This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time. Even if infrastructuremetrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. DevSecOps and SRE : Observability is not just the result of implementing advanced tools, but a foundational property of an application and its supporting infrastructure.
Membership in MISA is nomination-only and reserved for independent software vendors who develop security solutions that effectively integrate with MISA-qualifying Microsoft Security products. That’s why we’re proud to announce that Dynatrace has joined the Microsoft Intelligent Security Association (MISA).
Veeramachaneni discusses how OTel is standardizing telemetry data and inspiring new open-source data collectors and workflows that bridge the gap between application and infrastructure monitoring. A: It’s given developers and platform teams much greater ownership of their data.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Infrastructure complexity is costing enterprises money. AIOps offers an alternative to traditional infrastructure monitoring and management with end-to-end visibility and observability into IT stacks. As 69% of CIOs surveyed said, it’s time for a “radically different approach” to infrastructure monitoring.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Many organizations respond by adding a proliferation of infrastructure monitoring tools, which in many cases, just adds to the noise. Dynatrace news.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
One of the promises of container orchestration platforms is to make i t easier for the developers to accelerate the deployment of their app lication s without having to worry about scalability and infrastructure dependencies. This enforces the resource utilization policies, protecting the cluster, and workloads.
While many companies now enlist public cloud services such as Amazon Web Services, Google Public Cloud, or Microsoft Azure to achieve their business goals, a majority also use hybrid cloud infrastructure to accommodate traditional applications that can’t be easily migrated to public clouds. How to modernize for hybrid cloud.
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. It’s about uncovering insights that move business forward. The result?
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
Now let’s look at how we designed the tracing infrastructure that powers Edgar. This insight led us to build Edgar: a distributed tracing infrastructure and user experience. Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage.
Improving collaboration across teams By surfacing actionable insights and centralized monitoring data, Dynatrace fosters collaboration between development, operations, security, and business teams. Inefficient or resource-intensive runners can lead to increased costs and underutilized infrastructure.
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Average query response time. What’s next.
Now, Dynatrace has the ability to turn numerical values from logs into metrics, which unlocks AI-powered answers, context, and automation for your apps and infrastructure, at scale. Once set up in development, you can use the same log data points to understand the execution of your application in production. Duration: 163.41
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The goal is to abstract away the underlying infrastructure’s complexities while providing a streamlined and standardized environment for development teams.
As a result, organizations need to monitor mobile app performance metrics that are meaningful and actionable by gaining adequate observability of mobile app performance. There are many common mobile app performance metrics that are used to measure key performance indicators (KPIs) related to user experience and satisfaction.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This leads to frustrating bottlenecks for developers attempting to build and deliver software.
But are observability platforms—born from the collision between the demands of cloud computing and the limitations of APM and infrastructure monitoring—the best solution for managing business analytics? Metric extraction is a convenient way to create your business metrics, delivering fast, flexible, and cost-effective analytics.
For organizations running their own on-premises infrastructure, these costs can be prohibitive. Cloud service providers, such as Amazon Web Services (AWS) , can offer infrastructure with five-nines availability by deploying in multiple availability zones and replicating data between regions. What is always-on infrastructure?
How to achieve sustainable IT practices Use observability tools The first step in driving improvements is to obtain a comprehensive view of your IT infrastructure’s climate impact. Collect metrics on energy consumption or derive them from existing signals.
Effective application development requires speed and specificity. Applications must work as intended and make their way through development pipelines as quickly as possible. FaaS enables enterprises to deliver on the evolving expectations of fast and furious app development. But what is FaaS? How does function as a service work?
By gaining insights into how your Kubernetes workloads utilize computing and memory resources, you can make informed decisions about how to size and plan your infrastructure, leading to reduced costs. Proper Kubernetes monitoring includes utilizing observability information to optimize your environment.
Observability Vs. Monitoring: Why A Developer Needs Both. Given the complexity of distributing the evolving cloud-based services and infrastructures across a diverse range of users, IT service providers consistently observe and monitor metrics, datasets, and logs.
