This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOpsmonitoring tools has grown exponentially. But when and how does DevOpsmonitoring fit into the process? And how do DevOpsmonitoring tools help teams achieve DevOpsefficiency?
As more organizations embrace DevOps and CI/CD pipelines, GitHub-hosted runners and GitHub Actions have emerged as powerful tools for automating workflows. Let’s explore some of the advantages of monitoring GitHub runners using Dynatrace. Extending this visibility into your CI/CD pipelines offers even greater value.
DevOps and security teams managing today’s multicloud architectures and cloud-native applications are facing an avalanche of data. On average, organizations use 10 different tools to monitor applications, infrastructure, and user experiences across these environments.
Why manual audits and custom scripts fall short for Kubernetes security posture management In the dynamic and complex world of Kubernetes, relying on manual audits, custom scripts, and general-purpose security tools is no longer enough to achieve efficient security posture management. Here’s why: Misconfigurations are pervasive.
Takeaways from this article on DevOps practices: DevOps practices bring developers and operations teams together and enable more agile IT. Still, while DevOps practices enable developer agility and speed as well as better code quality, they can also introduce complexity and data silos. They need automated DevOps practices.
DevOps automation can help to drive reliability across the SDLC and accelerate time-to-market for software applications and new releases. What is DevOps automation? DevOps automation is a set of tools and technologies that perform routine, repeatable tasks that engineers would otherwise do manually.
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Further, automation has become a core strategy as organizations migrate to and operate in the cloud.
Organizations are increasingly adopting DevOps to stay competitive, innovate faster, and meet customer needs. By helping teams release new software more frequently, DevOps practices are an essential component of digital transformation. Thankfully, DevOps orchestration has evolved to address these problems. What is orchestration?
You have set up a DevOps practice. As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. DevOps metrics to help you meet your DevOps goals. Dynatrace news.
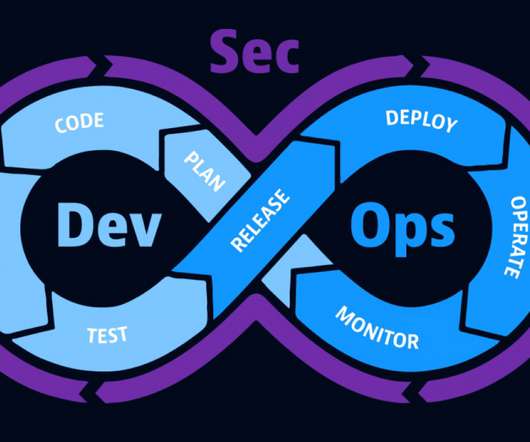
DevOps seeks to accomplish smooth and efficient software creation, delivery, monitoring, and improvement by prioritizing agility and adaptability over rigid, stage-by-stage development. What is DevOps? DevOps looks to eliminate these silos by creating a combined process that focuses on visibility-powered collaboration.
As organizations accelerate innovation to keep pace with digital transformation, DevOps observability is becoming a critical key to success for DevOps and DevSecOps teams. DevOps and DevSecOps practices help organizations release software faster and more frequently, paving the way for digital transformation.
To keep up with current demands, DevOps and platform engineering teams need a solution that can fully embrace and understand complexity, delivering precise answers that enable the creation of trustworthy automation. Automation + Synthetic = Perfect match This is why we integrated Synthetic monitoring in Workflows.
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Rather, they must be bolstered by additional technological investments to ensure reliability, security, and efficiency. However, these practices cannot stand alone.
As cloud-native, distributed architectures proliferate, the need for DevOps technologies and DevOps platform engineers has increased as well. DevOps engineer tools can help ease the pressure as environment complexity grows. ” What does a DevOps platform engineer do? A DevOps platform engineer is a more recent term.
Here’s how Dynatrace can help automate up to 80% of technical tasks required to manage compliance and resilience: Understand the complexity of IT systems in real time Proactively prevent, prioritize, and efficiently manage performance and security incidents Automate manual and routine tasks to increase your productivity 1.
To meet this demand, organizations are adopting DevOps practices , such as continuous integration and continuous delivery, and the related practice of continuous deployment, referred to collectively as CI/CD. Smooth, regular merging helps software development teams complete projects more quickly and efficiently.
Just as organizations have increasingly shifted from on-premises environments to those in the cloud, development and operations teams now work together in a DevOps framework rather than in silos. But as digital transformation persists, new inefficiencies are emerging and changing the future of DevOps.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF. Mean time to respond (MTTR) is the average time it takes DevOps teams to respond after receiving an alert.
