This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In fact, observability is essential for shaping how we design smarter, more resilient systems for the future. As an open-source project, OpenTelemetry sets standards for telemetry data sets and works with a wide range of systems and platforms to collect and export telemetry data to backend systems.
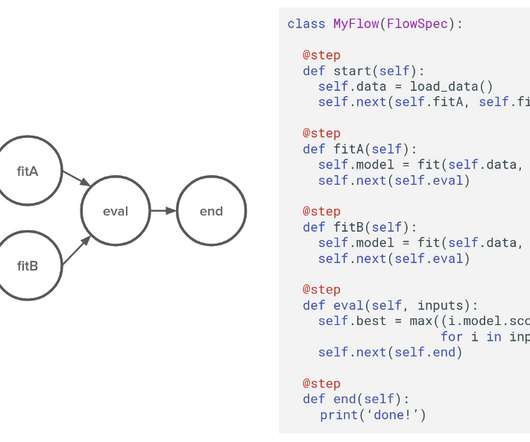
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! By design, Metaflow is a deceptively simple Python library: Data scientists can structure their workflow as a Directed Acyclic Graph of steps, as depicted above. both for compute and storage.
Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment. Greenplum Architectural Design. OpenSource.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. What is RabbitMQ? What is Apache Kafka?
by David Berg , Ravi Kiran Chirravuri , Romain Cledat , Savin Goyal , Ferras Hamad , Ville Tuulos tl;dr Metaflow is now open-source! By design, Metaflow is a deceptively simple Python library: Data scientists can structure their workflow as a Directed Acyclic Graph of steps, as depicted above. both for compute and storage.
Data storage and distribution through HollowFeeds Netflix Hollow is an OpenSource java library and toolset for disseminating in-memory datasets from a single producer to many consumers for high performance read-only access.
The use of opensource databases has increased steadily in recent years. Past trepidation — about perceived vulnerabilities and performance issues — has faded as decision makers realize what an “opensource database” really is and what it offers. What is an opensource database?
Migrating a proprietary database to opensource is a major decision that can significantly affect your organization. Advantages of migrating to opensource For many reasons mentioned earlier, organizations are increasingly shifting towards opensource databases for their data management needs.
Kubernetes has become the leading container orchestration platform for organizations adopting opensource solutions to manage, scale, and automate application deployment. Kubernetes is an opensource container orchestration platform for managing, automating, and scaling containerized applications. What is Kubernetes?
Here we present a list of 10 open-source Kubernetes tools to make your SRE and Ops teams more effective to achieve their service level objectives. Interactive mode is designed to allow you to discover your cluster's components, and manually break things to see what happens. Kube-ops-view. Telepresence. Amazon S3).
Why haven’t cash-strapped American schools embraced opensource? Simpler UI Testing with CasperJS ( Architects Zone – Architectural Design Patterns & Best Practices). Using MongoDB as a cache store ( Architects Zone – Architectural Design Patterns & Best Practices). Hacker News).
Security analytics solutions are designed to handle modern applications that rely on dynamic code and microservices. This includes everything from multicloud deployments to microservices to Kubernetes instances and the use of opensource software. Infrastructure type In most cases, legacy SIEM tools are on-premises.
PostgreSQL graphical user interface (GUI) tools help these opensource database users to manage, manipulate, and visualize their data. It supports all PostgreSQL operations and features while being free and open-source. pgAdmin Cost: Free (opensource). Let’s start with the first and most popular one.
A data lakehouse addresses these limitations and introduces an entirely new architectural design. This architecture offers rich data management and analytics features (taken from the data warehouse model) on top of low-cost cloud storage systems (which are used by data lakes). Grail is built for such analytics, not storage.
Kubernetes is an opensource container orchestration platform that enables organizations to automatically scale, manage, and deploy containerized applications in distributed environments. Like Kubernetes, OpenShift is an opensource Kubernetes-based container platform. What is Kubernetes? What is OpenShift? Ease of use.
Now let’s look at how we designed the tracing infrastructure that powers Edgar. Troubleshooting a session in Edgar When we started building Edgar four years ago, there were very few open-source distributed tracing systems that satisfied our needs. Storage: don’t break the bank!
Traditionally, though, to gain true business insight, organizations had to make tradeoffs between accessing quality, real-time data and factors such as data storage costs. It should be open by design to accelerate innovation, enable powerful integration with other tools, and purposefully unify data and analytics.
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit was designed to help you adjust your data and add the proper context, which can be helpful in the observability backend. What’s the difference between Fluent Bit and Fluentd?
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. Technology advancements in content creation and consumption have also increased its data footprint.
JSONB storage has some drawbacks vs. traditional columns: PostreSQL does not store column statistics for JSONB columns. JSONB storage results in a larger storage footprint. JSONB storage does not deduplicate the key names in the JSON. If that doesn’t work, the data is moved to out-of-line storage.
During earlier years of my career, I primarily worked as a backend software engineer, designing and building the backend systems that enable big data analytics. I developed many batch and real-time data pipelines using opensource technologies for AOL Advertising and eBay.
