NoSQL system families, namely, Key-Value stores, BigTable-style databases, Document databases, Full Text Search Engines, and Graph databases: NoSQL Data Models. Document databases advance the BigTable model offering two significant improvements.
JSON is the most common format used by web services to exchange data, store documents, unstructured data, etc. Note: If a particular key is always present in your document, it might make sense to store it as a first class column. JSONB supports indexing the JSON data, and is very efficient at parsing and querying the JSON data.
MongoDB offers several storage engines that cater to various use cases. The default storage engine in earlier versions was MMAPv1, which utilized memory-mapped files and document-level locking. Choosing the appropriate storage engine can have a significant impact on application performance.
You can use the Grail Storage Record Deletion API to trigger a deletion request. To delete the records, use the Storage Record Deletion API. Check our Privacy Rights documentation to stay tuned to our continuous improvements. See documentation for Record deletion in Grail via API. Get started New to Dynatrace?
Several pain points have made it difficult for organizations to manage their data efficiently and create actual value. This approach is cumbersome and challenging to operate efficiently at scale. Teams have introduced workarounds to reduce storage costs. For more detailed information about DQL, reference the Grail documentation.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases. Let’s dive into the various aspects of this abstraction.
Dynatrace OneAgent deployment and life-cycle management are already widely considered to be industry benchmarks for reliability and efficiency. Easier rollout thanks to log storage best practices. Easier rollout thanks to log storage best practices. Dynatrace news. Advanced customization of OneAgent deployments made easy.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. It provides simple APIs for creating indices, indexing or searching documents, which makes it easy to integrate. Mapping is used to define how documents and their fields are supposed to be stored and indexed. Net, Ruby, Perl etc.).
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. GitOps practices can improve infrastructure management efficiency and stability.
This way, disruptions are minimized, MTTR is significantly decreased, and DevSecOps and SREs collaborate efficiently to boost productivity. Remediation details are linked to the problem in Dynatrace and documented in ServiceNow. Executing corrective actions. Keeping relevant stakeholders in the loop.
These capabilities enable deeper insights into all areas of GCP environments, which in turn allows businesses to quickly troubleshoot performance issues, optimize container workloads, and efficiently scale cloud operations. Google Cloud Storage. Google Cloud Datastore. Google Cloud Load Balancing. Google Cloud Pub/Sub.
Buckets are similar to folders, a physical storage location. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Suppose a single Grail environment is central storage for pre-production and production systems.
Whether you need a relational database for complex transactions or a NoSQL database for flexible data storage, weve got you covered. These systems are crucial for handling large volumes of data efficiently, enabling businesses and applications to perform complex queries, maintain data integrity, and ensure security.
Objectives Modern AI innovations require proper infrastructure, especially concerning data throughput and storage capabilities. While GPUs drive faster results, legacy storage solutions often lag behind, causing inefficient resource utilization and extended times in completing the project.
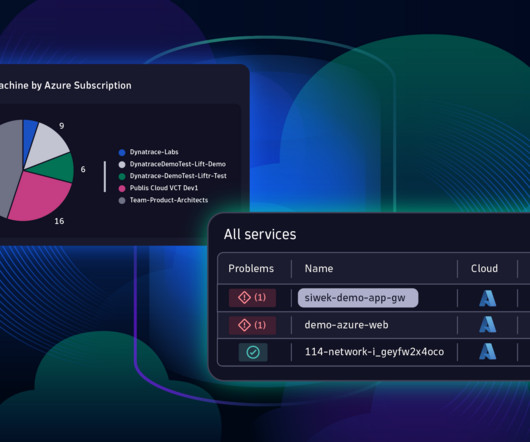
Set up complete monitoring for your Azure subscription with Azure Monitor integration After activating the Azure Native Dynatrace Service (see Dynatrace Documentation for details), the Azure Monitor integration is enabled easily via the Microsoft Azure Portal, as shown in the following screenshot.
To generate client-id, refer to our OAuth documentation. This alert serves as a valuable tool in maintaining operational efficiency, ensuring business continuity, and delivering optimal customer experiences. Client secret to generate token: Client secret for token generation.
Edgar helps Netflix teams troubleshoot distributed systems efficiently with the help of a summarized presentation of request tracing, logs, analysis, and metadata. As a request flows between services, each distinct unit of work is documented as a span. As you can imagine, this comes with very real storage costs. What is Edgar?
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. By default, MongoDB provides a snappy block compression method for storage and network communication.
One approach is to separate compute and storage to allow for independent scaling. By separating storage and compute, Neon replaces the PostgreSQL storage layer with data nodes, and compute nodes are distributed across a cluster of nodes. Architecture A Neon installation consists of compute nodes and the Neon storage engine.