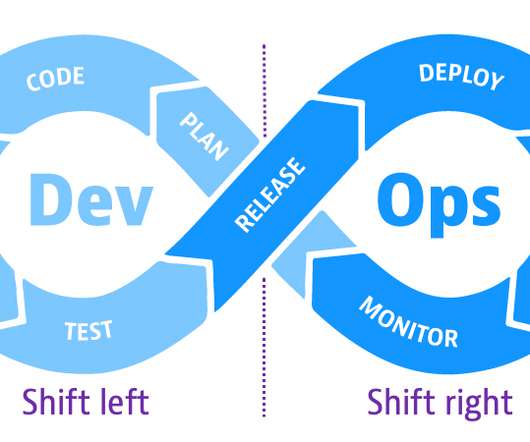
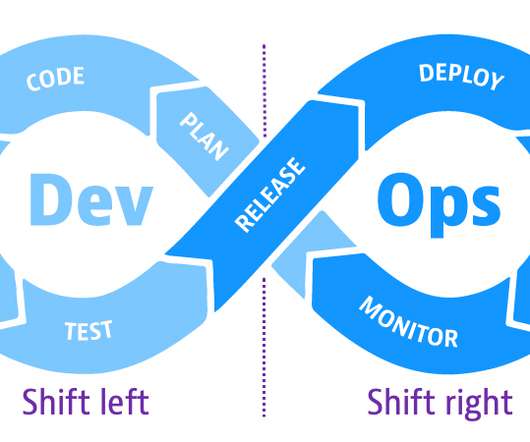
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
The DevOps approach to developing software aims to speed applications into production by releasing small builds frequently as code evolves. As part of the continuous cycle of progressive delivery, DevOps teams are also adopting shift-left and shift-right principles to ensure software quality in these dynamic environments.
Log monitoring, log analysis, and log analytics are more important than ever as organizations adopt more cloud-native technologies, containers, and microservices-based architectures. What is log monitoring? Log monitoring is a process by which developers and administrators continuously observe logs as they’re being recorded.
As the world becomes increasingly interconnected with the proliferation of IoT devices and a surge in applications, digital transactions, and data creation, mobile monitoring — monitoring mobile applications — grows ever more critical.
In DevOps, both monitoring and observability are critical. Because it lets you maintain system reliability, diagnose problems, and enhance performance, effectively and efficiently.
DevOps and site reliability engineering (SRE) teams aim to deliver software faster and with higher quality. What these steps have in common is that monitoring tools are not in sync with new changes in code or topology and this observability data is often siloed within different tools and teams. The role of observability within DevOps.
The widespread use of containers in DevOps allows dev teams to increase their efficiency in application development and enables them to bypass the barrier of different computing environments for their apps. Container monitoring allows you to track all of the metrics and states of your containers.
In May 2022, the Tech Transforms podcast explored the cybersecurity threat landscape, observability, DevOps, and remote work through our conversations with the following top influencers in government technology: Richard Ford – Chief Technology Officer at Praetorian. Dynatrace news. Bob Stevens – AVP Public Sector at GitLab.
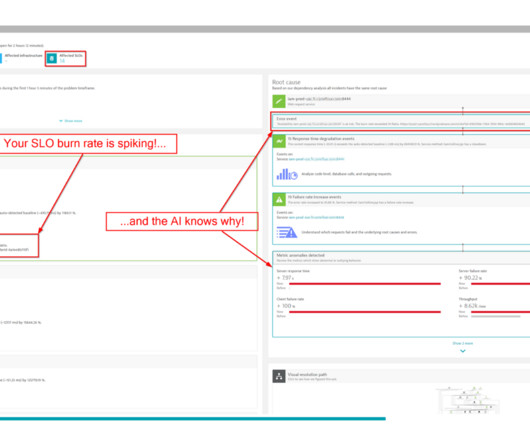
From my experience, a month of monitoring is the optimal duration to gain statistically significant insights into “how my entity behaves with the configured SLO.” Let’s assume we created a service-availability SLO, monitoring the request failure count against the overall request counts. What characterizes a weak SLO?
As a result, API monitoring has become a must for DevOps teams. So what is API monitoring? What is API Monitoring? API monitoring is the process of collecting and analyzing data about the performance of an API in order to identify problems that impact users. The need for API monitoring.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. In a serverless architecture, applications are distributed to meet demand and scale requirements efficiently.
