This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. Mean time to respond (MTTR) is the average time it takes DevOps teams to respond after receiving an alert.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). Creating an SLO dashboard for Business, DevOps, and SREs. Dynatrace news. Watch webinar now!
Hardware - servers/storage hardware/software faults such as disk failure, disk full, other hardware failures, servers running out of allocated resources, server software behaving abnormally, intra DC network connectivity issues, etc. Redundancy in power, network, cooling systems, and possibly everything else relevant.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. Although modern cloud systems simplify tasks, such as deploying apps and provisioning new hardware and servers, hybrid cloud and multicloud environments are often complex.
AI and DevOps, of course The C suite is also betting on certain technology trends to drive the next chapter of digital transformation: artificial intelligence and DevOps. DevOps methodology—which brings development and ITOps teams together—also forwards digital transformation. And according to Statista , $2.4
Vulnerabilities or hardware failures can disrupt deployments and compromise application security. For instance, if a Kubernetes cluster experiences a hardware failure during deployment, it can lead to service disruptions and affect the user experience.
It also enables DevOps teams to connect to any number of AWS services or run their own functions. As a bonus, operations staff never needs to update operating systems or hardware, because AWS manages servers with no stoppage of application functionality. How does AWS Lambda work? Optimizing Lambda for performance.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. The time and effort saved with testing and deployment are a game-changer for DevOps.
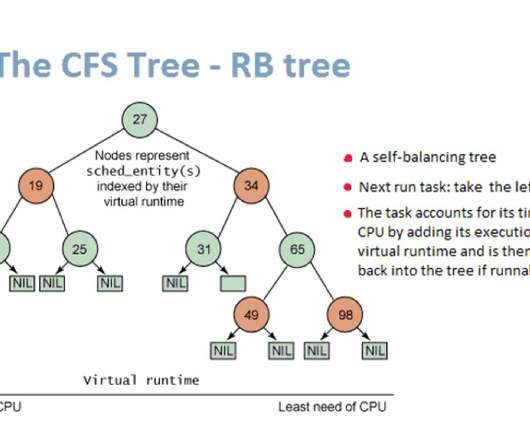
To find the answer – and optimize Linux containers – application developers and DevOps teams must understand how Linux schedules tasks and allocates them CPU time. But before committing to this strategy, it’s important to first determine how practical and achievable this is.
They use the same hardware, APIs, tools, and management controls for both the public and private clouds. Accordingly, these platforms provide a unified, consistent DevOps and IT experience. After deployment, IT teams can also optimize the software and supporting hardware to ensure high performance.
Logs can include data about user inputs, system processes, and hardware states. DevOps teams often use a log monitoring solution to ingest application, service, and system logs so they can detect issues at any phase of the software delivery life cycle (SDLC).
Indeed, according to one survey, DevOps practices have led to 60% of developers releasing code twice as quickly. IaC, or software intelligence as code , codifies and manages IT infrastructure in software, rather than in hardware. That can be difficult when the business climate can prioritize speed.
Network agility is represented by the volume of change in the network over a period of time and is defined as the capability for software and hardware component’s to automatically configure and control itself in a complex networking ecosystem. Organizations are in search of improving network agility, but what exactly does this mean?
Learn how security improves DevOps. As compliance is often a moving target, organizations are increasingly turning to automation across their DevOps, security, and compliance teams. What is DevSecOps? And what you need to do it well – blog DevSecOps connects three different disciplines: development, security, and operations.
Dynatrace Cloud Automation is an enterprise-grade control plane that extends intelligent observability, automation, and orchestration capabilities of the Dynatrace platform to DevOps pipelines. Infrastructure as code is sometimes referred to as programmable or software-defined infrastructure. Register now!
As the UFO is an Open Hardware & Open Source project , we’ve had people create their own UFOs in order to visualize stage or progress within their organization. Check out these two awesome videos: Dynatrace UFO DevOps Visualization & Dynatrace UFO controlled by a Mobile App.
As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments. In these modern environments, every hardware, software, and cloud infrastructure component and every container, open-source tool, and microservice generates records of every activity.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. Performing updates, installing software, and resolving hardware issues requires up to 17 hours of developer time every week.
A decade ago, while working for a large hosting provider, I led a team that was thrown into turmoil over the purchasing of server and storage hardware in preparation for a multi-million dollar super-bowl ad campaign. Dynatrace news.
If your application runs on servers you manage, either on-premises or on a private cloud, you’re responsible for securing the application as well as the operating system, network infrastructure, and physical hardware. What are some key characteristics of securing cloud applications?
In my role as DevOps and Autonomous Cloud Activist at Dynatrace, I get to talk to a lot of organizations and teams, and advise them on how to speed up delivery while also increasing the delivery in order to minimize the impact on operations. Dynatrace news.
Network Agility — the volume of change in the network over a period of time — the capability for software and hardware components to automatically configure and control itself in a complex networking ecosystem. What Is Network Agility?
