This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This example shows that the checkout function running in the EU-Central-1 region processes between 20 and 80 invocations per minute. This additional insight enables you to design strategies for handling the effects of cold starts, like warming up your functions or configuring provisioned concurrency for your functions. and Python.
Protect data in multi-tenant architectures To bring you the most value by unifying observability and security in one analytics and automation platform powered by AI, Dynatrace SaaS leverages a multitenancy architecture, enabling efficient and scalable data ingestion, querying, and processing on shared infrastructure.
Dynatrace has announced that it has successfully achieved the Google Cloud Ready – Cloud SQL designation for Cloud SQL, Google Cloud’s fully-managed, relational database service for MySQL, PostgreSQL, and SQL Server. This designation can also save time in evaluating Dynatrace solutions for organizations that are not already using them.
Creating an ecosystem that facilitates data security and data privacy by design can be difficult, but it’s critical to securing information. When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing.
It is not the end of programming. It is the end of programming as we know it today. Assembly language programming then put an end to that. Betty Jean Jennings and Frances Bilas (right) program the ENIAC in 1946. There were more programmers, not fewer This was far from the end of programming, though. I dont buy it.
Building services that adhere to software best practices, such as Object-Oriented Programming (OOP), the SOLID principles, and modularization, is crucial to have success at this stage. As a result, requests are uniformly handled, and responses are processed cohesively. The request schema for the observability endpoint.
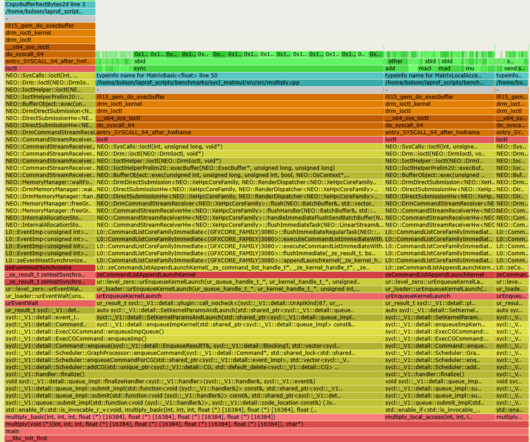
The green frames are the actual instructions running on the AI or GPU accelerator, aqua shows the source code for these functions, and red (C), yellow (C++), and orange (kernel) show the CPU code paths that initiated these AI/GPU programs. It's designed to be easy and low-overhead , just like a CPU profiler.
5 FedRAMP (Federal Risk and Authorization Management Program) is a government program that provides a standardized approach to security assessment, authorization, and continuous monitoring for cloud products and services for U.S. They help organizations understand risks, improve processes, and boost security readiness.
This post is a brief commentary on Martin Fowler’s post, An Example of LLM Prompting for Programming. There’s a lot of excitement about how the GPT models and their successors will change programming. It describes the architecture, goals, and design guidelines; it also tells ChatGPT explicitly not to generate any code.
As we enter a new decade, we asked programming experts?—including Although many Android developers are still in the process of making the move to Kotlin, those who have already transitioned know the benefits it offers. including several of our own O’Reilly authors and instructors?—for
When tools like GitHub Copilot first appeared, it was received wisdom that AI would make programming easier. It would be a boon to new programmers at the start of their careers, just learning a few new programming languages. As we grow into AI, were growing beyond this makes programming easier. But theyre not here yet.
the Data Privacy Framework (DPF) is designed to serve as an adequate data transfer mechanism under the GDPR. Data Privacy Framework Program (The EU-U.S. As a Dynatrace customer, you trust Dynatrace with ingesting and processing terabytes of data. DPF, UK Extension to the EU-U.S. DPF, and Swiss-U.S.
While last year was deemed “The Year of Innovation” for launching Grail , our causal data lakehouse with massively parallel processing (MPP), along with AppEngine , AutomationEngine , Notebooks , and more, 2023 is about extending these innovations to more customers through our partners.
Synthetic testing is an IT process that uses software to discover and diagnose performance issues with user journeys by simulating real-user activity. For example, teams can program synthetic test tools to send large volumes of simultaneous resource requests to a new application and evaluate how well it responds.
For example, each deliverable in the project, like the requirements, design, code, documents, user interface, etc., At this level, we are testing the code as a black box to ensure that all services expected from the program exist, work as expected, and with no problem. should be tested.
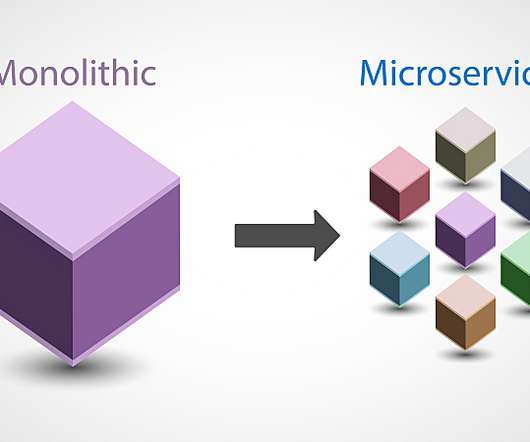
Then, they can split these services into functional application programming interfaces (APIs), rather than shipping applications as one large, collective unit. These teams typically use standardized tools and follow a sequential process to build, review, test, deliver, and deploy code. Common problems with monolithic architecture.
We look here at a Gedankenexperiment: move 16 bytes per cycle , addressing not just the CPU movement, but also the surrounding system design. A lesser design cannot possibly move 16 bytes per cycle. This base design can map easily onto many current chips. Thought Experiment. bytes remaining to move. Cache Pollution.
