This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.
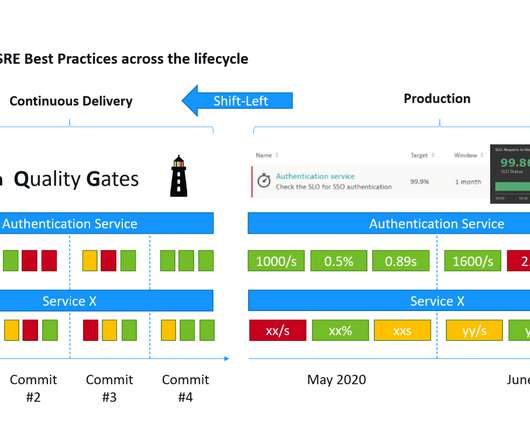
This is a mouthful of buzzwords” is how I started my recent presentations at the Online Kubernetes Meetup as well as the DevOps Fusion 2020 Online Conference when explaining the three big challenges we are trying to solve with Keptn – our CNCF Open Source project: Automate build validation through SLI/SLO-based Quality Gates. Dynatrace news.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. Such fragmented approaches fall short of giving teams the insights they need to run IT and site reliability engineering operations effectively.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
In response to this shift, platform engineering is growing in popularity. The practice of platform engineering has evolved alongside the increasing complexity of cloud environments. Platform engineers design and implement these platforms, as well as ensure their security, scalability, and reliability.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
Platform engineering is on the rise. According to leading analyst firm Gartner, “80% of software engineering organizations will establish platform teams as internal providers of reusable services, components, and tools for application delivery…” by 2026.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
As a result, organizations are investing in DevOps automation to meet the need for faster, more reliable innovation. Automation is a crucial aspect of achieving DevOps excellence. But according to the 2023 DevOps Automation Pulse , only 56% of end-to-end DevOps processes are automated.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The pair showed how to track factors including developer velocity, platform adoption, DevOps research and assessment metrics, security, and operational costs.
I spoke with Martin Spier, PicPay’s VP of Engineering, about the challenges PicPay experienced and the Kubernetes platform engineering strategy his team adopted in response. Taking a strategic Kubernetes platform engineering approach Spier noted that keeping Kubernetes simple requires a strategic approach.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running?, Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue. So, what is MTTR?
We are proud to s hare Dynatrace has been named the winner in the “ Best Overall AI-based Analytics Company ” category, recognized for our innovation and the business-driving impact of our AI engine, Davis. . The post Dynatrace wins AI Breakthrough Award for Davis AI engine appeared first on Dynatrace blog.
When it comes to site reliability engineering (SRE) initiatives adopting DevOps practices, developers and operations teams frequently find themselves at odds with one another. Too many SLOs create complexity for DevOps. With many pipelines to maintain, DevOps teams need automated orchestration. Dynatrace news.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. We refer to this culture and practice as observability-driven DevOps and SRE automation. The role of observability within DevOps. The results of observability-driven DevOps speak for themselves.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? The state of service-level objectives While SLOs play a critical role in helping DevOps and SRE teams align technical objectives with business goals, they’re not always easy to define.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. But there is a lack of time for DevOps , SRE , and developers to analyze all this data to identify whether there’s a user impacting problem and if so – what the root cause is to fix it fast. Dynatrace news.
In the world of DevOps and SRE, DevOps automation answers the undeniable need for efficiency and scalability. Though the industry champions observability as a vital component, it’s become clear that teams need more than data on dashboards to overcome persistent DevOps challenges. Has the user purchased this product before?
Five of the most common include cluster instability, resource and cost management, security, observability, and stress on engineering teams. Engineering teams are overwhelmed with stuff to do.” ” First, Akamas collects metrics, then recommends configuration improvements and applies these recommendations.
Service-level objectives (SLOs) are a great tool to align business goals with the technical goals that drive DevOps (Speed of Delivery) and Site Reliability Engineering (SRE) (Ensuring Production Resiliency). In the workshop, I also answered the question: How can we measure those metrics (=SLIs) that are behind our objectives?
This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation. Introducing metric extraction from business events Beginning with Dynatrace SaaS version 1.257, you can extract metrics from ingested business events.