These can be caused by hardware failures, or configuration errors, or external factors like cable cuts. A comprehensive DR plan with consistent testing is also critical to ensure that large recoveries work as expected. Network issues Network issues encompass problems with internet service providers, routers, or other networking equipment.
DevOps and cloud-based computing have existed in our life for some time now. DevOps is a casket that contains automation as its basic principle. Today, we are here to talk about the successful amalgamation of DevOps and cloud-based technologies that is amazing in itself. Why Opt For Cloud-Based Solutions and DevOps?
I wear many hats in my job and while I officially call myself a “ DevOps Activist “, my official title at Dynatrace is Director of Strategic Partners. Lift & Shift is where you basically just move physical or virtual hosts to the cloud – essentially you just run your host on somebody else’s hardware. Dynatrace news.
There were five trends and topics for 2021, Serverless First, Chaos Engineering, Wardley Mapping, Huge Hardware, Sustainability. As an outcome of the DevOps Enterprise Forum I collaborated on a paper called Building Industrial DevOps Stickiness by adding an introduction to Wardley Mapping to the story.
Redis Monitoring in DevOps Practices Integrating Redis monitoring into DevOps practices is a highly effective way of increasing the systems overall reliability and enabling continual enhancement. Taking protective measures like these now could protect both your data and hardware from future harm down the line. </p>
In this scenario, message queues coordinate large numbers of microservices, which operate autonomously without the need to provision virtual machines or allocate hardware resources. Message queue software options to consider.
In this scenario, message queues coordinate large numbers of microservices, which operate autonomously without the need to provision virtual machines or allocate hardware resources. Message queue software options to consider.
Redis® Monitoring in DevOps Practices Integrating Redis® monitoring into DevOps practices is a highly effective way of increasing the system’s overall reliability and enabling continual enhancement. Taking protective measures like these now could protect both your data and hardware from future harm down the line.
Traditionally, teams achieve this high level of uptime using a combination of high-capacity hardware, system redundancy, and failover models. An always-on infrastructure provides the foundation for system availability that can deliver five-nines availability.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
For decades, hardware advancements have kept many performance engineers on the sidelines, but now, in a pivotal moment, their skills are more crucial than ever. During the second day of QCon San Francisco 2023, Yao Yue, a Founder of IOP Systems, presented on performance engineering. By Steef-Jan Wiggers
Companies can use technology roadmaps to review their internal IT , DevOps, infrastructure, architecture, software, internal system, and hardware procurement policies and procedures with innovation and efficiency in mind. Make near-term decisions that don’t compromise future work. Gain awareness of which features are or aren’t working.
During compatibility testing of an application, we check the compatibility of the application with multiple devices, hardware, software versions, network, operating systems, and browsers, etc. During backward compatibility testing we will ensure that the latest application version is compatible with the older devices/ browsers/ hardware.
Software and hardware components are autonomous and execute tasks concurrently. A distributed system comprises of a variety of hardware and software components with different operating systems and technologies, meaning the processors are separate and independent of each other. State is distributed through the system. Concurrency.
Duties that DevOps engineers would typically perform (server management, scaling, provisioning, patching, etc.) Conclusion Knowing your project’s database requirements will be essential when choosing the services and hardware configuration you will pay your cloud service provider for.
It also encompasses a strategy and set of practices and principles across service offerings and is closely tied to DevOps and operations. To think about it another way, site reliability engineering is where the traditional IT role, or system administration role, and DevOps meet. At that time, the team was made up of software engineers.
However, 17% of organizations operate security separately from DevOps, lacking any DevSecOps initiatives. It comprises numerous organizations from various sectors, including software, hardware, nonprofit, public, and academic. The newly formed Open Source AI Alliance , led by META and IBM, promises to support open-source AI.
Mocking Component Behavior Useful in IoT & Embedded Software Testing Can also reduce (or eliminate) actual hardware/component need Test Reporting Generating summary report/email. Here is the link to the open-source version of Testsigma: testsigmahq/testsigma: Build stable and reliable end-to-end tests @ DevOps speed. github.com).
Recently I had great conversations with Troy Otillio, Senior Development Manager at Intuit and Jack Murgia, Senior DevOps Engineer at Edmodo. Amazon RDS removes the headaches of running a relational database service reliably at scale, allowing Amazon RDS customers to focus on innovation for their customers.
SREs and DevOps teams can use these incidents to build back better and improve their systems and services. Software services still require physical devices and hardware for them to function. However, as we are all aware, issues can slip through the cracks. What is an Incident? Asset Management.
Here are the three big directional bets that align with the three main areas cited by the authors: We will train in the cloud , where its possible to take advantage of managed infrastructure well suited to large amounts of data, spiky resource usage, and access to the latest hardware.
Continuous Testing is the testing strategy to fast-track the testing required for achieving rapid software development using Agile and DevOps methodologies. Unit tests and dev environments are usually taken care of by developers, whereas all other tests and environments are mainly considered the responsibility of testing and DevOps teams.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content