OpenTelemetry provides a common set of tools, APIs, and SDKs to help collect observability signals from applications and infrastructure endpoints. The Astronomy Shop demo application , which has been actively developed since 2022, solves this problem, and Dynatrace is one of its leading contributors. metrics from span data.
There’s no lack of metrics, logs, traces, or events when monitoring your Kubernetes (K8s) workloads. But there is a lack of time for DevOps , SRE , and developers to analyze all this data to identify whether there’s a user impacting problem and if so – what the root cause is to fix it fast. Dynatrace news.
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
Application observability helps IT teams gain visibility in their highly distributed systems, but what is developer observability and why is it important? In a recent webinar , Dynatrace DevOps activist Andi Grabner and senior software engineer Yarden Laifenfeld explored developer observability. Observability is about answering.”
Loosely defined, observability is the ability to understand what’s happening inside a system from the knowledge of the external data it produces, which are usually logs, metrics, and traces. Capturing data is critical to understanding how your applications and infrastructure are performing at any given time.
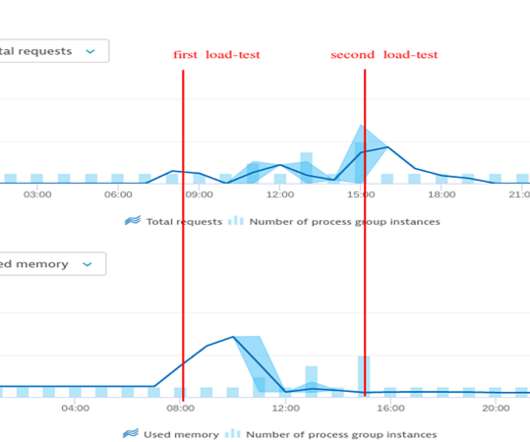
Dynatrace enables our customers to monitor and optimize their cloud infrastructure and applications through the Dynatrace Software Intelligence Platform. Today’s story is about how the Keptn development team is using Dynatrace during development and load-testing. Conclusion: Dynatrace is always on for us developers.
At the 2024 Dynatrace Perform conference in Las Vegas, Michael Winkler, senior principal product management at Dynatrace, ran a technical session exploring just some of the many ways in which Dynatrace helps to automate the processes around development, releases, and operation. Real-time detection for fast remediation.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
In this episode, Willie addresses the issue of discoverability and the impact of the Binding Operative Directive (BOD) released by the Cybersecurity & Infrastructure Security Agency (CISA) on the federal community. Listen in to learn about the innovative steps that the USPTO has taken to develop new ways of working.
The concept of observability involves understanding a system’s internal states through the examination of logs, metrics, and traces. One well-known example is PhonePe, which experienced a 2000% growth in its data infrastructure and a 65% reduction in data management costs with the implementation of a data observability solution.
Organizations are increasingly embracing cloud- and AI-native strategies, requiring a more automated and intelligent approach to their observability and development practices. The Infrastructure & Operations app provides an up-to-date and comprehensive view of monitored environments on Google Cloud.
Anyone who’s concerned with developing, delivering, and operating software knows the importance of making software and the systems it runs on observable. That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
By analyzing benchmark results, organizations can determine which system aligns best with their infrastructure needswhether its high-speed event processing or reliable message queuing for microservices. The choice between these authentication methods depends on an organizations security infrastructure.
Kubernetes simplifies the operation and development of distributed applications by streamlining the deployment of containerized workloads and distributing them over a set of nodes. But there are other related components and processes (for example, cloud provider infrastructure) that can cause problems in applications running on Kubernetes.
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. Platform engineering best practices for delivering a highly available, secure, and resilient Internal Development Platform: Centralize and standardize.
Endpoints include on-premises servers, Kubernetes infrastructure, cloud-hosted infrastructure and services, and open-source technologies. Observability across the full technology stack gives teams comprehensive, real-time insight into the behavior, performance, and health of applications and their underlying infrastructure.
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. The Flow Exporter also publishes various operational metrics to Atlas.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content