This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A good Kubernetes SLO strategy helps teams manage and make containerized workloads more efficient. Efficient coordination of resource usage, requests, and allocation is critical. As every container has defined requests for CPU and memory, these indicators are well-suited for efficiency monitoring.
I realized that our platforms unique ability to contextualize security events, metrics, logs, traces, and user behavior could revolutionize the security domain by converging observability and security. Collect observability and security data user behavior, metrics, events, logs, traces (UMELT) once, store it together and analyze in context.
Membership in MISA is nomination-only and reserved for independent software vendors who develop security solutions that effectively integrate with MISA-qualifying Microsoft Security products. That’s why we’re proud to announce that Dynatrace has joined the Microsoft Intelligent Security Association (MISA).
Second, it enables efficient and effective correlation and comparison of data between various sources. Semconv for HTTP Spans quite possibly the most important signal have been declared stable, and HTTP Metrics will hopefully soon follow. At the same time, having aligned telemetry data is crucial for adopting OpenTelemetry at scale.
DORA ( DevOps Research and Assessment ) metrics, developed by the DORA team have become a standard for measuring the efficiency and effectiveness of DevOps implementations. What Are DORA Metrics? These metrics are:
The Dynatrace platform automatically captures and maps metrics, logs, traces, events, user experience data, and security signals into a single datastore, performing contextual analytics through a “power of three AI”—combining causal, predictive, and generative AI. It’s about uncovering insights that move business forward. The result?
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams. What is observability?
You can now: Kickstart your creation journey using ready-made dashboards Accelerate your data exploration with seamless integration between apps Start from scratch with the new Explore interface Search for known metrics from anywhere Let’s look at each of these paths through an end-to-end use case focused on Kubernetes monitoring.
They now use modern observability to monitor expanding cloud environments in order to operate more efficiently, innovate faster and more securely, and to deliver consistently better business results. Further, automation has become a core strategy as organizations migrate to and operate in the cloud.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
The release candidate of OpenTelemetry metrics was announced earlier this year at Kubecon in Valencia, Spain. Since then, organizations have embraced OTLP as an all-in-one protocol for observability signals, including metrics, traces, and logs, which will also gain Dynatrace support in early 2023.
This software makes the different tasks easier and allows for increased efficiency and performance. Development of any software is a tedious and long process, and it undergoes a series of quality and performance tests before its release and use. With the development in technology, the software gets upgraded with the latest updates.
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. If you don’t have one, you can use a trial account.
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
My goal was to provide IT teams with insights to optimize customer experience by collaborating with business teams, using both business KPIs and IT metrics. The Dynatrace platform’s granular insights also empower development teams to innovate more effectively so they can deliver faster change, helping executives improve customer experience.
"Employing these Metrics to excel the performance of code directly impacts the profitability of the business. For the developers, practicing to write a good quality code in the initial phase of the coding job not only prevents the efforts and hours spent in précising the errors but also the costs are reduced.
This demand for rapid innovation is propelling organizations to adopt agile methodologies and DevOps principles to deliver software more efficiently and securely. The DevOps approach breaks up projects into modular components that development teams build in parallel by working closely with operations and business stakeholders.
Improving collaboration across teams By surfacing actionable insights and centralized monitoring data, Dynatrace fosters collaboration between development, operations, security, and business teams. This data covers all aspects of CI/CD activity, from workflow executions to runner performance and cost metrics.
Consequently, by understanding the intricacies involved, this enables us to swiftly confirm or refute the functional/business case of the business teams involved, including project managers, top management, developers, and tech leads. Path 2 (easier): I’m familiar with my application and the development team.
Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you. For our example dashboard, we’ll only focus on some selected key infrastructure metrics. Click on Select metric. Change it now to sum.
UK Home Office: Metrics meets service The UK Home Office is the lead government department for many essential, large-scale programs. From development tools to collaboration, alerting, and monitoring tools, Dimitris explains how he manages to create a successful—and cost-efficient—environment.
This allows teams to sidestep much of the cost and time associated with managing hardware, platforms, and operating systems on-premises, while also gaining the flexibility to scale rapidly and efficiently. In a serverless architecture, applications are distributed to meet demand and scale requirements efficiently. Pay Per Use.
As organizations look to expand DevOps maturity, improve operational efficiency, and increase developer velocity, they are embracing platform engineering as a key driver. The goal is to abstract away the underlying infrastructure’s complexities while providing a streamlined and standardized environment for development teams.
