This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
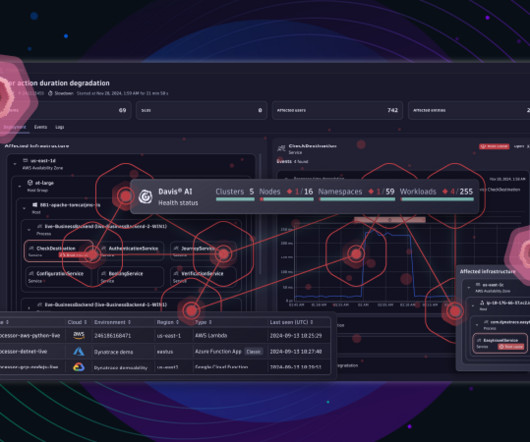
A good Kubernetes SLO strategy helps teams manage and make containerized workloads more efficient. However, due to the fact that they boil down selected indicators to single values and track error budget levels, they also offer a suitable way to monitor optimization processes while aligning on single values to meet overall goals.
Costs and their origin are transparent, and teams are fully accountable for the efficient usage of cloud resources. Our comprehensive suite of tools ensures that you can extract maximum value from your billing data, efficiently turning insights into action. Figure 4: Set up an anomaly detector for peak cost events.
Retaining multiple tools generates huge volumes of alerts for analysis and action, slowing down the remediation and risk mitigation processes. Then, document the specifics of your desired end state. Modernizing your technology stack will improve efficiency and save the organization money over time.
In this blog post, we will see how Dynatrace harnesses the power of observability and analytics to tailor a new experience to easily extend to the left, allowing developers to solve issues faster, build more efficient software, and ultimately improve developer experience!
Consolidate real-user monitoring, synthetic monitoring, session replay, observability, and business process analytics tools into a unified platform. Real-time customer experience remediation identifies and informs the organization about any issues and prevents them in the experience process sooner.
Adding Dynatrace runtime context to security findings allows smarter prioritization, helps reduce the noise from alerts, and focuses your DevSecOps teams on efficiently remedying the critical issues affecting your production environments and applications. This increases the number of findings to prioritize.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. You can even walk through the same example above.
One of the more popular use cases is monitoring business processes, the structured steps that produce a product or service designed to fulfill organizational objectives. By treating processes as assets with measurable key performance indicators (KPIs), business process monitoring helps IT and business teams align toward shared business goals.
This blog post dissects the vulnerability, explains how Struts processes file uploads, details the exploit mechanics, and outlines mitigation strategies. This allows developers to easily access and process the file without handling the upload mechanics directly. Complete mitigation is only guaranteed in Struts version 7.0.0
It allows users to choose between different counting modes, such as Best-Effort or Eventually Consistent , while considering the documented trade-offs of each option. Introducing sufficient jitter to the flush process can further reduce contention. This process can also be used to track the provenance of increments.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. Actions resulting from the evaluation The certification process surfaced a few recommendations for improving the app.
Ingested events are stored in the semantic dictionary , which allows you to efficiently visualize, analyze, and automate the orchestration of security findings in a unified and product-independent way. Events are processed, mapped to the Dynatrace Semantic Dictionary in OpenPipeline , and stored in Grail .
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is RabbitMQ?
The following figure depicts imaginary “evolution” of the major NoSQL system families, namely, Key-Value stores, BigTable-style databases, Document databases, Full Text Search Engines, and Graph databases: NoSQL Data Models. Document databases advance the BigTable model offering two significant improvements.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Incremental Backups: Speeds up recovery and makes data management more efficient for active databases. JSON_VALUE retrieves individual values from JSON documents.
Your companys AI assistant confidently tells a customer its processed their urgent withdrawal requestexcept it hasnt, because it misinterpreted the API documentation. These are systems that engage in conversations and integrate with APIs but dont create stand-alone content like emails, presentations, or documents.
Across the globe, privacy laws grant individuals data subject rights, such as the right to access and delete personal data processed about them. 2] — Nader Henein, VP Analyst, Gartner The Privacy Rights app is designed to streamline this process in Dynatrace. Check out the documentation for the Privacy Rights app.
The adoption process takes time and consideration. The complexity and numerous moving parts of Kubernetes multicloud clusters mean that when monitoring the health of these clusters—which is critical for ensuring reliable and efficient operation of the application—platform engineers often find themselves without an easy and efficient solution.
How To Automate Documentation Workflow For Developers. How To Automate Documentation Workflow For Developers. Why Should You Care About High-Quality Documentation? Many teams struggle with writing documentation. Many teams struggle with writing documentation. Automating Documentation From a High Level.
To filter findings efficiently, use numerical thresholds like DSS (Dynatrace Security Score) or CVSS (Common Vulnerability Scoring System). For example, you might create a segment that tracks vulnerabilities in your payment processing system separately from general infrastructure assets. Not a Dynatrace customer yet?
EdgeConnect facilitates seamless interaction, ensuring data security and operational efficiency. In this hybrid world, IT and business processes often span across a blend of on-premises and SaaS systems, making standardization and automation necessary for efficiency.
The risk of impact from an existing known vulnerability also depends on whether certain processes are using the vulnerable parts of a software component. Vulnerable function monitoring Tracking vulnerable open source software components efficiently is one of the most important pillars of managing attack surfaces. an RCE vulnerability.
