This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DevOps and Site Reliability Engineering (SRE) both seem to rule the world of software development, and at the same time, both appear to overlap or confuse people to some extent. DevOpsEngineer. Today, we will try to analyze both terms and see if we can see some differentiating factors between the two.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOpsengineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? .”
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Moreover, observability is the launchpad for maturing DevOps and platform engineering postures. However, these practices cannot stand alone.
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. The result is a cloud-native approach to software delivery. Why is platform engineering important?
Over the past decade, DevOps has emerged as a new tech culture and career that marries the rapid iteration desired by software development with the rock-solid stability of the infrastructure operations team. As of August 2019, there are currently over 50,000 LinkedIn DevOps job listings in the United States alone.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively.
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. They need automated DevOps practices.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. According to recent Dynatrace research , organizations expect to make software updates 58% more frequently in the coming year.
Cloud-native environments bring speed and agility to software development and operations (DevOps) practices. So which is it: SRE vs DevOps, or SRE and DevOps? DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. DevOps as a philosophy.
As organizations become cloud-native and their environments more complex, DevOps teams are adapting to new challenges. Site reliability engineering first emerged to address cloud computing’s new performance needs. Understanding the platform engineer role DevOps is a constantly evolving discipline.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. In fact, the Dynatrace 2023 CIO Report found that 78% of respondents deploy software updates every 12 hours or less. What is DevOps monitoring?
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of softwareengineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
Staying ahead of customer needs requires speed and agility from all phases of the software development life cycle (SDLC). DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation?
Congratulations, you’ve just hired your first Site Reliability Engineer (SRE)! What should they do first to set your organization on the path to DevOps automation? Develop software to measure SLOs and track releases? Most importantly, the right modern observability platform is key to a successful DevOps and SRE implementation.
Organizations are increasingly adopting DevOps to stay competitive, innovate faster, and meet customer needs. By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Thankfully, DevOps orchestration has evolved to address these problems.
What is site reliability engineering? Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Dynatrace news. SRE bridges the gap between Dev and Ops teams.
But with many organizations relying on traditional, manual processes to ensure service reliability and code quality, software delivery speed suffers. As a result, organizations are investing in DevOps automation to meet the need for faster, more reliable innovation. Automation is a crucial aspect of achieving DevOps excellence.
Today, speed and DevOps automation are critical to innovating faster, and platform engineering has emerged as an answer to some of the most significant challenges DevOps teams are facing. With higher demand for innovation, IT teams are working diligently to release high-quality software faster.
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. As Deloitte reports, continuous integration (CI) streamlines the process of internal software development.
Yet as software environments become more complex, there are more ways than ever for malicious actors to exploit vulnerabilities, even in the application development and delivery pipeline. DevSecOps is the practice of integrating security into the DevOps workflow. Why application security measures are failing.
As organizations mature on their digital transformation journey, they begin to realize that automation – specifically, DevOps automation – is critical for rapid software delivery and reliable applications. “In fact, this is one of the major things that [hold] people back from really adopting DevOps principles.”
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
DevOps automation eliminates extraneous manual processes, enabling DevOps teams to develop, test, deliver, deploy, and execute other key processes at scale. Automation can be particularly powerful when applied to DevOps workflows. Automation thus contributes to accelerated productivity and innovation across the organization.
ChatGPT and generative AI: A new world of innovation Software development and delivery are key areas where GPT technology such as ChatGPT shows potential. For example, it can help DevOps and platform engineering teams write code snippets by drawing on information from software libraries.
Customers ingest these findings to Dynatrace and track software quality and security from development to production. With Dynatrace in pre-production, they validate software before deployment and secure it in production, automatically leveraging a dynamic bill of materials to assess both first- and third-party software.
In the dynamic realm of modern software development and operations, terms such as Platform Engineering, DevOps, and Site Reliability Engineering (SRE) are frequently used, sometimes interchangeably, often causing confusion among professionals entering or navigating these domains.
