This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This gives fascinating insights into the network topography of our visitors, and how much we might be impacted by high latency regions. Round-trip-time (RTT) is basically a measure of latency—how long did it take to get from one endpoint to another and back again? What is RTT? RTT isn’t a you-thing, it’s a them-thing.
“Latency” is the duration from the execution of a load instruction (to an address that misses in all the caches), and the completion of that load instruction when the data is returned from memory. The example below is for a 2005-era processor with 60 ns memory latency and 6.4 cache lines -> 5.6 cache lines -> 5.6
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
Application observability helps IT teams gain visibility in their highly distributed systems, but what is developer observability and why is it important? In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior software engineer Yarden Laifenfeld explored developer observability. Observability is about answering.”
In the fast-paced digital world, where every millisecond counts, understanding the nuances of network latency becomes paramount for developers and system architects. Latency, the delay before a transfer of data begins following an instruction for its transfer, can significantly impact user experience and system performance.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
Here’s a quick overview of the key advantages: Developer-friendly. Does it affect latency? Yes, you can see an increase in latency. So, if you’re hosting your application in AWS or Azure and move your database to DigitalOcean, you will see an increase in latency. Simple pricing. SSD-based VMs. High performance.
With the rise of microservices architecture , there has been a rapid acceleration in the modernization of legacy platforms, leveraging cloud infrastructure to deliver highly scalable, low-latency, and more responsive services. Why Use Spring WebFlux?
Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs. This limitation has inspired us to develop a foundation model for recommendation. Particularly, these models predominantly extract features from members recent interaction histories on the platform.
DigitalOcean is quickly building its reputation as the developers cloud by providing an affordable, flexible and easy to use cloud platform for developers to work with. Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. Compare Pricing.
DigitalOcean is a cost-effective cloud provider that caters to, and is widely adopted by the developer community. Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. At a glance – TLDR. Compare Throughput.
Firstly, developers struggled to reason about consistency, durability and performance in this complex global deployment across multiple stores. Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns.
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. Were also betting that this will be a time of software development flourishing. The way out?
Continuous Instrumentation of the Linux Scheduler To ensure the reliability of our workloads that depend on low latency responses, we instrumented the run queue latency for each container, which measures the time processes spend in the scheduling queue before being dispatched to the CPU.
When organizations implement SLOs, they can improve software development processes and application performance. Develop error budgets to help teams measure success and make data-driven decisions. Latency is the time that it takes a request to be served. SLOs improve software quality. Define SLOs for each service. Reliability.
However, one metric I feel that front-end developers overlook all too quickly is Time to First Byte (TTFB). The first—and often most surprising for people to learn—thing that I want to draw your attention to is that TTFB counts one whole round trip of latency. can all provide valuable insights. But what else is TTFB?
Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. This significantly increases event latency. Spark Structured Streaming can also provide consistent fault recovery for applications where latency is not a critical requirement.
The service should be able to serve real-time, aka UI, applications so CRUD and search operations should be achieved with low latency. Our service will be used by a lot of internal UI applications hence the latency for CRUD and search operations must be low. Search latency for the generic text queries are in milliseconds.
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.
To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. We developed a Replay Testing tool to verify that idempotent APIs were migrated correctly from the GraphQL Shim to the Video API service. The Falcor API had become a logic-heavy monolith with over a decade of tech debt.
It supports both high throughput services that consume hundreds of thousands of CPUs at a time, and latency-sensitive workloads where humans are waiting for the results of a computation. Local development tools including specialized test runners, code generators, and a command line interface. Modularity?—?An Productivity?—?Local
If you work in software development, SRE, or DevOps, you’ve likely heard the terms observability, telemetry, and tracing. These concepts are crucial for understanding how applications behave in production environments, and they’re an essential part of modern software development practices. What is OpenTelemetry?
They help foster confidence and consistency throughout the entire software development lifecycle (SDLC). The following are specific examples that demonstrate quality gates in action: Security gates Security gates ensure code meets key security requirements defined by development and security stakeholders.
As we are progressing with application development, among various things, there is one primary thing we are less worried about: computing power. Though we are not worried about computing resources, the latency becomes an overhead. A lot of messaging protocols have been developed in the past to address this.
Why observability matters for mobile app performance monitoring Observability data is becoming increasingly important to mobile app performance monitoring because it provides mobile developers with deeper insight into their applications. Load time and network latency metrics. Proactive monitoring. Capacity planning.
