This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s how Dynatrace can help automate up to 80% of technical tasks required to manage compliance and resilience: Understand the complexity of IT systems in real time Proactively prevent, prioritize, and efficiently manage performance and security incidents Automate manual and routine tasks to increase your productivity 1.
In the ever-evolving world of DevOps , the ability to gain deep insights into system behavior, diagnose issues, and improve overall performance is one of the top priorities. Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Clearly, continuing to depend on siloed systems, disjointed monitoring tools, and manual analytics is no longer sustainable.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. They need automated DevOps practices.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOps metrics to help you meet your DevOps goals.
With hands-on experience in AWS DevOps and Google SRE, I’d like to offer my insights on the comparison of these two systems. In this article, I’ll give a brief overview of AWS DevOps and Google SRE , examine when they work best, delve into potential pitfalls to avoid, and provide tips for maximizing the benefits of each.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? A DevOps platform engineer is a more recent term.
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. When they check in their code, the build management system automatically creates a build and tests it.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. This does not include lag time in the alert system.
Organizations are increasingly adopting DevOps to stay competitive, innovate faster, and meet customer needs. By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Thankfully, DevOps orchestration has evolved to address these problems. What is orchestration?
My first encounter with this monitoring system was in 2014 when I joined a project where Zabbix was already in use for monitoring network devices (routers, switches). Over the course of five years, while working on the project, we went through several system upgrades until we finally transitioned to Zabbix 4.0
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. Dynatrace news. This is great!
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. We refer to this culture and practice as observability-driven DevOps and SRE automation. The role of observability within DevOps. The results of observability-driven DevOps speak for themselves.
That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. All of these factors challenge DevOps maturity. Data scale and silos present challenges to DevOps maturity DevOps teams often run into problems trying to drive better data-driven decisions with observability and security data.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Operations teams want to make sure the system doesn’t break. Too many SLOs create complexity for DevOps. Limits of scripting for DevOps and SRE.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
DevOps metrics and digital experience data are critical to this. Breaking down the silos between IT and operations to form a DevOps team, and then extending this to other departments to achieve BizDevOps, has been central to reaching this goal. Dynatrace news. Every journey matters, and we have to deliver on every single transaction.”.
Many organizations that have integrated their software development and operations into DevOps practices struggle with efficiency because they’re juggling disparate DevOps tools, or their tools aren’t meeting their needs. The status quo of the DevOps toolchain. How to approach transforming your DevOps processes.
To keep up, we’ve seen growing interest in DevOps and continuous delivery , as organizations aim to deliver new digital services and experiences faster. However, it isn’t as simple as just implementing a DevOps toolset, analyzing DevOps metrics, or investing in DevOps monitoring capabilities. What is DevOps?
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges.
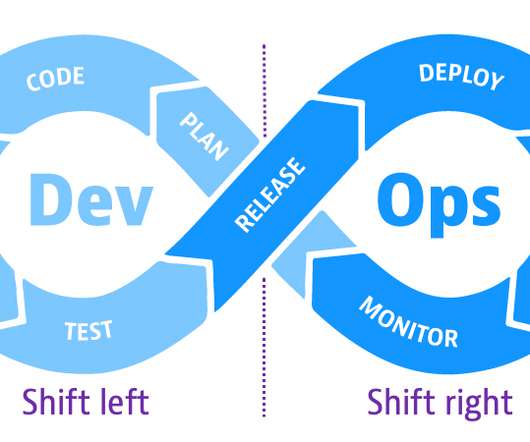
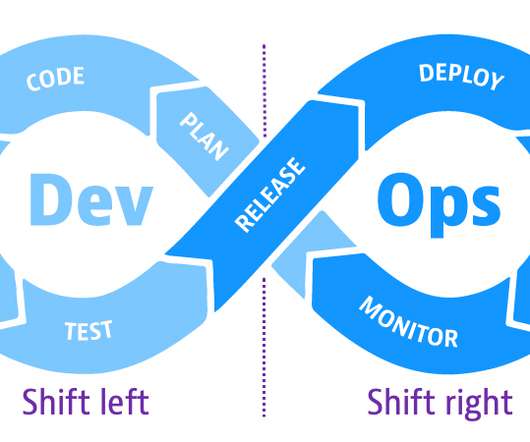
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Log management is an organization’s rules and policies for managing and enabling the creation, transmission, analysis, storage, and other tasks related to IT systems’ and applications’ log data. In short, log management is how DevOps professionals and other concerned parties interact with and manage the entire log lifecycle.