Introducing Dynatrace OpenPipeline OpenPipeline is a stream-processing technology that transforms how the Dynatrace platform ingests data from any source, at any scale, and in any format. With OpenPipeline, you can easily collect data from Dynatrace OneAgent®, opensource collectors such as OpenTelemetry, or other third-party tools.
Many AWS services and third party solutions use AWS S3 for log storage. To date, some customers have used opensource or community-backed components to forward logs from S3 to Dynatrace. Logs complement out-of-the-box metrics and enable automated actions for responding to availability, security, and other service events.
They've posted about Anna's new superpowers in Going Fast and Cheap: How We Made Anna Autoscale : Using Anna v0 as an in-memory storage engine, we set out to address the cloud storage problems described above. Each storage server collects statistics about the requests it serves, the data it stores, etc. Related Articles.
From May 17 to May 18, 2021, the Open-Source Engineering team at Dynatrace attended the virtual observability conference, o11yfest. Trace-based sampling can help you save storage costs. This can help you save money in storage costs in the long run. OTel is designed to ensure flexibility and stability.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host. What does observability mean for Kubernetes?
Bitrate versus quality comparison HDR-VMAF is designed to be format-agnostic — it measures the perceptual quality of HDR video signal regardless of its container format, for example, Dolby Vision or HDR10. Yes, we are committed to supporting the open-source community. The graphic below (Fig.
Consider selecting platform-based solutions — whether opensource or from a commercial vendor — that support open ecosystems. Virtualization has revolutionized system administration by making it possible for software to manage systems, storage, and networks. Design, implement, and tune effective SLOs.
EC2 is Amazon’s Infrastructure-as-a-service (IaaS) compute platform designed to handle any workload at scale. With EC2, Amazon manages the basic compute, storage, networking infrastructure and virtualization layer, and leaves the rest for you to manage: OS, middleware, runtime environment, data, and applications. Amazon EC2.
Introduction Percona Operator for MongoDB is an open-source solution designed to streamline and automate database operations within Kubernetes. When running database workloads on Amazon EKS (Elastic Kubernetes Service), backup and restore processes often require access to AWS services like S3 for storage.
This post will look at using The Oversized-Attribute Storage Technique (TOAST) to improve performance and scalability. Therefore, TOAST is a storage technique used in PostgreSQL to handle large data objects such as images, videos, and audio files.
Instead, it seems PostgreSQL Developers are of the opinion that encryption is a storage-level problem and is better solved on the filesystem or block device level. For example, physical backups stored in open S3 buckets are relatively common exposure vectors. It adds defense in depth.
They would love to migrate to an open-source style database like MySQL or PostgresSQL if only such a database could meet the enterprise-grade reliability and performance these high-scale applications required. In this paper, we describe the architecture of Aurora and the design considerations leading to that architecture.
Unbundling the Data Warehouse: The Case for Independent Storage Recording Speaker : Jason Reid (Co-founder & Head of Product at Tabular) Summary : Unbundling a data warehouse means splitting it into constituent and modular components that interact via open standard interfaces.
Compression in any database is necessary as it has many advantages, like storage reduction, data transmission time, etc. Storage reduction alone results in significant cost savings, and we can save more data in the same space. By default, MongoDB provides a snappy block compression method for storage and network communication.
are stored in secure storage layers. Amsterdam is built on top of three storage layers. The first layer, Cassandra , is the source of truth for us. One of the first decisions when integrating with Elasticsearch is designing the indices, their settings and mappings. Net, Ruby, Perl etc.).
Percona is a leading provider of unbiased opensource database solutions that allow organizations to easily, securely, and affordably maintain business agility, minimize risks, and stay competitive. As such, you save on storage space and data transfer in case of cloud setups. It’s time for the release roundup!
Typically, the servers are configured in a primary/replica configuration, with one server designated as the primary server that handles all incoming requests and the others designated as replica servers that monitor the primary and take over its workload if it fails. This flexibility can be crucial in designing a scalable architecture.
The bad On the other hand, Kubernetes is not designed to handle large databases or mainframes. Joe Brockmeier gave a talk on this topic earlier this year at OpenSource Summit North America in Vancouver – “ Are Containers Ready for Production Databases ?” ” This talk covers this topic exactly.
From May 17 to May 18, 2021, the Open-Source Engineering team at Dynatrace attended the virtual observability conference, o11yfest. Trace-based sampling can help you save storage costs. This can help you save money in storage costs in the long run. OTel is designed to ensure flexibility and stability.
It has become a de facto standard for perceptual quality measurements within Netflix and, thanks to its open-source nature , throughout the video industry. For example, when we design a new version of VMAF, we need to effectively roll it out throughout the entire Netflix catalog of movies and TV shows.
This article will explore how they handle data storage and scalability, perform in different scenarios, and, most importantly, how these factors influence your choice. Redis Revealed: An Overview Redis, a renowned open-source, in-memory remote dictionary server, stands out for its diverse data structures and advanced features.
File systems unfit as distributed storage backends: lessons from 10 years of Ceph evolution Aghayev et al., In this case, the assumption that a distributed storage backend should clearly be layered on top of a local file system. What is a distributed storage backend? SOSP’19. This is not surprising in hindsight.
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. Technology advancements in content creation and consumption have also increased its data footprint.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content