Their job is to find out the root cause of any SLO violations, ensure visibility into the application landscape to fix problems efficiently and minimize production costs by reducing errors. Follow the instructions available in Dynatrace documentation to allow proper access and configure Firehose settings.
Dynatrace Grail™ is a data lakehouse optimized for high performance, automated data collection and processing, and queries of petabytes of data in real time. Another consideration is compliance with end-user privacy rights to delete personal data processed about them in line with data protection laws like GDPR and CCPA.
Scale with confidence: Leverage AI for instant insights and preventive operations Using Dynatrace, Operations, SRE, and DevOps teams can scale efficiently while maintaining software quality and ensuring security and reliability. Besides identifying the root cause, Davis AI also automatically connects all relevant log lines.
Using a FaaS model makes it possible to scale up individual application functions as needed rather than increase total resource allocation for your entire application, which helps reduce total resource costs and improve overall app efficiency. Improving data processing. Boosting batch processing. AWS serverless offerings.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
Navigating investigations and threat hunting can involve saving executed queries and found evidence in unstructured text documents that can quickly lose their context. Easily track threat-hunting twists and turns Threat hunting is a nonlinear process. Finding a particular object among millions of similar objects is trickier.
This approach improves operational efficiency and resilience, though its not without flaws. It filters billions of log lines, including the topology of each incident and its affected entities, for efficient problem triaging and troubleshooting, resulting in a 56% faster mean time to repair (MTTR) for critical incidents.
. “As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. Today, the composable nature of code enables skilled IT teams to create and customize automated solutions capable of improving efficiency. Minimize overall documentation. Address monitoring at scale.
Using OpenTelemetry, developers can collect and process telemetry data from applications, services, and systems. The OpenTelemetry Protocol (OTLP) plays a critical role in this framework by standardizing how systems format and transport telemetry data, ensuring that data is interoperable and transmitted efficiently.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. The fluidity of this process is possible through automation tools compatible with Kubernetes.
Deploying software in Kubernetes is often viewed as a straightforward process—just use kubectl or a GitOps solution like ArgoCD to deploy a YAML file, and you’re all set, right? Conclusion Keptn empowers DevOps teams to conquer the Kubernetes deployment challenge confidently, ensuring smoother and more efficient deployments.
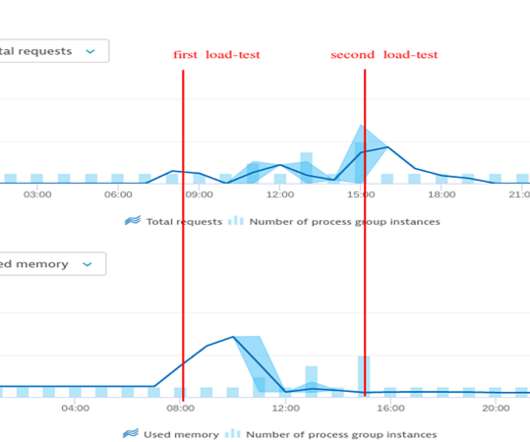
We were in the process of developing a new feature and wanted to make sure it could handle the expected load behavior. We also enabled Dynatrace’s Kubernetes monitoring via the documented ActiveGate approach. It happened in June 2020. Houston, we have a problem! Can we fix it? Yes, we can!
As batch jobs run without user interactions, failure or delays in processing them can result in disruptions to critical operations, missed deadlines, and an accumulation of unprocessed tasks, significantly impacting overall system efficiency and business outcomes. Individual batch job status with processing times and status Figure 4.
Whether it’s the speed and quality of innovation for IT, automation and efficiency for DevOps, or enhancement and consistency of user experiences, Dynatrace makes it easy. We anticipated the industry’s move to dynamic multicloud environments and DevOps processes. The Gartner document is available upon request from Dynatrace.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. While the overall process may be more complicated in practice, this is the gist. This latter approach with node embeddings can be more robust and potentially more efficient.
Dynatrace released Cloud Native Full Stack injection with a short list of temporary limitations — referenced in our documentation — which don’t apply to Classic Full Stack injection. First, go to the Monitor Kubernetes / OpenShift page in the Dynatrace web UI, as documented in help, and generate a deployment file (see the example below).
Moreover, seamless integration is achieved through out-of-the-box solutions that connect, transform, and map your findings data into a unified format using the Dynatrace Semantic Dictionary, ensuring a smooth and efficient security workflow. Cloud architects also seek to minimize manual efforts in managing each finding.
A tight integration between Red Hat Ansible Automation Platform, Dynatrace Davis ® AI, and the Dynatrace observability and security platform enables closed-loop remediation to automate the process from: Detecting a problem. Remediation details are linked to the problem in Dynatrace and documented in ServiceNow.
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. Let’s explore each of these elements and what organizations can do to avoid them.
When visiting or relocating to another country, you must go through the local Visa process, which is often done through an online portal ahead of your trip. More worrisome was a spike in CPU usage, resulting in severe service disruption as backend processing systems crashed due to the spike in load. Dynatrace news.
With more automated approaches to log monitoring and log analysis, however, organizations can gain visibility into their applications and infrastructure efficiently and with greater precision—even as cloud environments grow. Logs are automatically produced and time-stamped documentation of events relevant to cloud architectures.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content