Incident response: Providing capabilities for incident response, including remediation suggestions and integration with DevOps workflows, to help resolve security incidents quickly and efficiently. DevOps teams can use it to embed security practices efficiently into development workflows.
The Federal Reserve Regulation HH in the United States focuses on operational resilience requirements for systemically important financial market utilities. Proactive systems like Dynatrace’s Davis AI can automate responses to threats, swiftly implementing remediation while keeping executives informed of actions taken and their impact.
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. Enhanced observability and release validation Dynatrace already excels at delivering full-stack, end-to-end observability of your systems and user journeys.
In modern software development, DevOps methods have evolved into the pillar of dependable and effective product delivery. But as software systems get more complicated, so does the necessity for strong log monitoring systems that can unite and streamline log management at several CI/CD phases.
As enterprises embrace more distributed, multicloud and applications-led environments, DevOps teams face growing operational, technological, and regulatory complexity, along with rising cyberthreats and increasingly demanding stakeholders.
In the dynamic realm of modern software development and operations, terms such as Platform Engineering, DevOps, and Site Reliability Engineering (SRE) are frequently used, sometimes interchangeably, often causing confusion among professionals entering or navigating these domains.
The DevOps team spends the day containing the damage and now faces tough questions from leadership about how this happened. You might have state-of-the-art surveillance systems and guards at the main entrance, but if a side door is left unlocked, all the security becomes meaningless. Unfortunately, this scenario is all too common.
In DevOps, both monitoring and observability are critical. Because it lets you maintain system reliability, diagnose problems, and enhance performance, effectively and efficiently.
DevSecOps is a cross-team collaboration framework that integrates security into DevOps processes from the start rather than waiting to address security in a separate silo. How is it different from DevOps, and what’s next for the relationship between development, security, and operations within enterprises?
Whether you're a developer, DevOps engineer, or IT manager, this will help you make a smart choice for your monitoring needs. It combines two earlier projects, OpenCensus and OpenTracing, and gives you a unified, vendor-neutral way to monitor systems. But how do you know which one is best for you? What Are OpenTelemetry and Dynatrace?
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. Dynatrace news. What is GitOps? Dynatrace enables observability in GitOps. The post What is GitOps?
Site reliability engineering (SRE) is a discipline in which automated software systems are built to manage the development operations (DevOps) of a product or service. In other words, SRE automates the functions of an operations team via software systems.
Whether it means jumping between multiple windows, sifting through extensive logs to track down bugs, trying to reproduce locally, or requesting additional redeployments from DevOps, debugging poses significant challenges and a resource drain. The problem intensifies when bugs occur mysteriously only in production.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
As organizations become cloud-native and their environments more complex, DevOps teams are adapting to new challenges. Today, the platform engineer role is gaining speed as the newest byproduct of scaling DevOps in the emerging but complex cloud-native world. What is this new discipline, and is it a game-changer or just hype?
DevOps teams can also benefit from full-stack observability. They can get accurate, real-time feedback from integration or production systems, resolving UX issues and application performance challenges more quickly. With improved diagnostic and analytic capabilities, DevOps teams can spend less time troubleshooting.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. How can IT teams deliver system availability under peak loads that will satisfy customers?
On one hand, the complexity of systems demands precise control; on the other, staying competitive requires frequent updates and rapid service enhancements. Observability, therefore, has become crucial in DevOps, offering insights into IT infrastructure stability, performance, and user experience.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content