This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
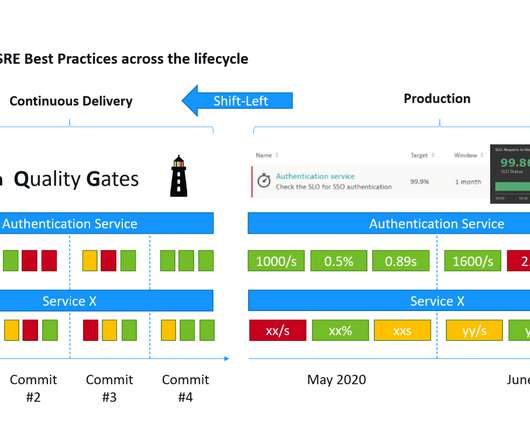
“This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Find and prevent application performance risks A major challenge for DevOps and security teams is responding to outages or poor application performance fast enough to maintain normal service.
This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation. To close these critical gaps, Dynatrace has defined a new class of events called business events.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges.
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
As a result, IT operations, DevOps , and SRE teams are all looking for greater observability into these increasingly diverse and complex computing environments. In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
A common challenge of DevOps teams is they get overwhelmed with too many alerts from their observability tools. DevOps teams don’t need just more noise—they need smarter alerting that is automatic, accurate, and actionable with precise root cause analysis. Demo: Add the human factor using the Dynatrace events API.
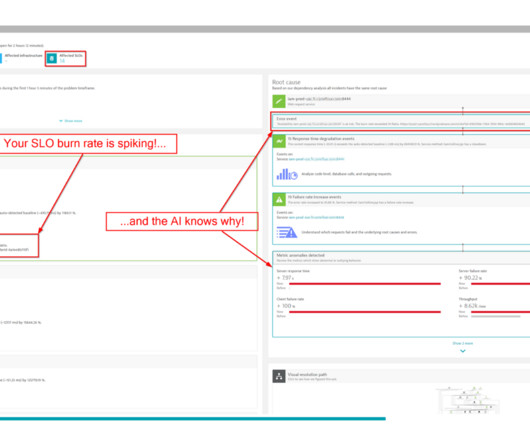
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. See the following example with BurnRate formula for Failure rate event.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. But there is a lack of time for DevOps , SRE , and developers to analyze all this data to identify whether there’s a user impacting problem and if so – what the root cause is to fix it fast. Dynatrace news.
Your teams want to iterate rapidly but face multiple hurdles: Increased complexity: Microservices and container-based apps generate massive logs and metrics. You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers. Its as simple as that!
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Logs, metrics, and traces make up the bulk of all telemetry data. The data life cycle has multiple steps from start to finish.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a software engineer takes nine hours to remediate a problem within a production application. Dynatrace Davis AI identifies the problem and maps the configuration change event to the root cause and the correct entity.
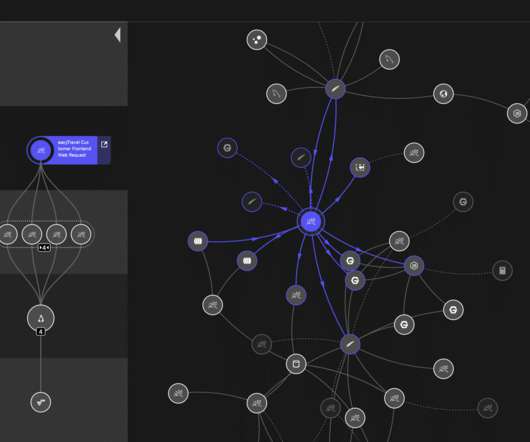
But this is often not as intuitively simple as it should be in other solutions where DevOps teams must click through a series of screens and dashboards to get to the root cause. Often, raised problems are the result of custom settings with fixed thresholds or the creation of custom events for alerting.
In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events. Metrics, logs , and traces make up three vital prongs of modern observability. Optimally stored logs enable DevOps, SecOps, and other IT teams to access them easily.
AIOps (Artificial Intelligence for IT Operations) is a cutting-edge solution that combines AI, ML, and automation to enhance DevOps practices and streamline IT operations. This helps DevOps teams make informed decisions, proactively detect and resolve issues, and improve overall operational efficiency.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. SLOs enable DevOps teams to predict problems before they occur and especially before they affect customer experience. The performance SLO needs a custom SLI metric, which you can configure as follows.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. A pipeline can be the parent of multiple tasks to group the resulting events logically.
