This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Find and prevent application performance risks A major challenge for DevOps and security teams is responding to outages or poor application performance fast enough to maintain normal service.
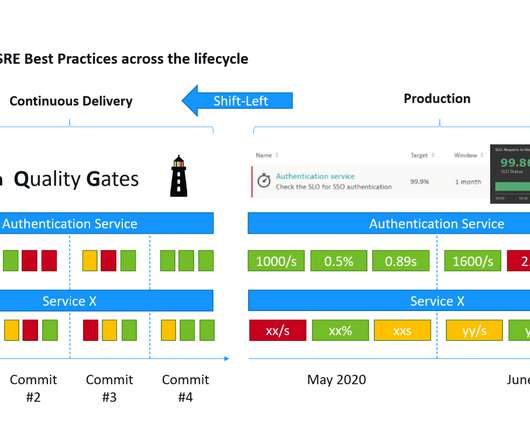
This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates. Dynatrace news.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. This drive for speed has a cost: 22% of leaders admit they’re under so much pressure to innovate faster that they must sacrifice code quality.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments. In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces.
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
Digital transformation has significantly increased the organizational demand to innovate faster. As a result, organizations are investing in DevOps automation to meet the need for faster, more reliable innovation. Automation is a crucial aspect of achieving DevOps excellence.
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
Customer lifetime value (CLV) has long been established as the key metric financial services firms use to gauge their profitability and competitive position in the market. The growing demand for rapid innovation is worsened by the ongoing skills shortages. This puts sensitive customer and transactional information at risk.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. The goal is to accelerate innovation by eliminating the need for custom automation scripts and point-to-point tool integrations. Dynatrace news.
To keep up, we’ve seen growing interest in DevOps and continuous delivery , as organizations aim to deliver new digital services and experiences faster. However, it isn’t as simple as just implementing a DevOps toolset, analyzing DevOpsmetrics, or investing in DevOps monitoring capabilities. What is DevOps?
Several team members had to pore through logs, metrics, and other data to identify issues. “We Ultimately, better infrastructure management enables organizations like Park ‘N Fly to innovate through software. To do so, organizations often succumb to a “hamster wheel” of having to release code more quickly to innovate effectively.
In its report “ Innovation Insight for Observability ,” global research and advisory firm Gartner describes the advantages of observability for cloud monitoring as organizations navigate this shift. The post Gartner: Observability drives the future of cloud monitoring for DevOps and SREs appeared first on Dynatrace blog.
Full-stack observability is fast becoming a must-have capability for organizations under pressure to deliver innovation in increasingly cloud-native environments. A full-stack observability solution uses telemetry data such as logs, metrics, and traces to give IT teams insight into application, infrastructure, and UX performance.
The short answer: The three pillars of observability—logs, metrics, and traces—converging on a data lakehouse. You’re getting all the architectural benefits of Grail—the petabytes, the cardinality—with this implementation,” including the three pillars of observability: logs, metrics, and traces in context.
Today, the AI Breakthrough Awards announced its 2020 winners , recognizing the leading AI innovators and solutions. Dynatrace automatically collects data not just from metrics, traces, and logs, but also user experience and code-level insights – all in context and mapped into a topology. The difference Davis makes.
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Logs, metrics, and traces make up the bulk of all telemetry data. The data life cycle has multiple steps from start to finish.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. This metric indicates how quickly software can be released to production. Dynatrace news.
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. DevOpsmetrics and digital experience data are critical to this. Learn more.
Eventually, a previously siloed company can be reorganized as follows: In such a setup, shared high-level metrics drive individual team members to focus on improving customer outcomes, creating more value, and improving the bottom line. In this way, an organization can break through silos and create stronger business outcomes overall.
The IDC FutureScape: Worldwide IT Industry 2020 Predictions highlights key trends for IT industry-wide technology adoption for the next five years and includes these predictions: Hasten to innovation. By 2024, over 50% of all IT spending will be directly put towards digital transformation and innovation (up from 31% in 2018).
Not just logs, metrics and traces. Its approach to serverless computing has transformed DevOps. Enable autonomous operations, boost innovation, and offer new modes of customer engagement by automating everything. DevOps/DevSecOps with AWS. But most of that budget goes toward running the business—not software innovation.
But the cloud is forcing a rethink of tooling, platforms, technologies, and services to power new, agile, applications and application components, that break down silos, and use AI and automation to accelerate innovation. And for observability to be successful, it requires much more than just logs, metrics, and traces.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” Ensure that you get the most out of your product.
IT, DevOps, and SRE teams seeking to know the health of their apps and services have always faced obstacles that can drain productivity, stifle collaboration, ratchet up the time to resolution, and limit the effectiveness of their collaboration with other parts of the business. Innovate faster with an all-in-one observability solution.
Also , in a field of fifteen vendors analy z ed by Gartner, Dynatrace received the highest scores in five of six critical capabilities use cases: CloudOps, DevOps Release, IT Operations, Application Support, and Application Development. . Our employees listen carefully to our customers and innovate continuously.