With this integration, Dynatrace customers can now leverage Terraform to manage their monitoring infrastructure as code,” said Asad Ali, Senior Director of Sales Engineering at Dynatrace. What is monitoring as code? What are the benefits of monitoring as code? across their complete Dynatrace instance.”. Step 1: Write.
million per year just “keeping the lights on,” with 63% of CIOs surveyed across five continents calling out complexity as their biggest barrier to controlling costs and improving efficiency. Limited visibility and tool sprawl are just two reasons CIOs are calling for a radically different approach to infrastructure monitoring.
Centralization of platform capabilities improves efficiency of managing complex, multi-cluster infrastructure environments According to research findings from the 2023 State of DevOps Report , “36% of organizations believe that their team would perform better if it was more centralized.” All important health signals are highlighted.
A highly efficient Kubernetes setup generates innumerable new metrics every day, making monitoring cluster health quite challenging. Although there are observability platforms to help you monitor your Kubernetes clusters’ right metrics, knowing exactly which ones to watch will help you stay on top of your monitoring needs.
The DevOps playbook has proven its value for many organizations by improving software development agility, efficiency, and speed. This method known as GitOps would also boost the speed and efficiency of practicing DevOps organizations. Dynatrace also supports monitoring as code and GitOps practices through Monaco.
The Dynatrace CSPM solution significantly enhances security, compliance, and resource efficiency through continuous monitoring, automated remediation, and centralized visibility for enterprises managing complex hybrid and multicloud environments. Automation and continuous monitoring. The solution?
Properly monitoring a Kubernetes cluster or any related environment can be difficult. Service-level objectives (SLOs) are often used to monitor business-critical services and applications for customers. However, they can also be used to monitor optimization processes effectively.
Numerous hurdles can hinder successful deployments, from resource constraints to external dependencies and monitoring inadequacies. Monitoring inadequacies Comprehensive monitoring is essential for detecting and resolving issues during deployment. Ensuring that your monitoring solution monitors your cluster.
SLO monitoring and alerting on SLOs using error-budget burn rates are critical capabilities that can help organizations achieve that goal. SLOs are pivotal for development, DevOps, and SRE teams because they provide a common language for discussing system reliability. What is SLO monitoring?
Comprehensive observability is also essential for digital experience monitoring (DEM). In response, many organizations add more monitoring tools , which adds to cloud complexity and slows down timely responses to issues. DevOps teams can also benefit from full-stack observability. Why full-stack observability matters.
Dynatrace container monitoring supports customers as they collect metrics, traces, logs, and other observability-enabled data to improve the health and performance of containerized applications. It’s helping us build applications more efficiently and faster and get them in front of veterans.” We want to be there in time.”
DevSecOps is a cross-team collaboration framework that integrates security into DevOps processes from the start rather than waiting to address security in a separate silo. How is it different from DevOps, and what’s next for the relationship between development, security, and operations within enterprises?
A DevSecOps approach advances the maturity of DevOps practices by incorporating security considerations into every stage of the process, from development to deployment. DevSecOps best practices provide guidelines to help organizations achieve efficient and secure application design, development, implementation, and management.
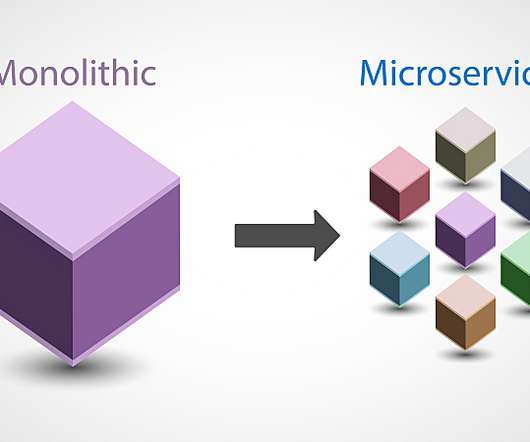
Combined with Agile or DevOps approaches and methodologies, enterprises can accelerate their ability to deliver digital services. Using one executable means there’s only one application you need to set up for logging, monitoring, and testing. Hard on DevOps. Easier to deploy. Monolithic architecture cons. Better testing.
While logging is the act of recording logs, organizations extract actionable insights from these logs with log monitoring, log analytics, and log management. Comparing log monitoring, log analytics, and log management. Log monitoring enables the collection of log data, and log analysis promotes intelligent, data-driven decision making.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content