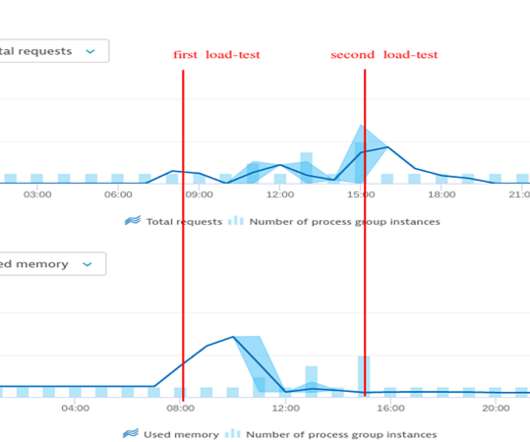
Today’s story is about how the Keptn development team is using Dynatrace during development and load-testing. We were in the process of developing a new feature and wanted to make sure it could handle the expected load behavior. Conclusion: Dynatrace is always on for us developers. It happened in June 2020.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
As the application owner of an e-commerce application, for example, you can enrich the source code of your application with domain-specific knowledge by adding actionable semantics to collected performance or business metrics. New OpenTelemetry metrics exporters provide the broadest language support on the market.
At the 2024 Dynatrace Perform conference in Las Vegas, Michael Winkler, senior principal product management at Dynatrace, ran a technical session exploring just some of the many ways in which Dynatrace helps to automate the processes around development, releases, and operation. Real-time detection for fast remediation.
Until recently, improvements in data center power efficiency compensated almost entirely for the increasing demand for computing resources. Collect metrics on energy consumption or derive them from existing signals. However, this trend is now reversing. For instance, optimizing a frontend library can save resources for every website.
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
This guide will cover how to distribute workloads across multiple nodes, set up efficient clustering, and implement robust load-balancing techniques. This leadership ensures that messages are managed efficiently, providing the fastest fail-over among replicated queue types.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
2020 cemented the reality that modern software development practices require rapid, scalable delivery in response to unpredictable conditions. This method of structuring, developing, and operating complex, multi-function software as a collection of smaller independent services is known as microservice architecture. Dynatrace news.
The primary goals of these campaigns are to encourage more people to install and play the games, making incremental installs and engagement crucial metrics for evaluating their effectiveness. To facilitate easier access to incrementality results, we have developed an interactive tool powered by this framework.
If you work in software development, SRE, or DevOps, you’ve likely heard the terms observability, telemetry, and tracing. These concepts are crucial for understanding how applications behave in production environments, and they’re an essential part of modern software development practices. What is OpenTelemetry?
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. Were also betting that this will be a time of software development flourishing. The way out?
These developments open up new use cases, allowing Dynatrace customers to harness even more data for comprehensive AI-driven insights, faster troubleshooting, and improved operational efficiency. Customers have had a positive response to our native syslog implementation, noting its easy setup and efficiency.
Efficient coordination among resource usage, requests, and allocation is critical. One perspective focuses on the potential for optimization at the interface between the team responsible for managing the Kubernetes cluster and the teams responsible for developing and deploying applications.
The development of internal platform teams has taken off in the last three years, primarily in response to the challenges inherent in scaling modern, containerized IT infrastructures. The old saying in the software development community, “You build it, you run it,” no longer works as a scalable approach in the modern cloud-native world.
Today, IT services have a direct impact on almost every key business performance indicator, from revenue and conversions to customer satisfaction and operational efficiency. Often, these metrics are unable to even identify trends from past to present, never mind helping teams to predict future trends. Agility and innovation.
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
AI innovation elevates efficiency and performance of Google Cloud AI adoption is increasingly critical for any organization. Get insights into Google BigQuery service metrics – Hub article This Dynatrace extension leverages data collected from the Google Operations API to constantly monitor health and performance of Google BigQuery services.
Theyre often categorized by their function; core processes directly create customer value, support processes increase departmental efficiency, and management processes drive strategic goals and compliance. To summarize, business process observability: Treats the process as a business asset or entity with unique discernable flows.
Continuous instrumentation is critical to catching such matters as they emerge, and eBPF, with its hooks into the Linux scheduler with minimal overhead, enabled us to monitor run queue latency efficiently. To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch.
Rather, they must be bolstered by additional technological investments to ensure reliability, security, and efficiency. It goes beyond traditional monitoring—metrics, logs, and traces—to encompass topology mapping, code-level details, and user experience metrics that provide real-time insights.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content