This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOpsmetrics to help you meet your DevOps goals.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Find and prevent application performance risks A major challenge for DevOps and security teams is responding to outages or poor application performance fast enough to maintain normal service.
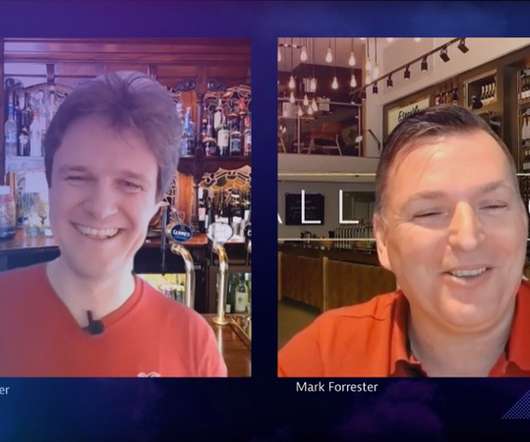
DevOpsmetrics and digital experience data are critical to this. Dynatrace got to explore this challenge as part of our 2021 Perform series when we spoke with Mark Forrester, Digital Readiness Manager for Mitchells & Butlers (M&B) – one of the UK’s largest restaurants and bar groups. Dynatrace news. Security integration.
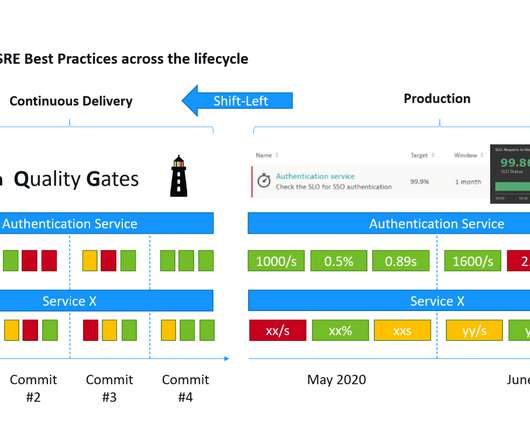
This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates. Dynatrace news.
DORA ( DevOps Research and Assessment ) metrics, developed by the DORA team have become a standard for measuring the efficiency and effectiveness of DevOps implementations. As organizations start to adopt DevOps practices to accelerate software delivery, tracking performance and reliability becomes critical.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. But as with many other automation tools, it can be difficult to maintain the performance and visibility of these workflows.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
In the ever-evolving world of DevOps , the ability to gain deep insights into system behavior, diagnose issues, and improve overall performance is one of the top priorities. Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems.
As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments. In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
That’s especially true of the DevOps teams who must drive digital-fueled sustainable growth. All of these factors challenge DevOps maturity. Data scale and silos present challenges to DevOps maturity DevOps teams often run into problems trying to drive better data-driven decisions with observability and security data.
As a result, organizations are investing in DevOps automation to meet the need for faster, more reliable innovation. Automation is a crucial aspect of achieving DevOps excellence. But according to the 2023 DevOps Automation Pulse , only 56% of end-to-end DevOps processes are automated.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
To keep up, we’ve seen growing interest in DevOps and continuous delivery , as organizations aim to deliver new digital services and experiences faster. However, it isn’t as simple as just implementing a DevOps toolset, analyzing DevOpsmetrics, or investing in DevOps monitoring capabilities. What is DevOps?
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. But, manual steps — such as reviewing test results and addressing production issues resulting from performance, resiliency, security, or functional issues — often hinder these efforts. The role of observability within DevOps.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). In the workshop, I also answered the question: How can we measure those metrics (=SLIs) that are behind our objectives?
This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation. Introducing metric extraction from business events Beginning with Dynatrace SaaS version 1.257, you can extract metrics from ingested business events.
Provide an at-a-glance view of your system’s health and performance Dynatrace guides you in quickly getting the most valuable SLOs set up in just a few clicks. Heterogeneous services require heterogeneous indicators Metrics, logs, and traces are the core ingredients for making your environment observable.
