This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOpsmetrics to help you meet your DevOps goals.
In the ever-evolving world of DevOps , the ability to gain deep insights into system behavior, diagnose issues, and improve overall performance is one of the top priorities. Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems.
DevOpsmetrics and digital experience data are critical to this. Breaking down the silos between IT and operations to form a DevOps team, and then extending this to other departments to achieve BizDevOps, has been central to reaching this goal. Dynatrace news. Security integration. Why stop at your own virtual walls?
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments. In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. However, getting reliable answers from observability data so teams can automate more processes to ensure speed, quality, and reliability can be challenging.
With the most important components becoming release candidates , Dynatrace now supports the full OpenTelemetry specification on all runtimes and automatically adds intelligence to metrics at enterprise scale. So these metrics are immensely valuable to SRE and DevOps teams. Kudos and thanks to all fellow contributors.??.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. We refer to this culture and practice as observability-driven DevOps and SRE automation. The role of observability within DevOps. The results of observability-driven DevOps speak for themselves.
But with many organizations relying on traditional, manual processes to ensure service reliability and code quality, software delivery speed suffers. As a result, organizations are investing in DevOps automation to meet the need for faster, more reliable innovation. Automation is a crucial aspect of achieving DevOps excellence.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.
That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. Data volumes are growing all the time, making it harder to orchestrate, process, and analyze to turn information into insight. All of these factors challenge DevOps maturity. What is DevOps maturity?
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges.
Baking Windows with Packer By Justin Phelps and Manuel Correa Customizing Windows images at Netflix was a manual, error-prone, and time consuming process. We looked at our process for creating a Windows AMI and discovered it was error-prone and full of toil. Last year, we decided to improve the AMI baking process.
Release management challenges with microservices Modern architecture often involves hundreds of microservices, each managed by its own CI/CD pipeline and often by different DevOps teams. SRGs assess key metrics and thresholds, ensuring each deployment meets reliability standards before it progresses further.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. Developers also need to automate the release process to speed up deployment and reliability. Dynatrace news.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. But there is a lack of time for DevOps , SRE , and developers to analyze all this data to identify whether there’s a user impacting problem and if so – what the root cause is to fix it fast. Dynatrace news.
To keep up, we’ve seen growing interest in DevOps and continuous delivery , as organizations aim to deliver new digital services and experiences faster. However, it isn’t as simple as just implementing a DevOps toolset, analyzing DevOpsmetrics, or investing in DevOps monitoring capabilities. What is DevOps?
This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation. Introducing metric extraction from business events Beginning with Dynatrace SaaS version 1.257, you can extract metrics from ingested business events.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). In the workshop, I also answered the question: How can we measure those metrics (=SLIs) that are behind our objectives?
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. This information is gathered from remote, often inaccessible points within your ecosystem and processed by some sort of tool or equipment.
DevOpsmetrics and digital experience data are critical to this. Breaking down the silos between IT and operations to form a DevOps team, and then extending this to other departments to achieve BizDevOps, has been central to reaching this goal. Dynatrace news. Security integration. Why stop at your own virtual walls?
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. When organizations implement SLOs, they can improve software development processes and application performance. The performance SLO needs a custom SLI metric, which you can configure as follows.
In an attempt to hold their place within the market, developers are having to speed their process up whilst delivering products of ever-increasing quality. In 2019, according to Evans Data Corporation, there were 23.9 million developers worldwide. This happening all across the board, even and especially at the 50 leading SaaS companies.
A tight integration between Red Hat Ansible Automation Platform, Dynatrace Davis ® AI, and the Dynatrace observability and security platform enables closed-loop remediation to automate the process from: Detecting a problem. With DQL, the workflow trigger to initiate a required automation and remediation process can be defined.
