This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. The streaming data store makes the system extensible to support other use-cases (e.g. System Components. Component Design. API Design. Problem Statement.
Because of the emergence of cloud services, a broad range of storage choices are now easily available to fulfill the different demands of both organizations and people. These storage alternatives have been designed to meet a range of requirements, including performance, scalability, durability, and price.
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
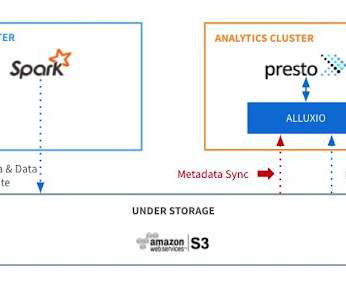
Metadata synchronization (sync) is a core feature in Alluxio that keeps files and directories consistent with their source of truth in under-storagesystems, thus making it simple for users to reason the data retrieved from Alluxio. This article describes the design and the implementation in Alluxio to keep metadata synchronized.
At this scale, we can gain a significant amount of performance and cost benefits by optimizing the storage layout (records, objects, partitions) as the data lands into our warehouse. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
A distributed storagesystem is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
Creating an ecosystem that facilitates data security and data privacy by design can be difficult, but it’s critical to securing information. When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration.
In this article, Rogerio Robetti discusses the challenges in auto-scaling stateful storagesystems and proposes an opinionated design solution to automatically scale up (vertical) and scale out (horizontal) from a single node up to several nodes in a cluster with minimum configuration and interference of the operator.
It’s architecture was specially designed to manage large-scale data warehouses and business intelligence workloads by giving you the ability to spread your data out across a multitude of servers. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. Greenplum Architectural Design.
This means you no longer have to provision, scale, and maintain servers to run your applications, databases, and storagesystems. Instead of worrying about infrastructure management functions, such as capacity provisioning and hardware maintenance, teams can focus on application design, deployment, and delivery. Reliability.
In fact, observability is essential for shaping how we design smarter, more resilient systems for the future. As an open-source project, OpenTelemetry sets standards for telemetry data sets and works with a wide range of systems and platforms to collect and export telemetry data to backend systems. milestone.
A horizontally scalable exabyte-scale blob storagesystem which operates out of multiple regions, Magic Pocket is used to store all of Dropbox’s data. Adopting SMR technology and erasure codes, the system has extremely high durability guarantees but is cheaper than operating in the cloud. By Facundo Agriel
In this post, we dive deep into how Netflix’s KV abstraction works, the architectural principles guiding its design, the challenges we faced in scaling diverse use cases, and the technical innovations that have allowed us to achieve the performance and reliability required by Netflix’s global operations.
Objectives Modern AI innovations require proper infrastructure, especially concerning data throughput and storage capabilities. While GPUs drive faster results, legacy storage solutions often lag behind, causing inefficient resource utilization and extended times in completing the project.
Lastly, the packager kicks in, adding a system layer to the asset, making it ready to be consumed by the clients. From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step.
Building resilient systems requires comprehensive error management. Errors could occur in any part of the system / or its ecosystem and there are different ways of handling these e.g. Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc.
Media Feature Storage: Amber Storage Media feature computation tends to be expensive and time-consuming. This feature store is equipped with a data replication system that enables copying data to different storage solutions depending on the required access patterns.
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. This paper describes the design decisions behind the Snowflake cloud-based data warehouse. have altered the many assumptions that guided the design and optimization of the Snowflake system. From shared-nothing to disaggregation.
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.
Back then, Amazon was ~2% of its size today, and was growing faster than traditional IT systems could support. We had to rethink everything previously known about building scalable systems. Storage was one of our biggest pain points, and the traditional systems we used just weren’t fitting the needs of the Amazon.com retail business.
Building on these foundational abstractions, we developed the TimeSeries Abstraction — a versatile and scalable solution designed to efficiently store and query large volumes of temporal event data with low millisecond latencies, all in a cost-effective manner across various use cases.
Kubernetes was initially designed with a strong focus on stateless workloads, meaning these workloads do not need to store any persistent data. You quickly realize that it will take ages to fill up the overprovisioned database storage. Two days later, your database runs out of storage in the middle of the night. Dynatrace news.
