This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
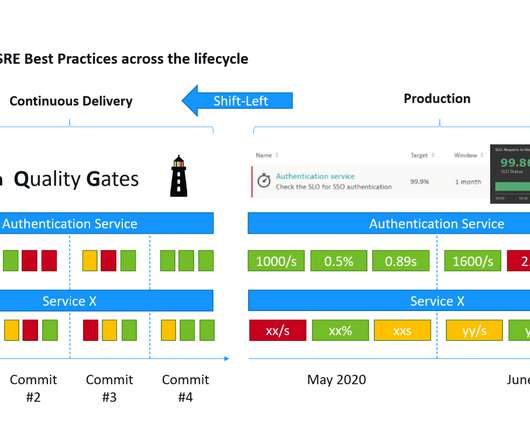
“This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Find and prevent application performance risks A major challenge for DevOps and security teams is responding to outages or poor application performance fast enough to maintain normal service.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges.
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. They need automated DevOps practices.
What should they do first to set your organization on the path to DevOps automation? By the time your SRE sets up these DevOps automation best practices, you have had to push unreliable releases into production. Most importantly, the right modern observability platform is key to a successful DevOps and SRE implementation.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
As organizations mature on their digital transformation journey, they begin to realize that automation – specifically, DevOps automation – is critical for rapid software delivery and reliable applications. “In fact, this is one of the major things that [hold] people back from really adopting DevOps principles.”
The events of 2020 accelerated the trend of organizations shifting to cloud-native technologies in response to the dramatic increase in demand for online services. Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. So which is it: SRE vs DevOps, or SRE and DevOps?
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. Continuous delivery seeks to make releases regular and predictable events for DevOps staff, and seamless for end-users.
A common challenge of DevOps teams is they get overwhelmed with too many alerts from their observability tools. DevOps teams don’t need just more noise—they need smarter alerting that is automatic, accurate, and actionable with precise root cause analysis. Demo: Add the human factor using the Dynatrace events API.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. That’s where Dynatrace business events and automation workflows come into play to provide a comprehensive view of your CI/CD pipelines.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. Mean time to respond (MTTR) is the average time it takes DevOps teams to respond after receiving an alert.
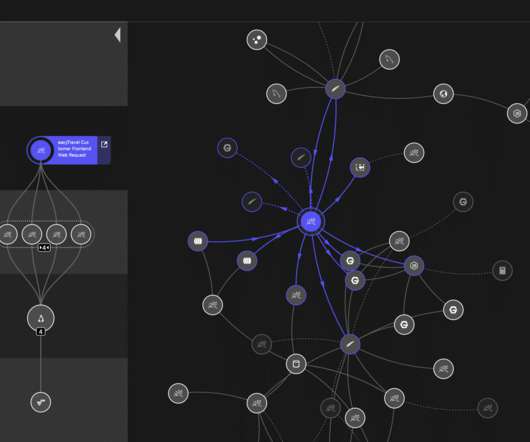
Such analysis is intentionally excluded from most observability solutions because payload details are unnecessary for DevOps purposes, problematic for agent overhead, and risky for data privacy. To close these critical gaps, Dynatrace has defined a new class of events called business events.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
The first part of this blog post briefly explores the integration of SLO events with AI. Consequently, the AI is founded upon the related events, and due to the detection parameters (threshold, period, analysis interval, frequent detection, etc), an issue arose. See the following example with BurnRate formula for Failure rate event.
We are pleased to announce Atlassian has selected Dynatrace as a launch partner for its Open DevOps initiative, which combines Atlassian products and best-in-class solutions from key partners to deliver full lifecycle value to customers. Visit the Atlassian Marketplace to explore the integrations today.
To enable you to automatically detect the shutdown of spot instances and the scaling up or down of third-party autoscaling solutions, we’ve introduced a new event type. This event type lets you weave Dynatrace into your own autoscaling frameworks and inform Dynatrace about hosts that will soon be terminated.
More specifically, I’ll demonstrate how in just a few steps, you can add Dynatrace information events to your Azure DevOps release pipelines for things like deployments, performance tests, or configuration changes. Microsoft DevOps Azure is one of the best CI/CD systems and a strategic technical Dynatrace partner. Dynatrace API.
This enables DevOps platform engineers to make the right release decisions for new versions and empowers SREs to apply Service-Level Objectives (SLOs) for their critical services. Workflows can be triggered manually, on a schedule, or by events in Dynatrace, such as anomalies detected by Davis AI.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Are you experiencing an increase or degradation in certain events that indicate a rising problem?
You can select any trigger thats available for standard workflows, including schedules, problem triggers, customer event triggers, or on-demand triggers. Here, you can select a specific event or a timed trigger like a cronjob. You can learn more about event triggers in Dynatrace Documentation. Its as simple as that!