As the new standard of monitoring, observability enables I&O, DevOps, and SRE teams alike to gain critical insights into the performance of today’s complex cloud-native environments. An AI-powered solution can rapidly establish and adjust performance baselines and automatically detect anomalies across distributed systems.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges.
These are just some of the topics being showcased at Perform 2023 in Las Vegas. Perform 2023 news At Perform 2023 in Las Vegas, the headliner theme is IT automation. What’s more, organizations are no longer concerned only about application performance and sales numbers. We’ll post news here as it happens!
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. But there is a lack of time for DevOps , SRE , and developers to analyze all this data to identify whether there’s a user impacting problem and if so – what the root cause is to fix it fast. Dynatrace news.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Whatever your use case, when log data reflects changes in your infrastructure or business metrics, you need to extract the metrics and monitor them.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. These phases must be aligned with security best practices, as discussed in A Beginner`s Guide to DevOps.
For software engineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Performance-as-a-self-service . Try it today using Keptn .
OpenTelemetry (also referred to as OTel) is an open-source observability framework made up of a collection of tools, APIs, and SDKs, that enables IT teams to instrument, generate, collect, and export telemetry data for analysis and understand software performance and behavior. Logs, metrics, and traces make up the bulk of all telemetry data.
A highly efficient Kubernetes setup generates innumerable new metrics every day, making monitoring cluster health quite challenging. You might find yourself sifting through several different metrics without being entirely sure which ones are the most insightful and warrant utmost attention.
This article explores SLOs for service performance. According to the Google Site Reliability Engineering (SRE) handbook, monitoring the four golden signals is crucial in delivering high-performing software solutions. While this connection might sound simple, finding the right metrics to measure the needed SLIs takes time and effort.
Observability across the full technology stack gives teams comprehensive, real-time insight into the behavior, performance, and health of applications and their underlying infrastructure. DevOps teams can also benefit from full-stack observability. How full-stack observability enhances IT and DevOps. See observability in action!
DevOpsmetrics and digital experience data are critical to this. Dynatrace got to explore this challenge as part of our 2021 Perform series when we spoke with Mark Forrester, Digital Readiness Manager for Mitchells & Butlers (M&B) – one of the UK’s largest restaurants and bar groups. Dynatrace news. Security integration.
Whenever a performance problem is flagged, Infrastructure and Operations (I&O) practitioners strive to resolve the issue as soon as possible by identifying the root cause, understanding the impact, obtaining the relevant details, and fixing the issue within the shortest possible timeframe—the meantime to resolution (MTTR). Dynatrace news.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Step-by-step guide: SRE-driven performance analysis with Dynatrace. Dynatrace news. Keptn uses SLO definitions to automatically configure Dynatrace or Prometheus alerting rules. This is what this blog is all about.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. When organizations implement SLOs, they can improve software development processes and application performance. The performance SLO needs a custom SLI metric, which you can configure as follows.
In my recent Performance Clinic with Stefano Doni , CTO & Co-Founder of Akamas , I made the statement, “Application development and release cycles today are measured in days, instead of months. Increase in environment complexity and increased frequency in delivery requires a novel approach to performance optimization.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” Manage platform health and performance.
Well, that’s exactly what the Dynatrace University team did to support Dynatrace’s hands-on training (HoT) days at Dynatrace’s annual user conference Perform in Las Vegas. For the sessions, each student needed to have their own Dynatrace SaaS tenant to monitor and perform the hands-on exercises. Perform 2020 Infrastructure Setup.
IT teams have been observing applications for their health and performance since the beginning. And most importantly, what is in it for developers, DevOps, and SRE folks? If observability is not something new and there are a plethora of monitoring and observability tools available in the market, why bother about OpenTelemetry?
I recently joined two industry veterans and Dynatrace partners, Syed Husain of Orasi and Paul Bruce of Neotys as panelists to discuss how performance engineering and test strategies have evolved as it pertains to customer experience. What do you see as the biggest challenge for performance and reliability? Dynatrace news.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content