This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To extend Dynatrace diagnostic visibility into network traffic, we’ve added out-of-the-box DNS request tracking to our infrastructure monitoring capabilities. While our competitors only provide generic traffic monitoring without artificial intelligence, Dynatrace automatically analyzes DNS-related anomalies.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim. The Replay Tester tool samples raw traffic streams from Mantis.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Once set up in development, you can use the same log data points to understand the execution of your application in production.
Welcome to the blog series where we give you a deeper dive into the latest awesomeness around Dynatrace : how we bring scale, zero configuration, automatic AI driven alerting, and root cause analysis to all your custom metrics, including open source observability frameworks like StatsD, Telegraf, and Prometheus.
Anyone who’s concerned with developing, delivering, and operating software knows the importance of making software and the systems it runs on observable. That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Detect and respond to security threats like DDoS attacks or web application attacks by monitoring application traffic and logs.
Container technology is very powerful as small teams can develop and package their application on laptops and then deploy it anywhere into staging or production environments without having to worry about dependencies, configurations, OS, hardware, and so on. Containers can be replicated or deleted on the fly to meet varying end-user traffic.
They help foster confidence and consistency throughout the entire software development lifecycle (SDLC). Automating quality gates is ideal, as it minimizes manually checking and validating key metrics throughout the SDLC. Continuous, informed improvement : Quality gates provide consistent feedback on key metrics.
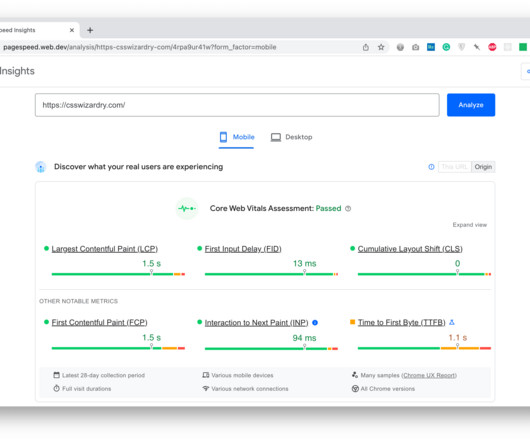
In February 2021, Dynatrace announced full support for Google’s Core Web Vitals metrics , which will help site owners as they start optimizing Core Web Vitals performance for SEO. On the Dynatrace Business Insights team, we have developed analytical views and an approach to help you get started. Dynatrace news. 28-day lookbacks.
This modular microservices-based approach to computing decouples applications from the underlying infrastructure to provide greater flexibility and durability, while enabling developers to build and update these applications faster and with less risk. Why do you need a service mesh?
Consequently, by understanding the intricacies involved, this enables us to swiftly confirm or refute the functional/business case of the business teams involved, including project managers, top management, developers, and tech leads. Path 2 (easier): I’m familiar with my application and the development team.
Each SNMP-enabled device provides access to its state and performance metrics in a simple and robust way that allows Dynatrace to fetch the metrics and run them through Davis®, our AI causation engine. Based on monitored traffic, Dynatrace OneAgent is capable of automatic recognition of topological relations. Events and alerts.
OpenTelemetry for Go provides developers with an observability framework for cloud-native software, allowing them to instrument, generate, collect, and export telemetry data for relevant services. With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control.
These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Identify key performance metrics specific to an organization.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. When organizations implement SLOs, they can improve software development processes and application performance. Develop error budgets to help teams measure success and make data-driven decisions.
Open-source metric sources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an open metric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics. Dynatrace news.
However, performance can decline under high traffic conditions. It also provides an HTTP API for retrieving performance metrics and a command-line tool for advanced management tasks. While Kafka does not include a built-in web interface like RabbitMQ, it provides metrics that integrate with third-party monitoring tools.
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? Enterprises now have access to myriad metrics they can track and measure, but an abundance of choice doesn’t equal actionable insight. The result?
For example, to handle traffic spikes and pay only for what they use. It helps developers and operators identify and troubleshoot issues, optimize performance and improve user experience. Scale automatically based on the demand and traffic patterns. Less visibility into the internal state and behavior of the functions.
As a result, site reliability has emerged as a critical success metric for many organizations. The practice uses continuous monitoring and high levels of automation in close collaboration with agile development teams to ensure applications are highly available and perform without friction. Service-level objectives (SLOs). availability.