Dynatrace industry-leading tracing, metrics, and log ingestion provide the level of high fidelity data that teams need to make accurate predictions about capacity. Such decisions must be attainable with little to no developer involvement in surfacing traces, metrics, and logs. Rapid OneAgent rollouts on Google Kubernetes Engine.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. These tags will allow us to create dashboards, request attributes or calculate service metrics specifically for our application under test. This allows us to analyze metrics (SLIs) for each individual endpoint URL.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Depending on the environment, the different information types provide indicators that reveal potential problems for your customers.
Site reliability engineering (SRE) has become increasingly important to organizations looking to keep up with the rapid pace of digital transformation. Dynatrace product marketing director of DevOps Saif Gunja hosted the 2023 State of SRE webinar. Teams should ensure that even the smallest SLOs relate to business growth.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Whatever your use case, when log data reflects changes in your infrastructure or business metrics, you need to extract the metrics and monitor them.
Artisan Crafted Images In the Netflix full cycle DevOps culture the team responsible for building a service is also responsible for deploying, testing, infrastructure, and operation of that service. A key responsibility of Netflix engineers is identifying gaps and pain points in the development and operation of services.
When it comes to platform engineering, not only does observability play a vital role in the success of organizations’ transformation journeys—it’s key to successful platform engineering initiatives. The various presenters in this session aligned platform engineering use cases with the software development lifecycle.
But because of the complexity involved in executing and analyzing test results of dynamic systems, performance engineering is difficult to scale — especially with lean staff or resources. Grabner also introduced four ways organizations can turbocharge their performance engineering with automation.
But this is often not as intuitively simple as it should be in other solutions where DevOps teams must click through a series of screens and dashboards to get to the root cause. The post Identify issues immediately with actionable metrics and context in Dynatrace Problem view appeared first on Dynatrace blog.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. Amazon Data Firehose helps stream logs to the right destination But your SREs and DevOpsengineers know CloudWatch is not the terminal destination for data but rather an intermediate station.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time.
Problem remediation is too time-consuming According to the DevOps Automation Pulse Survey 2023 , on average, a software engineer takes nine hours to remediate a problem within a production application. With that, Software engineers, SREs, and DevOps can define a broad automation and remediation mapping.
To know which services are impacted, DevOps teams need to know what’s happening with their messaging systems. Seamless observability of messaging systems is critical for DevOps teams. As a result, DevOps teams usually spend a significant amount of time troubleshooting anomalies, resulting in high MTTR and SLO violations.
As a result, site reliability has emerged as a critical success metric for many organizations. Site reliability engineering (SRE) has recently become a critical discipline in recent years as the world has shifted in favor of web-based interactions. That’s why good communication between SREs and DevOps teams is important.
Predictive AI empowers site reliability engineers (SREs) and DevOpsengineers to detect anomalies and irregular patterns in their systems long before they escalate into critical incidents. Through predictive analytics, SREs and DevOpsengineers can accurately forecast resource needs based on historical data.
The time and effort saved with testing and deployment are a game-changer for DevOps. Running containers : Docker Engine is a container runtime that runs in almost any environment: Mac and Windows PCs, Linux and Windows servers, the cloud, and on edge devices. In production, containers are easy to replicate. What is Kubernetes?
For software engineering teams, this demand means not only delivering new features faster but ensuring quality, performance, and scalability too. One way to apply improvements is transforming the way application performance engineering and testing is done. Here is the definition of this model: ?. Try it today using Keptn .
Doing so reduces the risk of production disruptions and instills confidence in both SREs (Site Reliability Engineers) and end-users. This view seamlessly correlates crucial events across all affected components, eliminating the manual effort of sifting through various monitoring tools for infrastructure, process, or service metrics.
To accomplish this, organizations have widely adopted DevOps , which encompasses significant changes to team culture, operations, and the tools used throughout the continuous development lifecycle. Key components of GitOps are declarative infrastructure as code, orchestration, and observability.
Powered by Grail and the Dynatrace AutomationEngine , Site Reliability Guardian helps DevOps platform teams make better-informed release decisions by utilizing all the contextual observability and application security insights of the Dynatrace platform. This is where Site Reliability Engineering (SRE) practices are applied.
In enterprise environments, DevOps and SRE teams struggle to optimize and troubleshoot databases and the applications they support at scale. DevOps teams are challenged to rapidly identify the root cause of issues without support from database administrators. Easily track the health and performance of database servers with AI support.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content