We believe at Soldo that efficiency is the key value to be very successful in the business we run,” said Luca Domenella, head of cloud operations and DevOps at Soldo. In a recent conversation at Dynatrace Innovate in Barcelona, Spain, with Liisa Tallinn, product manager of application security at Dynatrace, Domenella explained how it works.
Thus, modern AIOps solutions encompass observability, AI, and analytics to help teams automate use cases related to cloud operations (CloudOps), software development and operations (DevOps), and securing applications (SecOps). DevOps: Applying AIOps to development environments. The deviating metric is response time.
Here, we’ll discuss the AIOps landscape as it stands today and present an alternative approach that truly integrates artificial intelligence into the DevOps process. A full-featured deterministic AIOps solution should lead to faster, higher-quality innovation, increased IT staff efficiency, and vastly improved business outcomes.
Teams are using concepts from site reliability engineering to create SLO metrics that measure the impact to their customers and leverage error budgets to balance innovation and reliability. Nobl9 integrates with Dynatrace to gather SLI metrics for your infrastructure and applications using real-time monitoring or synthetics.
That means DevOps and IT put less time and resources toward driving new proactive innovations, and more into reactive problem solving and putting out fires in an environment that is more dynamic and unpredictable than ever. I’ve long thought of DevOps as being 80% about culture. What Kubernetes Brings to the Table.
This includes collecting metrics, logs, and traces from all applications and infrastructure components. For example, in a recent study , 55% of security teams say they don’t trust developers, and 49% of developers perceive security teams as a blocker to innovation.
Containers are the key technical enablers for tremendously accelerated deployment and innovation cycles. The time and effort saved with testing and deployment are a game-changer for DevOps. Docker, their respective core domains, and some of the challenges involved in both technologies, like observability. But first, some background.
It is also a key metric for organizations looking to improve their DevOps performance. This metric represents the proportion of system incidents resolved by escalating to a higher level of support. This time could be better spent innovating; closed – loop remediation frees up developers’ time, resources, and energy.
But with this speed, agility, and innovation come new challenges. Learn how to easily incorporate software intelligence capabilities into applications’ lifecycle and apply service-level objectives (SLOs) for critical metrics, including performance, quality, and security while adhering to operations standards.
A single pane of glass to view trace information along with AWS CloudWatch metrics. Serverless can accelerate innovation (and introduce blind spots). Serverless architectures help developers innovate more efficiently and effectively by removing the burden of managing underlying infrastructure. the metrics you’ll?find
But when these teams work in largely manual ways, they don’t have time for innovation and strategic projects that might deliver greater value. Predictive AI empowers site reliability engineers (SREs) and DevOps engineers to detect anomalies and irregular patterns in their systems long before they escalate into critical incidents.
Dynatrace enables various teams, such as developers, threat hunters, business analysts, and DevOps, to effortlessly consume advanced log insights within a single platform. DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks.
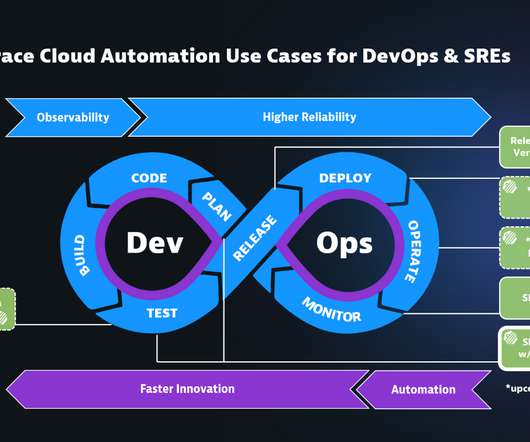
The Dynatrace Software Intelligence Platform already comes with release analysis, version awareness , and Service Level Objective (SLO) support as part of the Dynatrace Cloud Automation solution , helping DevOps and SRE teams automate the delivery and operational decisions. GitOps: Cloud automation as code. Expand to more use cases.
In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior software engineer Yarden Laifenfeld explored developer observability. DevOps, SREs, developers… everyone will ask questions. When an incident occurs, developers need to know what data to look at, where the incident occurred, and other relevant metrics.
Suddenly, not just DevOps, but infrastructure teams, developers, and operations teams are all challenged to understand how performance problems within applications or cloud services may impact the performance of the overall infrastructure. Understand and prevent issues with complete observability into your GCP services.
It also enables DevOps teams to connect to any number of AWS services or run their own functions. Real-time stream processing to perform live activity tracking, data cleansing, metrics generation, and more. But beyond these IT and APM benefits, Dynatrace assists its customers with workflow management via DevOps optimizations.
For most organizations, online service reliability that balances innovation and uptime is a primary goal. SLOs are specifically processed metrics that help businesses balance breakthroughs with reliability. SLOs are pivotal for development, DevOps, and SRE teams because they provide a common language for discussing system reliability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content