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. It also enhances syslog messages with additional context and optimizes network traffic, improving overall system resilience and security.
Fast, consistent application delivery creates a positive user experience that can ultimately drive customer loyalty and improve business metrics like conversion rate and user retention. It is proactive monitoring that simulates traffic with established test variables, including location, browser, network, and device type.
These development and testing practices ensure the performance of critical applications and resources to deliver loyalty-building user experiences. RUM gathers information on a variety of performance metrics. RUM is ideally suited to provide real metrics from real users navigating a site or application.
264/AVC Main profile family still represents a substantial portion of the members viewing hours and an even larger portion of the traffic. These are summarized below: Instead of relying on other objective metrics, such as PSNR†, VMAF is employed to guide optimization decisions. Yet, given its wide support, our H.264/AVC
Rexed, Singh, and Stull outline the importance of metrics, traces, logs, events, and the role they play in achieving full–context Kubernetes observability and driving automated responses in hybrid and multi-cloud environments. To ensure everything runs smoothly, they employ the Dynatrace automated monitoring and observability solution.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. While the first guardian validates the traffic, the second guardian checks the business transactions generated during the observation period.
Streamline development and delivery processes Nowadays, digital transformation strategies are executed by almost every organization across all industries. To achieve this, many organizations are adopting DevOps practices to provide developers with a delivery platform to release their applications and services autonomously and independently.
In the event of an isolated failure we first pre-scale microservices in the healthy regions after which we can shift traffic away from the failing one. In 2013 we first developed our multi-regional availability strategy in response to a catalyst that led us to re-architect the way our service operates.
based sample service in a staging and production namespace, a Jenkins instance and execute some moderate load to “simulate constant production traffic”. Automated Metric Anomaly Detection. From here we also get access to all other pod & process relevant metrics, e.g. memory, threads, … or accessing the container logs.
To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. When a cgroup ID correlates with a container, we emit a percentile timer Atlas metric (runq.latency) for that container. ' They let us identify when a process is ready to run and is waiting for CPU time.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. The ability to scale testing as part of the software development lifecycle (SDLC) has proven difficult. Dynatrace news.
Metrics, logs , and traces make up three vital prongs of modern observability. Event logging and software tracing help application developers and operations teams understand what’s happening throughout their application flow and system. For context, teams collect metrics for further analysis and indexing.
Like general observability , AWS observability is the capacity to measure the current state of your AWS environment based on the data it generates, including its logs, metrics, and traces. EC2 is ideally suited for large workloads with constant traffic. And why it matters. AWS: A service for everything. AWS Lambda. Amazon EKS.
Existing data got updated to be backward compatible without impacting the existing running production traffic. Error Handling Errors are part of software development. But with this framework, it has to be designed more carefully as bulk data reprocessing will be done in parallel with the production traffic.
Log data—the most verbose form of observability data, complementing other standardized signals like metrics and traces—is especially critical. SREs and DevOps engineers need cloud logs in an integrated observability platform to monitor the whole software development lifecycle. Managing this change is difficult.
Organizations have multiple stakeholders and almost always have different teams that set up monitoring, operate systems, and develop new functionality. This greatly reduced the number of metrics to manage and provided a more comprehensive picture of what was behind their primary reliability service-level objective. Saturation.
Introduction Objective Driven Development (ODD) for some Business SLOs. It’s the same concept as Test Driven Development (TDD) where you start with tests that will fail until you finish implementing the code so tests will succeed. Mobile app rating is a good example of Objective Driven Development. App Rating. Availability.
How to mitigate the risk The following versions of OpenSSH are impacted by this vulnerability: Versions earlier than 4.4p1 (unless patched for CVE-2006-5051 and CVE-2008-4109) Versions from 8.5p1 up to, but not including, 9.8p1 OpenBSD systems are unaffected by this, as OpenBSD developed a secure mechanism in 2001 that prevents this vulnerability.
The ultimate goal of each of these reviews is to identify gaps, quantify risk, and develop recommendations for improving the team, processes, and architecture with each of the five pillars. Automatic collection of the entire set of services that publish metrics to Amazon CloudWatch. Common findings.
All Core Web Vitals data used to rank you is taken from actual Chrome-based traffic to your site. The Core Web Vitals Metrics Generally, I approve of the Core Web Vitals metrics themselves ( Largest Contentful Paint , First Input Delay , Cumulative Layout Shift , and the nascent Interaction to Next Paint ).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content