Evaluation of migration completeness: To verify the completeness of the records, cold storage services are used to take periodic data dumps from the two data stores and compared for completeness. In addition, it is important to document the entire migration process and keep records of any issues encountered and their resolution.
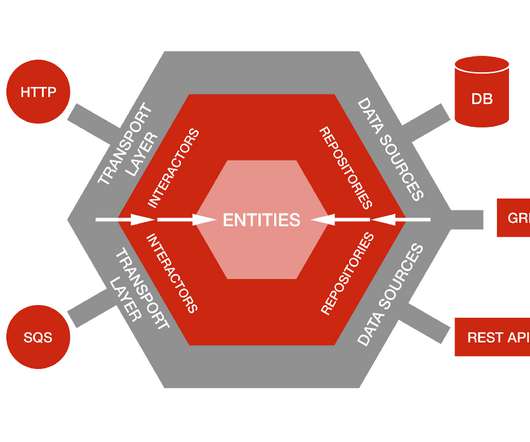
by Damir Svrtan and Sergii Makagon As the production of Netflix Originals grows each year, so does our need to build apps that enable efficiency throughout the entire creative process. Outside of the business logic are the Data Sources and the Transport Layer: Data Sources are adapters to different storage implementations.
How to Implement Pagination in MongoDB® Big datasets require efficient data retrieval and processing for effective management. Pagination is an important factor to consider in MongoDB as it allows for the efficient organization of big datasets. The next() method then progresses through this set for efficient retrieval.
These logs meticulously document every modification executed within the database in the data directory, providing essential incremental updates that facilitate time-specific recovery efforts. STATEMENT level – at which only SQL statements causing changes in data are documented succinctly.
Fortunately, there are ways to skip the local storage entirely and stream MongoDB backups directly to the destination. At the same time, the common goal is to save both the network bandwidth and storage space (cost savings!) However, I find zstd way more efficient, so I’ll use it in the examples.
In response to these needs, developers now have the choice of relational, key-value, document, graph, in-memory, and search databases. This consistent performance is a big part of why the Snapchat Stories feature , which includes Snapchat's largest storage write workload, moved to DynamoDB. Build on.
If you’re new to Conductor, this earlier blogpost and the documentation should help you get started and acclimatized to Conductor. Many of the Netflix Content and Studio Engineering services rely on Conductor for efficient processing of their business flows. The Netflix Media Database (NMDB) is one such example.
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. This separation aims to streamline transaction write logging, improving efficiency and consistency. Who can benefit from DLV? and later v10 versions MySQL: 8.0.28
Figure 1: PMM Home Dashboard From the Amazon Web Services (AWS) documentation , an instance is considered over-provisioned when at least one specification of your instance, such as CPU, memory, or network, can be sized down while still meeting the performance requirements of your workload and no specification is under-provisioned.
Optimize Query Performance and Data Storage Cost. Extract less critical data into a cheaper database storage option. read-only reports to cheaper storage which will save you operational costs as you can potentially scale down your existing RDBMS licenses. Optimize the performance of key queries.
It offers benefits like increased reliability, efficient resource utilization, decoupling of components, and support for multiple programming languages. RabbitMQ allows consumer programs to wait and receive messages from producers, ensuring efficient message delivery and processing.
In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. After the successful launch of the first Dynamo system, we documented our experiences in a paper so others could benefit from them. Amazon DynamoDBâ??s
Storage Encryption for Persistent Messages Protecting sensitive data from unauthorized access is crucial, and encrypting messages at rest safeguards this information should the physical storage be breached. This form of encryption plays a pivotal role in protecting the confidentiality and integrity of data.
If your data is organized following the principle of locality, data access will be more efficient. Regarding tablespace and segment fragmentation, modern storage systems tend to reduce the impact of these types of fragmentation. This type of fragmentation can improve performance and efficiency.
Further, open source databases can be modified in infinite ways, enabling institutions to meet their specific needs for data storage, retrieval, and processing. Non-relational databases: Instead of tables, non-relational (NoSQL) databases use document-based data storage, column-oriented storage, and graph databases.
In addition to that: Run up to four pgBackrest repositories Bootstrap the cluster from the existing backup through Custom Resource Azure Blob Storage support Operations Deploying complex topologies in Kubernetes is not possible without affinity and anti-affinity rules. Please refer to our documentation. In version 1.x,
To aid our transition, we introduced another Cosmos microservice: the Document Conversion Service (DCS). Video quality has matured in Cosmos and we are invested in making VQS more flexible and efficient. DCS is responsible for converting between Cosmos data models and Reloaded data models.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content