We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. This limited pilot system greatly reduced the time spent by our users to manually analyze the content. Dawn Chenette , Design Lead This approach had several benefits for product engineering.
Often times an external system is providing data as JSON, so it might be a temporary store before data is ingested into other parts of the system. JSONB storage has some drawbacks vs. traditional columns: PostreSQL does not store column statistics for JSONB columns. JSONB storage results in a larger storage footprint.
An AI observability strategy—which monitors IT system performance and costs—may help organizations achieve that balance. AI requires more compute and storage. Training AI data is resource-intensive and costly, again, because of increased computational and storage requirements. AI performs frequent data transfers.
Teams can then act before attackers have the chance to compromise key data or bring down critical systems. This data helps teams see where attacks began, which systems were targeted, and what techniques attackers used. Proactive protection, however, focuses on finding evidence of attacks before they compromise key systems.
A data lakehouse addresses these limitations and introduces an entirely new architectural design. This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storagesystems (which are used by data lakes). Grail is built for such analytics, not storage.
The core technologies underpinning the major relational database management systems of today were developed in the 1980–1990s. This is not to say that a system administrator necessarily enjoys dealing with relational databases. It's a task that requires the undivided attention of dedicated system and database administrators.
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
Five years ago when Google published The Datacenter as a Computer: Designing Warehouse-Scale Machines it was a manifesto declaring the world of computing had changed forever. The world is still changing, so Google published a new edition: The Datacenter as a Computer: Designing Warehouse-Scale Machines, Third Edition.
Organizations need to unify all this observability, business, and security data based on context and generate real-time insights to inform actions taken by automation systems, as well as business, development, operations, and security teams. Systems automatically generate logs, which record events that took place. Event severity.
Simpler UI Testing with CasperJS ( Architects Zone – Architectural Design Patterns & Best Practices). Using MongoDB as a cache store ( Architects Zone – Architectural Design Patterns & Best Practices). Linux System Mining with Python ( Javalobby – The heart of the Java developer community). Hacker News).
which is difficult when troubleshooting distributed systems. Now let’s look at how we designed the tracing infrastructure that powers Edgar. Troubleshooting a session in Edgar When we started building Edgar four years ago, there were very few open-source distributed tracing systems that satisfied our needs.
The core technologies underpinning the major relational database management systems of today were developed in the 1980–1990s. This is not to say that a system administrator necessarily enjoys dealing with relational databases. It's a task that requires the undivided attention of dedicated system and database administrators.
Note that most of the changes we’ve introduced so far and those that are detailed below are all designed to be invisible to you, taking place entirely automatically in the background. However these improvements are of critical importance for those who have been exposed to the problems that these improvements are designed to solve.
There’s a goldmine of business data traversing your IT systems, yet most of it remains untapped. Business events: Delivering the best data It’s been two years since we introduced business events , a special class of events designed to support even the most demanding business use cases. Easy to access.
The issue is that Anna is now orders of magnitude more efficient than competing systems, in addition to being orders of magnitude faster. The core component in Anna v11 is a monitoring system & policy engine that together enable workload-responsiveness and adaptability.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. Traces help find the flow of a request through a distributed system. Logs represent event data in plain-text, structured or binary format.
Infrastructure as a service (IaaS) handles compute, storage, and network resources. Because a third party manages part of the infrastructure, IT teams give up a measure of control over system architecture. Consider a monolithic application, for example, designed to perform a host of functions. But how does FaaS fit in?
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storagesystems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host.
Moreover, the system lacks flexibility, imposing strict schemas that administrators and developers must adhere to avoid additional costs. Dynatrace has developed the purpose-built data lakehouse, Grail , eliminating the need for separate management of indexes and storage. The majority of costs are associated with data querying.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. Thermal design power (TDP) values are derived from AMD and Intel to calculate CPU power consumption.
Having a distributed and scalable graph database system is highly sought after in many enterprise scenarios. Do Not Be Misled Designing and implementing a scalable graph database system has never been a trivial task.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content