This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines.
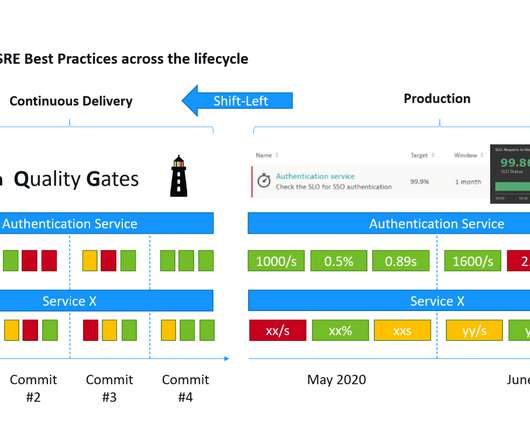
“This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments.
What should they do first to set your organization on the path to DevOps automation? By the time your SRE sets up these DevOps automation best practices, you have had to push unreliable releases into production. Most importantly, the right modern observability platform is key to a successful DevOps and SRE implementation.
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. They need automated DevOps practices.
To keep up with current demands, DevOps and platform engineering teams need a solution that can fully embrace and understand complexity, delivering precise answers that enable the creation of trustworthy automation. Automation + Synthetic = Perfect match This is why we integrated Synthetic monitoring in Workflows.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
It gives you visibility into which components are monitored and which are not and helps automate time-consuming compliance configuration checks. Discovery & Coverage helps prevent unexpected outages by detecting and remediating monitoring coverage gaps across your entire enterprise.
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. Continuous delivery seeks to make releases regular and predictable events for DevOps staff, and seamless for end-users.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
But are observability platforms—born from the collision between the demands of cloud computing and the limitations of APM and infrastructure monitoring—the best solution for managing business analytics? Observability fault lines The monitoring of complex and dynamic IT systems includes real-time analysis of baselines, trends, and anomalies.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. Mean time to respond (MTTR) is the average time it takes DevOps teams to respond after receiving an alert.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
Traditional monitoring approaches often require manual scripting and integration to get alerted about production-threatening issues in pre-production environments. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device.
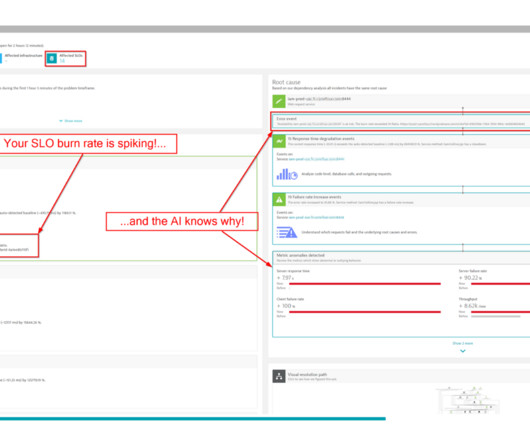
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. By analogy, envision an apple tree where an apple drops.
We are pleased to announce Atlassian has selected Dynatrace as a launch partner for its Open DevOps initiative, which combines Atlassian products and best-in-class solutions from key partners to deliver full lifecycle value to customers. Visit the Atlassian Marketplace to explore the integrations today.
IT, DevOps, and SRE teams are racing to keep up with the ever-expanding complexity of modern enterprise cloud ecosystems and the business demands they are designed to support. Observability is the new standard of visibility and monitoring for cloud-native architectures. Requirements to achieve multicloud observability and monitoring.
This trend is prompting advances in both observability and monitoring. But exactly what are the differences between observability vs. monitoring? Monitoring and observability provide a two-pronged approach. To get a better understanding of observability vs monitoring, we’ll explore the differences between the two.
To enable you to automatically detect the shutdown of spot instances and the scaling up or down of third-party autoscaling solutions, we’ve introduced a new event type. This event type lets you weave Dynatrace into your own autoscaling frameworks and inform Dynatrace about hosts that will soon be terminated.
AIOps offers an alternative to traditional infrastructure monitoring and management with end-to-end visibility and observability into IT stacks. But increasing complexity and lacking visibility creates a problem: Enterprises invest more resources into monitoring and don’t get the data and answers they need.
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. SLOs are pivotal for development, DevOps, and SRE teams because they provide a common language for discussing system reliability. What is SLO monitoring?
More specifically, I’ll demonstrate how in just a few steps, you can add Dynatrace information events to your Azure DevOps release pipelines for things like deployments, performance tests, or configuration changes. Microsoft DevOps Azure is one of the best CI/CD systems and a strategic technical Dynatrace partner. Dynatrace API.