Instead of immediately firing off an alert for all raw events, the Davis root-cause engine follows each violating service’s causal relationships. DevOps teams use this page to quickly identify and remediate unexpected incidences. DevOps teams use this page to quickly identify and remediate unexpected incidences.
The Visual Resolution Path offers a chronological overview of events detected by Dynatrace across all components linked to the underlying issue. Additionally, align the action’s validation window with the timeframe derived from the recently completed test events. Configure an action for the Site Reliability Guardian in the workflow.
The time and effort saved with testing and deployment are a game-changer for DevOps. Rather than individually managing each container in a cluster, a DevOps team can instead tell Kubernetes how to allocate the necessary resources in advance. Event logs for ad-hoc analysis and auditing. Observability.
In enterprise environments, DevOps and SRE teams struggle to optimize and troubleshoot databases and the applications they support at scale. DevOps teams are challenged to rapidly identify the root cause of issues without support from database administrators. Break down departmental silos and manage databases holistically.
An example of a critical event-based messaging service for many businesses is adding a product to a shopping cart. To know which services are impacted, DevOps teams need to know what’s happening with their messaging systems. Seamless observability of messaging systems is critical for DevOps teams. This is great!
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
Behind the scenes working to meet this demand are DevOps teams, spinning up multicloud IT environments to accelerate digital transformation so their organizations can sustain growth at this new pace. Although these environments use fewer resources, they enable DevOps teams to deliver greater capabilities on a wider scale.
While the benefits of AIOps are plentiful — including increased automation, improved event prioritization and incident response, and accelerated digital transformation — applying AIOps use cases to an organization’s real-world operations issues can be challenging. CloudOps includes processes such as incident management and event management.
Autonomous Cloud Enablement (ACE) and Keptn – the Event-Driven Autonomous Cloud Control Plane – are helping our Dynatrace customers to automate their delivery and operations processes. Dynatrace news. There’s more from Christian and the rest of the Keptn and Autonomous Cloud community that we can all benefit from.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” Ensure that you get the most out of your product.
Gartner defines AIOps as the combination of “big data and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination.” Typically, only the aggregated events will be accessible to ML and will often exclude additional details. What is AIOps?
Dynatrace enables various teams, such as developers, threat hunters, business analysts, and DevOps, to effortlessly consume advanced log insights within a single platform. DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks.
Amplify PowerUP, our half-yearly global event to update our partner community, covered a lot of ground including key Partner Program announcements, Q2 earnings and partner contribution, market growth and momentum, Dynatrace platform capabilities, and the partner services offering the platform powers. DevOps and Cloud Ops Automation.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. Amazon Data Firehose helps stream logs to the right destination But your SREs and DevOps engineers know CloudWatch is not the terminal destination for data but rather an intermediate station.
Every service and component exposes observability data (metrics, logs, and traces) that contains crucial information to drive digital businesses. Logs and events play an essential role in this mix; they include critical information which can’t be found anywhere else, like details on transactions, processes, users and environment changes.
In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior software engineer Yarden Laifenfeld explored developer observability. DevOps, SREs, developers… everyone will ask questions. When an incident occurs, developers need to know what data to look at, where the incident occurred, and other relevant metrics.
With the increasing adoption of agile software development, DevOps , progressive continuous delivery, and Site Reliability Engineering (SRE) practices, many companies are aiming to deliver better software faster and more safely while keeping up with customer demands. Following the evaluations, the results are logged in Dynatrace as events.
Closing the loop (or not) : In the event of a successful solution, the platform informs the appropriate teams and closes the loop. It is also a key metric for organizations looking to improve their DevOps performance. This metric represents the proportion of system incidents resolved by escalating to a higher level of support.
SLOs are specifically processed metrics that help businesses balance breakthroughs with reliability. SLOs are pivotal for development, DevOps, and SRE teams because they provide a common language for discussing system reliability. To manage this crucial aspect, many companies adopt service level objectives (SLOs).
A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. DevOps teams often use a log monitoring solution to ingest application, service, and system logs so they can detect issues at any phase of the software delivery life cycle (SDLC).
IT, DevOps, and SRE teams are racing to keep up with the ever-expanding complexity of modern enterprise cloud ecosystems and the business demands they are designed to support. It can empower teams to identify the effect of an incident quickly and pinpoint the cause of the specific behavior or event. Dynatrace news.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content