DORA seeks to strengthen the cybersecurity resilience of the EU’s banking and financial institutions by requiring them to possess the requisite processes, systems, and controls to prevent, manage, and recover from cybersecurity incidents. Who needs to be DORA compliant?
It’s also critical to have a strategy in place to address these outages, including both documented remediation processes and an observability platform to help you proactively identify and resolve issues to minimize customer and business impact. This often occurs during major events, promotions, or unexpected surges in usage.
Security analytics solutions are designed to handle modern applications that rely on dynamic code and microservices. Potential visibility Security analytics helps organizations gain a holistic view of their IT environments, including application programming interfaces and legacy solutions.
During this webinar, Mr. Puckett and Steve Mazzuca, Director DoD Programs at Dynatrace, discussed Mr. Puckett’s role in this large-scale, multi-cloud transformation. Mr. Puckett identified three ECMA programs that provide an advantage for the warfighter: Managing the mission in the cloud. Software factories. Multi-cloud adoption.
And it is not a secret that Apache Kafka is becoming more widespread as a component to be selected for complex programming solutions. Apache Kafka is a distributed data store optimized for ingesting and processing streaming data in real-time. Kafka provides three main functions:
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
The inspiration (and title) for it comes from Mike Loukides’ Radar article on Real World Programming with ChatGPT , which shares a similar spirit of digging into the potential and limits of AI tools for more realistic end-to-end programming tasks. Setting the Stage: Who Am I and What Am I Trying to Build?
Apache Spark is an open-source distributed computing system designed for large-scale data processing. Spark provides a unified framework for processing and analyzing large datasets across distributed computing clusters. What Is Apache Spark?
As developers move to microservice-centric designs, components are broken into independent services to be developed, deployed, and maintained separately. IDC predicted, by 2022, 90% of all applications will feature microservices architectures that improve the ability to design, debug, update, and use third-party code.
Ten Tips For The Aspiring Designer Beginners (Part 1). Ten Tips For The Aspiring Designer Beginners (Part 1). In this article, I want to share ten tips that helped me grow and become a better designer, and I hope these tips will also help you while you’re trying to find more solid ground under your feet. Luis Ouriach.
By Jose Fernandez Today, we are thrilled to announce the release of bpftop , a command-line tool designed to streamline the performance optimization and monitoring of eBPF applications. Introducing bpftop bpftop provides a dynamic real-time view of running eBPF programs.
Program staff depend on the reliable functioning of critical program systems and infrastructure to provide the best service delivery to the communities and citizens HHS serves, from newborn infants to persons requiring health services to our oldest citizens.
Bainbridge believed that automation designers were in denial about this, however. As she saw it, designers approached the problem of automation as if the human factor were not , in fact, a factor. This is precisely the kind of problem that robotic process automation (RPA) aims to address. RPA explained.
The logic isnt in the patterns but in knowing how to assemble the patterns to solve problemsand the process of assembling patterns has to be the focus of training, looking at millions of examples of logical reasoning to model the way patterns are assembled into wholes. Could training models specifically on design patterns be a breakthrough?
Rachel Kelley (AWS), Ranjit Raju (AWS) Rendering is core to the the VFX process VFX studios around the world create amazing imagery for Netflix productions. This program is just one example of the many ways Netflix strives to entertain the world. By: Peter Cioni (Netflix), Alex Schworer (Netflix), Mac Moore (Conductor Tech.),
When I was growing up, I developed a strong interest in the space program. I would eventually enroll in the combined BS/MS program, committing to aerospace long-term and to participating in undergraduate and graduate research. Structures, dynamics, control systems, fluids, design…pass, pass, pass, pass, and pass!
Think of Smartscape as the visualization of ‘Observability’ across Applications, Services, Processes, Hosts, and Datacenters. As I described how the Smartscape shows the relationships of host machines, processes, services, end users and their respective datacenter or enclaves, I saw them perk up. Showing a list of key processes.
Automation testing tools are designed to execute automated test scripts to validate software requirements, both functional and non-functional. It supports various programming languages, including Java, Python, and C#, making it a versatile option for web applications.
In this Sentry programming session, we looked at using our error monitoring platform to help debug one of our own native products: Symbolicator. This service is responsible for processing native crash reports. Yet, there are quite a few reasons why a Rust program can still crash, including: Crashing Rust.
The open-source scripting language PHP is used by over 78% of all websites that use a server-side programming language. Many application security products were designed before the rise of DevSecOps, containers, Kubernetes, and multicloud environments and so can’t keep up with rapid changes in these environments. Dynatrace news.
Development Process. Development Process. This method of modularization allows for efficient program development and easy debugging and modification in our application. In a traditional app where we have signup, logins, or product page we want to have consistent behavior and design. UI kit built upon material design.
Major cloud providers such as AWS offer certification programs to help technology professionals develop and mature their cloud skills. The list of AWS certifications below shows there are two main AWS certification types: Core and Specialty, six classified as Core AWS Certifications, and five designated as Specialty AWS Certifications.
For this, best practices would be to segregate commands from data, use parameterized SQL queries, and eliminate the interpreter by using a safe application program interface, if possible. Use a safe development life cycle with secure design patterns and components. Apply threat modeling and plausibility checks.
It was clearly far better hardware than we could build, had a proper full featured operating system on it, and as soon as it shipped, people figured out how to jailbreak it and program it. As the iPad delivery day in May approached, I engaged again to help Stephane Odul run the app through Apples App Store submission processes.
“As code” means simplifying complex and time-consuming tasks by automating some, or all, of their processes. As a result, IT teams often end up performing time-consuming, manual processes. This approach to IAC uses object-oriented programming languages, such as Java or C++.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content