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a software engineer takes nine hours to remediate a problem within a production application. Dynatrace Davis AI identifies the problem and maps the configuration change event to the root cause and the correct entity.
To keep up with current demands, DevOps and platform engineering teams need a solution that can fully embrace and understand complexity, delivering precise answers that enable the creation of trustworthy automation. The effectiveness of this automation relies on the quality of the underlying data.
AIOps (Artificial Intelligence for IT Operations) is a cutting-edge solution that combines AI, ML, and automation to enhance DevOps practices and streamline IT operations. This helps DevOps teams make informed decisions, proactively detect and resolve issues, and improve overall operational efficiency.
AI and DevOps, of course The C suite is also betting on certain technology trends to drive the next chapter of digital transformation: artificial intelligence and DevOps. DevOps methodology—which brings development and ITOps teams together—also forwards digital transformation. And according to Statista , $2.4
This causes challenges for DevOps and SRE teams when extending the lifecycle with additional steps, integrating new third-party software such as pipeline tools or ITSM tools, or just replacing one tool with another. Dynatrace helps to orchestrate processes independently of DevOps tooling. A guide to event-driven SRE-inspired DevOps.
NoOps, or “no operations,” emerged as a concept alongside DevOps and the push to automate the CI/CD pipelines as early as 2010. For most teams, evolving their DevOps practices has been challenging enough. DevOps requires infrastructure experts and software experts to work hand in hand.
Data-driven applications span a wide breadth of complexity, from simple microservices to real-time event-driven systems under significant load. However, as any development and/or DevOps team tasked with performance improvements will attest, making data-driven apps fast globally is “non-trivial”. Guest post by Ben Hagan from PolyScale.ai
In cloud-native environments, there can also be dozens of additional services and functions all generating data from user-driven events. Event logging and software tracing help application developers and operations teams understand what’s happening throughout their application flow and system.
The time and effort saved with testing and deployment are a game-changer for DevOps. Rather than individually managing each container in a cluster, a DevOps team can instead tell Kubernetes how to allocate the necessary resources in advance. Event logs for ad-hoc analysis and auditing. Observability.
For example, 73% of technology leaders are investing in AI to generate insight from observability, security, and business events data. DevOps teams , for example, can focus on driving innovation instead of grinding through manual jobs. This means greater productivity for individual teams.
The Dynatrace integration leverages native features and events that pass through the pipeline. Events serve as logic operators that can trigger or stop subsequent tasks within the pipeline. Embracing the tenets of DevOps and DevSecOps methodologies anchored in engineering principles. However, this is highly unlikely.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. These phases must be aligned with security best practices, as discussed in A Beginner`s Guide to DevOps.
Understanding the difference between observability and monitoring helps DevOps teams understand root causes and deliver better applications. DevOps and DevSecOps orchestration. DevOps brings developers and operations teams together and enables more agile IT. What is DevOps? Learn how security improves DevOps.
While the benefits of AIOps are plentiful — including increased automation, improved event prioritization and incident response, and accelerated digital transformation — applying AIOps use cases to an organization’s real-world operations issues can be challenging. CloudOps includes processes such as incident management and event management.
Many organizations realize their DevOps tools and practices do not sufficiently account for security. The security challenges of DevOps. To set the stage for a security-as-code culture, Stewart explained how DevSecOps is a cross-team collaboration framework that responds to the security challenges of DevOps. Dynatrace news.
Autonomous Cloud Enablement (ACE) and Keptn – the Event-Driven Autonomous Cloud Control Plane – are helping our Dynatrace customers to automate their delivery and operations processes. Dynatrace news. There’s more from Christian and the rest of the Keptn and Autonomous Cloud community that we can all benefit from.
We are pleased to announce Atlassian has selected Dynatrace as a launch partner for its Open DevOps initiative, which combines Atlassian products and best-in-class solutions from key partners to deliver full lifecycle value to customers. Visit the Atlassian Marketplace to explore the integrations today.
With the increasing adoption of agile software development, DevOps , progressive continuous delivery, and Site Reliability Engineering (SRE) practices, many companies are aiming to deliver better software faster and more safely while keeping up with customer demands. Following the evaluations, the results are logged in Dynatrace as events.
In enterprise environments, DevOps and SRE teams struggle to optimize and troubleshoot databases and the applications they support at scale. DevOps teams are challenged to rapidly identify the root cause of issues without support from database administrators. Break down departmental silos and manage databases holistically.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
Instead of immediately firing off an alert for all raw events, the Davis root-cause engine follows each violating service’s causal relationships. DevOps teams use this page to quickly identify and remediate unexpected incidences. Usually, the journey doesn’t stop here.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content