As a frontend developer or QA, we want to test our website performance in different network conditions and with different API latencies too. Testing certain components of web applications requires simulating delay in one or more web app components. Here are some scenarios where you would like to delay the network requests.
The goal is to help developers, technical managers, and business owners understand the importance of API performance optimization and how they can improve the speed, scalability, and reliability of their APIs. What Is API Performance Optimization?
History & motivation There were two main motivating use cases that drove Pushy’s initial development and usage. These pain points coincided with the introduction of KeyValue, which was a new offering from the CDE team that is roughly “HashMap as a service” for Netflix developers.
Streamline development and delivery processes Nowadays, digital transformation strategies are executed by almost every organization across all industries. To achieve this, many organizations are adopting DevOps practices to provide developers with a delivery platform to release their applications and services autonomously and independently.
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
These releases often assumed ideal conditions such as zero latency, infinite bandwidth, and no network loss, as highlighted in Peter Deutsch’s eight fallacies of distributed systems. In the screenshot below, a chaos engineering scenario introduced latency and resource stress on the “easytrade” demo application.
While clustering across wide-area networks (WANs) is discouraged due to latency issues, leased links can mitigate some connectivity challenges. Keeping queues short minimizes latency and enhances the overall efficiency of message delivery in RabbitMQ. Keeping queues short maintains a responsive and efficient RabbitMQ setup.
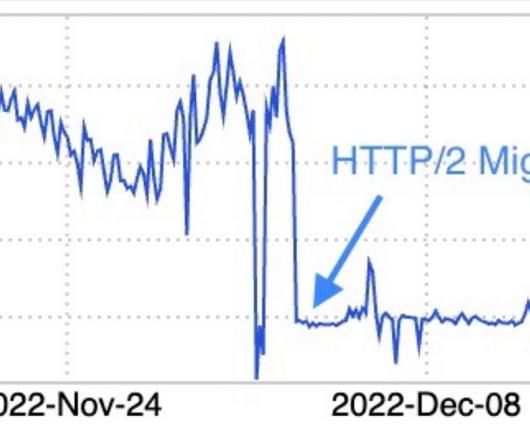
to HTTP2, resulting in a reduction in the number of connections, latency, and garbage collection times. LinkedIn was able to dramatically improve the scalability and performance of its Espresso database by migrating it from HTTP1.1 To achieve these gains, the team had to optimize the Netty’s default HTTP2 stack to make it fit their needs.
This architecture shift greatly reduced the processing latency and increased system resiliency. We expanded pipeline support to serve our studio/content-development use cases, which had different latency and resiliency requirements as compared to the traditional streaming use case.
It’s not uncommon for developers to link to static assets such as libraries or plugins that are hosted at a public/CDN URL. Okay, so not exactly terrifying, but Trainline, a client of mine, found that by reducing latency by 300ms, customers spent an extra £8m a year. What Am I Talking About? All completely avoidable. to just 3.6s.
These include website hosting, database management, backup and restore, IoT capabilities, e-commerce solutions, app development tools and more, with new services released regularly. Lambda’s toolbox of automated processes helps developers streamline to build fast, robust, and scalable applications on accelerated timelines.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. ScaleGrid also maintains 53% lower latency on average throughout the entire MySQL AWS performance tests.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
95th Percentile Latency. The 95th percentile latency of queries was also 1.8 Workload Throughput (Queries Per Second). Index Creation on Master. Rolling Index Creation. times higher when the index creation happened on the master server.
Today we are excited to announce latency heatmaps and improved container support for our on-host monitoring solution?—?Vector?—?to Remotely view real-time process scheduler latency and tcp throughput with Vector and eBPF What is Vector? to the broader community. Vector is open source and in use by multiple companies.
To ensure high standards, it’s essential that your organization establish automated validations in an early phase of the software development process—ideally when code is written. In this case, the four golden signals (latency, traffic, errors, and saturation) are derived from span attributes and DQL metric queries via Dynatrace Grail™.
Organizations have multiple stakeholders and almost always have different teams that set up monitoring, operate systems, and develop new functionality. In their new dashboard, they added dimensions for load, latency, and open problems for each component. The “Four Golden Signals” include the following: Latency.
As a discipline, SRE focuses on improving software system reliability across key categories including availability, performance, latency, efficiency, capacity, and incident response. SRE applies DevOps principles to developing systems and software that help increase site reliability and performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content