

Dynatrace elevates data security with separated storage and unique encryption keys for each tenant
Dynatrace
NOVEMBER 29, 2024
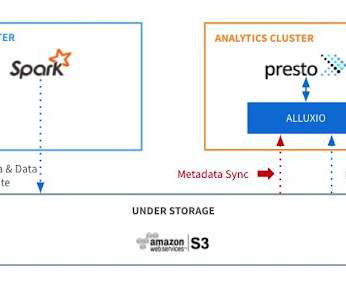
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.














































Let's personalize your content