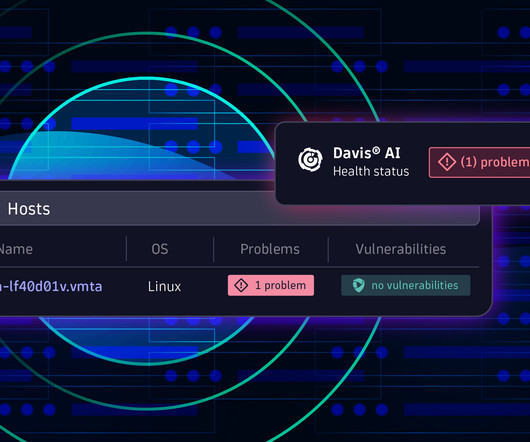
The newly introduced Network devices and Details view within Hosts provide comprehensive health status information, relevant networking signals, and machine metrics—all analyzed and provided by the industry-leading combination of Dynatrace Grail™ data lakehouse and Davis ® AI. Overview of a cloud-hosted frontend web application.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” Ensure that you get the most out of your product.
Dynatrace automatically collects data not just from metrics, traces, and logs, but also user experience and code-level insights – all in context and mapped into a topology. All of this enables DevOps teams to spend more time on innovative, value-adding activities, as Davis continuously monitors for errors or system degradations.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. Amazon Data Firehose helps stream logs to the right destination But your SREs and DevOps engineers know CloudWatch is not the terminal destination for data but rather an intermediate station.
To accomplish this, organizations have widely adopted DevOps , which encompasses significant changes to team culture, operations, and the tools used throughout the continuous development lifecycle. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance. DevOps teams can also benefit from full-stack observability. With improved diagnostic and analytic capabilities, DevOps teams can spend less time troubleshooting.
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. In traditional or hybrid IT environments, messaging systems are used to decouple heavyweight processing, buffer work, or smooth over spiky workloads. Dynatrace news.
Grail, the Dynatrace causational data lakehouse with a massively parallel processing analytics engine, unites observability, security, and business data from multicloud and cloud-native environments while retaining the data’s context to deliver precise answers in real time. DevOpsmetrics and digital experience data are critical to this.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production.
Other aspects of the discipline — such as infrastructure as code, automation, and standardization — reduce extraneous manual processes to increase developer productivity. Reduced operational complexity The self-service portals inherent to platform engineering greatly simplify operational processes.
Powered by Grail and the Dynatrace AutomationEngine , Site Reliability Guardian helps DevOps platform teams make better-informed release decisions by utilizing all the contextual observability and application security insights of the Dynatrace platform.
As a result, site reliability has emerged as a critical success metric for many organizations. That’s why good communication between SREs and DevOps teams is important. The growing amount of data processed at the network edge, where failures are more difficult to prevent, magnifies complexity. availability.
Deploying software in Kubernetes is often viewed as a straightforward process—just use kubectl or a GitOps solution like ArgoCD to deploy a YAML file, and you’re all set, right? Changes in application code or configurations can impact performance metrics, affecting user experience and application functionality.
Automating quality gates is ideal, as it minimizes manually checking and validating key metrics throughout the SDLC. By actively monitoring metrics such as error rate, success rate, and CPU load, quality gates instill confidence in teams during software releases. Several tools can be used to collect metrics in load/performance testing.
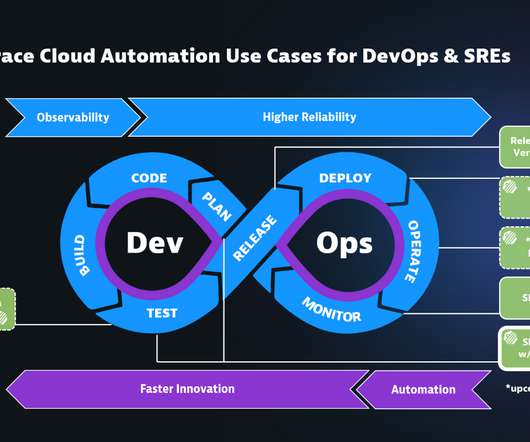
The Dynatrace Software Intelligence Platform already comes with release analysis, version awareness , and Service Level Objective (SLO) support as part of the Dynatrace Cloud Automation solution , helping DevOps and SRE teams automate the delivery and operational decisions. GitOps: Cloud automation as code. Expand to more use cases.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content