And that includes infrastructure monitoring. Rather than just “keeping the lights on,” the modern I&O team must evolve to become responsible for building and maintaining the cloud platform, empowering DevOps teams to build, deploy and run applications themselves. Able to provide answers, not just data. Automatic and easy.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a software engineer takes nine hours to remediate a problem within a production application. Dynatrace Davis AI identifies the problem and maps the configuration change event to the root cause and the correct entity.
Dynatrace OneAgent is great for monitoring the full stack. While this will give you a lot of information about the health of these components, sometimes a simple synthetic monitor is sufficient. Third-party synthetic monitors. Visualize your synthetic monitor data. Easy and flexible infrastructure monitoring.
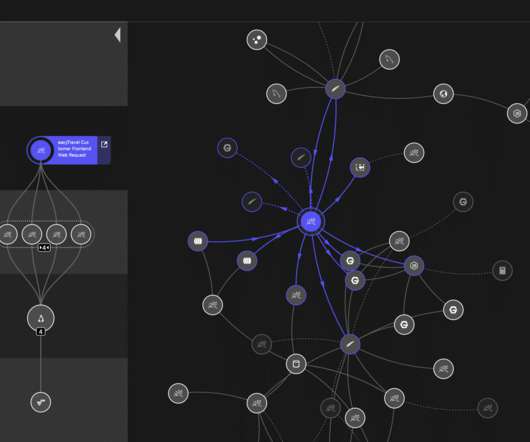
In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events. Event logging and software tracing help application developers and operations teams understand what’s happening throughout their application flow and system.
The time and effort saved with testing and deployment are a game-changer for DevOps. Rather than individually managing each container in a cluster, a DevOps team can instead tell Kubernetes how to allocate the necessary resources in advance. Built-in monitoring. Needs third party tools for monitoring. Observability.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. These phases must be aligned with security best practices, as discussed in A Beginner`s Guide to DevOps.
Early in my IT career, I worked in IT Ops and DevOps roles, building release deployment solutions for repeatable outcomes. The next phase of my amazement involves deep introspection into a monitoring and observability solution called Dynatrace. Traditional monitoring agents are programmed by a human with a threshold of specific events.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” All important health signals are highlighted.
Teams can no longer effectively manage and secure today’s multicloud environments using traditional monitoring tools. While conventional monitoring scans the environment using correlation and statistics, it provides little contextual information for remediating performance or security issues. Modern observability vs. monitoring.
Dynatrace Application Performance Management (APM) has long provided multiple options for database monitoring, including deep insights into code and statements, service level visibility, connection pool monitoring, and more. SRE teams, on the other hand, struggle for a comprehensive view across their environment.
Autonomous Cloud Enablement (ACE) and Keptn – the Event-Driven Autonomous Cloud Control Plane – are helping our Dynatrace customers to automate their delivery and operations processes. The Autonomous Cloud Maturity Path guides you through automating monitoring, performance, delivery and operations. Dynatrace news.
Behind the scenes working to meet this demand are DevOps teams, spinning up multicloud IT environments to accelerate digital transformation so their organizations can sustain growth at this new pace. Although these environments use fewer resources, they enable DevOps teams to deliver greater capabilities on a wider scale.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
Developing, deploying, and monitoring the release of native mobile apps is not an easy process. To effectively and efficiently get mobile apps out the door, monitor their performance, and manage subsequent releases, mobile DevOps practitioners can play an integral role. Error rate analysis.
As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments. What is the difference between monitoring and observability? Is observability really monitoring by another name? But what is observability? In short, no.
While the benefits of AIOps are plentiful — including increased automation, improved event prioritization and incident response, and accelerated digital transformation — applying AIOps use cases to an organization’s real-world operations issues can be challenging. CloudOps includes processes such as incident management and event management.
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. We’re using automation to kick off scaling events,” he said. “We It’s an enterprise product that we use to help modernize the VA,” Fuqua said.
Part 1 of this series starts will cover the key ingredients needed for successful DevOps use to deliver better software faster, followed by a short overview of GitHub Actions and example use cases related to deployment and release monitoring. Component levels information events such as releases and configuration changes.
Amplify PowerUP, our half-yearly global event to update our partner community, covered a lot of ground including key Partner Program announcements, Q2 earnings and partner contribution, market growth and momentum, Dynatrace platform capabilities, and the partner services offering the platform powers. It’s a different concept from monitoring.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content