We are proud to s hare Dynatrace has been named the winner in the “ Best Overall AI-based Analytics Company ” category, recognized for our innovation and the business-driving impact of our AI engine, Davis. . The post Dynatrace wins AI Breakthrough Award for Davis AI engine appeared first on Dynatrace blog.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. We refer to this culture and practice as observability-driven DevOps and SRE automation. The role of observability within DevOps. The results of observability-driven DevOps speak for themselves.
Site reliability engineering (SRE) is the practice of applying softwareengineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. ” According to Google, “SRE is what you get when you treat operations as a software problem.”
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. SLOs are a great way to define what software should do. Dynatrace news.
The average deployment now spans 20 clusters running 10 or more software elements across clouds and data centers. I spoke with Martin Spier, PicPay’s VP of Engineering, about the challenges PicPay experienced and the Kubernetes platform engineering strategy his team adopted in response.
Planned effort Site Reliability Engineering (SRE) effort and time allocation planning typically fall into two domains: Operations Management (50%) Operations Management includes on-call responsibilities, post-mortem assessments, addressing other interruptions, and buffer time. It also returns valuable time back to the SRE team.
This leads to frustrating bottlenecks for developers attempting to build and deliver software. In such contexts, platform engineering offers a compelling solution to enable business competitiveness in a manner that significantly enhances the developer experience.
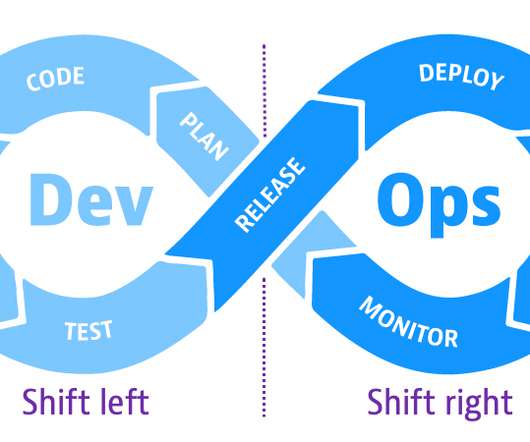
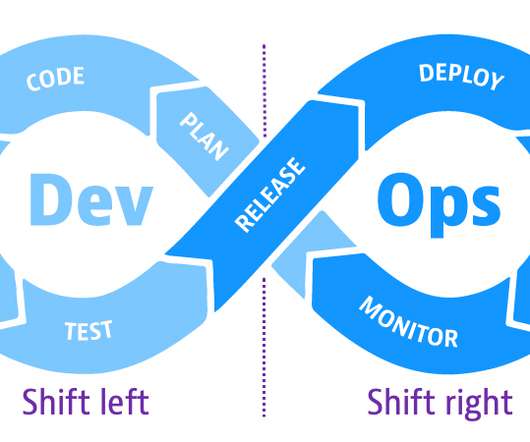
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Conventional testing practices have mainly focused on discovering problems before the software is released to the market, also referred to as shift-left testing. This is where shift-right testing comes in.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges. Has the user purchased this product before?
Every software developer has faced the frustration of debugging. Whether it means jumping between multiple windows, sifting through extensive logs to track down bugs, trying to reproduce locally, or requesting additional redeployments from DevOps, debugging poses significant challenges and a resource drain.
Many organizations that have integrated their software development and operations into DevOps practices struggle with efficiency because they’re juggling disparate DevOps tools, or their tools aren’t meeting their needs. The status quo of the DevOps toolchain.
When organizations implement SLOs, they can improve software development processes and application performance. SLOs improve software quality. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time.
In today’s digital world, software is everywhere. Software is behind most of our human and business interactions. This, in turn, accelerates the need for businesses to implement the practice of software automation to improve and streamline processes. What is software automation? What is software analytics?
Why organizations are turning to software development to deliver business value. Digital immunity has emerged as a strategic priority for organizations striving to create secure software development that delivers business value. Software development success no longer means just meeting project deadlines.
As organizations continue to modernize their technology stacks, many turn to Kubernetes , an open source container orchestration system for automating software deployment, scaling, and management. Five of the most common include cluster instability, resource and cost management, security, observability, and stress on engineering teams.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. Mean time to respond (MTTR) is the average time it takes DevOps teams to respond after receiving an alert.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content