This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s how Dynatrace can help automate up to 80% of technical tasks required to manage compliance and resilience: Understand the complexity of IT systems in real time Proactively prevent, prioritize, and efficiently manage performance and security incidents Automate manual and routine tasks to increase your productivity 1.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOpsengineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .” Atlassian Jira.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively.
Over the past decade, DevOps has emerged as a new tech culture and career that marries the rapid iteration desired by software development with the rock-solid stability of the infrastructure operations team. As of August 2019, there are currently over 50,000 LinkedIn DevOps job listings in the United States alone.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. They need automated DevOps practices.
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
With hands-on experience in AWS DevOps and Google SRE, I’d like to offer my insights on the comparison of these two systems. In this article, I’ll give a brief overview of AWS DevOps and Google SRE , examine when they work best, delve into potential pitfalls to avoid, and provide tips for maximizing the benefits of each.
As organizations become cloud-native and their environments more complex, DevOps teams are adapting to new challenges. Site reliability engineering first emerged to address cloud computing’s new performance needs. Understanding the platform engineer role DevOps is a constantly evolving discipline.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE bridges the gap between Dev and Ops teams.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Organizations are increasingly adopting DevOps to stay competitive, innovate faster, and meet customer needs. By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Thankfully, DevOps orchestration has evolved to address these problems. What is orchestration?
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. We refer to this culture and practice as observability-driven DevOps and SRE automation. The role of observability within DevOps. The results of observability-driven DevOps speak for themselves.
We are proud to s hare Dynatrace has been named the winner in the “ Best Overall AI-based Analytics Company ” category, recognized for our innovation and the business-driving impact of our AI engine, Davis. . The post Dynatrace wins AI Breakthrough Award for Davis AI engine appeared first on Dynatrace blog.
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. When they check in their code, the build management system automatically creates a build and tests it.
In the dynamic realm of modern software development and operations, terms such as Platform Engineering, DevOps, and Site Reliability Engineering (SRE) are frequently used, sometimes interchangeably, often causing confusion among professionals entering or navigating these domains.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. DevOps teams must constantly adapt by using agile methodologies and rapid delivery models, such as CI/CD.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Operations teams want to make sure the system doesn’t break. Too many SLOs create complexity for DevOps. Dynatrace news.
Messaging systems can significantly improve the reliability, performance, and scalability of the communication processes between applications and services. In serverless and microservices architectures, messaging systems are often used to build asynchronous service-to-service communication. Dynatrace news. This is great!
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. This does not include lag time in the alert system.
Planned effort Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains: Operations Management (50%) Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. These tasks collectively ensure uninterrupted production service.
I spoke with Martin Spier, PicPay’s VP of Engineering, about the challenges PicPay experienced and the Kubernetes platform engineering strategy his team adopted in response. “Our development teams relied heavily on logs to understand what was going on with our systems,” he said. billion. .
Many organizations that have integrated their software development and operations into DevOps practices struggle with efficiency because they’re juggling disparate DevOps tools, or their tools aren’t meeting their needs. The status quo of the DevOps toolchain. How to approach transforming your DevOps processes.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges. Has the user purchased this product before?
Whether it means jumping between multiple windows, sifting through extensive logs to track down bugs, trying to reproduce locally, or requesting additional redeployments from DevOps, debugging poses significant challenges and a resource drain. Source code is loaded only on an engineers workstation, using the engineers privileges.
As organizations continue to modernize their technology stacks, many turn to Kubernetes , an open source container orchestration system for automating software deployment, scaling, and management. Five of the most common include cluster instability, resource and cost management, security, observability, and stress on engineering teams.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.
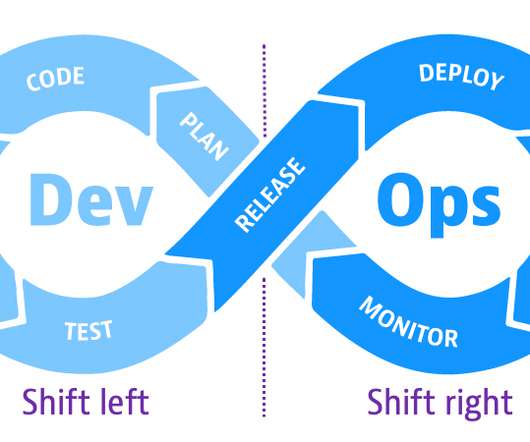
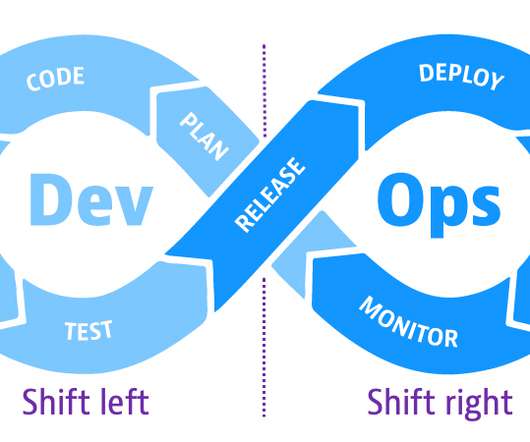
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Dynatrace product marketing director of DevOps Saif Gunja hosted the 2023 State of SRE webinar. Teams should ensure that even the smallest SLOs relate to business growth.
Site reliability engineering (SRE) continues to gain popularity as organizations embrace hybrid cloud strategies and IT automation at scale. By applying software engineering principles to operations and infrastructure practices, SRE enables organizations to streamline and automate IT processes. Dynatrace news.
Artisan Crafted Images In the Netflix full cycle DevOps culture the team responsible for building a service is also responsible for deploying, testing, infrastructure, and operation of that service. A key responsibility of Netflix engineers is identifying gaps and pain points in the development and operation of services.
Everything you need to know about performance engineering. As highly distributed apps become more complex, developers need to ensure their systems are as user-friendly, secure, and scalable as possible. You may also like: A Short History of Performance Engineering.
Site reliability engineering (SRE) is a discipline in which automated software systems are built to manage the development operations (DevOps) of a product or service. In other words, SRE automates the functions of an operations team via software systems.
Whether you're a developer, DevOpsengineer, or IT manager, this will help you make a smart choice for your monitoring needs. It combines two earlier projects, OpenCensus and OpenTracing, and gives you a unified, vendor-neutral way to monitor systems. But how do you know which one is best for you?
In Part 1 we explored how DevOps teams can prevent a process crash from taking down services across an organization in five easy steps. In this alert, xMatters includes all the important incident information from Dynatrace, so there’s no need for you to visit additional system dashboards. xMatters creates and updates Jira issues.
More specifically, I’ll demonstrate how in just a few steps, you can add Dynatrace information events to your Azure DevOps release pipelines for things like deployments, performance tests, or configuration changes. Microsoft DevOps Azure is one of the best CI/CD systems and a strategic technical Dynatrace partner.
But because of the complexity involved in executing and analyzing test results of dynamic systems, performance engineering is difficult to scale — especially with lean staff or resources. Grabner also introduced four ways organizations can turbocharge their performance engineering with automation. Automating root cause analysis.
When the actual land around your cities is burning, and all of your emergency services are working at full capacity, the systems that are behind those teams must be even more reliable than those on a trading floor or in an airplane. The post Keeping DevOps cool in a heated environment appeared first on Dynatrace blog.
Technology and operations teams work to ensure that applications and digital systems work seamlessly and securely. Predictive AI uses statistical algorithms and other advanced machine learning techniques to anticipate what might happen next in a system. This data-driven approach fosters continuous refinement of processes and systems.
GPT (generative pre-trained transformer) technology and the LLM-based AI systems that drive it have huge implications and potential advantages for many tasks, from improving customer service to increasing employee productivity. To do this effectively, the input from prompt engineering needs to be trustworthy and actionable.
Editor's Note: The following is an article written for and published in DZone's 2024 Trend Report, The Modern DevOps Lifecycle: Shifting CI/CD and Application Architectures. By integrating observability tools in CI/CD pipelines, organizations can increase deployment frequency, minimize risks, and build highly available systems.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content